
作者|刘东阳、吴梓洋
2018 年底,vivo AI 研究院为了解决统一高性能训练环境、大规模分布式训练、计算资源的高效利用调度等痛点,着手建设 AI 计算平台。经过两年多的持续迭代,平台建设和落地取得了很大进展,成为 vivo AI 领域的核心基础平台。平台从当初服务深度学习训练为主,到现在演进成包含 VTraining、VServing、VContainer 三大模块,对外提供模型训练、模型推理和容器化能力。平台的容器集群有数千个节点,拥有超过数百 PFLOPS 的 GPU 算力。集群里同时运行着数千个训练任务和数百个在线服务。本文是vivo AI 计算平台实战系列文章之一,主要分享了平台在混合云建设方面的实践。
背景
混合云是近年来云原生领域关注的新方向之一,它是指将私有云和公有云服务结合起来使用的解决方案。目前几大公有云厂商都提供了各自的混合云方案,如 AWS 的AWS Outpost、谷歌的 GEC Anthos 和阿里的 ACK 混合云。大部分厂商都是通过使用 Kubernetes 和容器来屏蔽底层基础设施的差异,对上提供统一的服务。AI 计算平台选择建设混合云,主要是基于以下两点原因。
公有云的弹性资源
平台的集群使用公司自建机房内的裸金属服务器,新增资源的采购流程复杂、周期长,无法及时响应业务临时的大量的算力需求,如大规模参数模型的训练和在线服务的节假日活动扩容。同时由于今年服务器供应链形势严峻,网卡、硬盘、GPU 卡等硬件设备都缺货,服务器采购交付存在较大风险。公有云的资源可以按需申请和释放,通过混合云使用公有云资源,能够满足业务的临时算力需求,又能有效降低成本。
公有云的高级特性
公有云有一些高级的特性,比如 AI 高性能存储 CPFS、高性能网络 RDMA、深度学习加速引擎 AIACC,这些方案或特性目前公司私有云尚不具备,而私有化落地的时间和金钱成本都很高,通过混合云可以快速和低成本的使用这些特性。
方案
方案选型
通过前期调研,以下三种方案可以实现混合云的需求:

方案一的实现成本低、不改变当前资源申请流程,可快速落地。业务可以接受小时级的扩容。因此我们选择了方案一。
整体架构
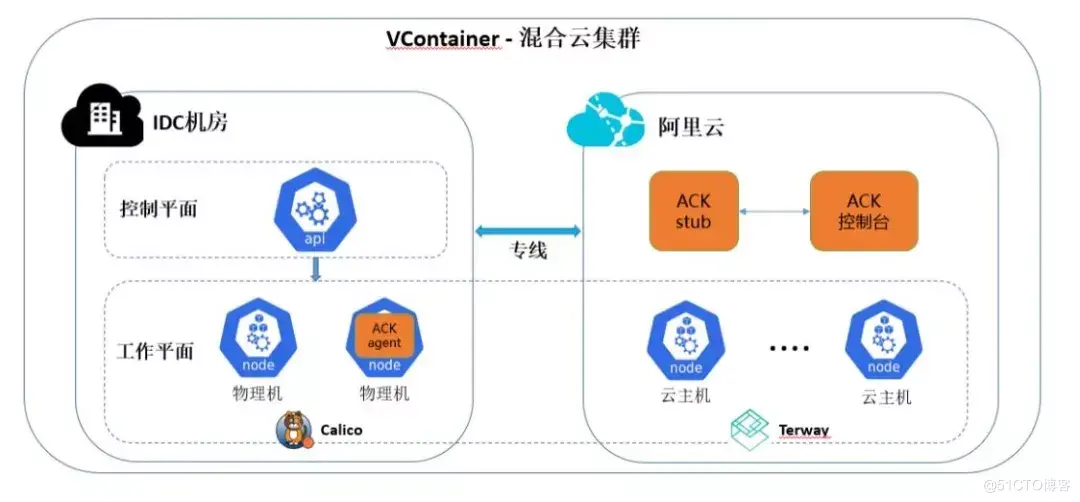
混合云的整体架构如下图所示。K8s 集群的管理平面部署在公司自建机房,工作平面包含了机房的物理机和阿里云的云主机。机房和阿里云间通过专线打通了网络,物理机和云主机可以相互访问。方案对上层平台透明,比如 VTraining 训练平台不需要改动即可使用云主机的算力。
落地实践
注册集群
首先需要将自建的集群注册到阿里云。注意使用的 VPC 的网段不能和集群的 Service CIDR 冲突,否则无法注册。VPC 的虚拟交换机和 Pod 虚拟交换机的 CIDR 也不能和机房内使用的网段重合,否则会有路由冲突。注册成功后,需要部署 ACK Agent。它的作用是主动建立从机房到阿里云的长链接,接收控制台的请求并转发给 apiserver。对于没有专线的环境,此机制可以避免将 apiserver 暴露在公网。控制台到 apiserver 的链路如下:
阿里云 ACK 控制台 <<-->> ACK Stub(部署在阿里云) <<-->> ACK Agent(部署在 K8s) <<-->> K8s apiserver
控制台到集群的请求是安全可控的。Agent 连接 Stub 时,会带上配置的 token 和证书;链接采用了 TLS 1.2 协议,保证数据加密;可以通过 ClusterRole 来配置控制台对 K8s 的访问权限。
容器网络配置
K8s 的容器网络要求 Pod 和 Pod、Pod 和宿主机之间通讯正常,平台采用了 Calico + Terway 的网络方案。机房内的工作节点采用 Calico BGP,Route Reflector 会将 Pod 的路由信息同步给交换机,物理机和云主机都能正常访问 Pod IP。阿里云上的工作节点会采用 Terway 共享网卡模式,Pod 会从 Pod 虚拟交换机配置的网段中分配到 IP,该 IP 在机房内可以访问。平台给云主机打上标签,配置 calico-node 组件的 nodeAffinity,不调度到云主机上;同时配置 Terway 组件的 nodeAffinity,让其只运行在云主机上。这样实现了物理机和云主机使用不同的网络组件。在部署和使用 Terway 中,我们遇到并解决了以下三个问题:
1、terway 容器创建失败,报/opt/cni/bin 目录不存在。
通过修改 terway daemonset 中该路径的 hostPath 的 type,从 Directory 改为 DirectoryOrCreate 可以解决上述问题。
2、业务容器创建失败,报找不到 loopback 插件。
terway 没有像 calico-node 一样在/opt/cni/bin/目录下部署 loopback 插件(创建回环网络接口)。我们给 terway daemonset 添加了 InitContainer 来部署 loopback 插件,解决了问题。
3、业务容器分配的 IP 是属于主机交换机网段。
这是因为在使用中,我们新增了一个可用区,但是没有把可用区的 Pod 虚拟交互机的信息配置给 terway。通过在 terway 配置的 vswitches 字段新增可用区的 Pod 虚拟交换机信息,可以解决问题。
云主机加入集群
将云主机加入集群的流程和物理机基本一致。首先通过公司云平台申请云主机,然后通过 VContainer 的自动化平台将云主机初始化并加到集群中。最后给云主机打上云主机专有的标签。关于自动化平台的介绍,可以参见vivo AI 计算平台云原生自动化实践。
降低专线压力
机房到阿里云的专线是公司所有业务共用的,如果平台占用过多专线带宽,会影响到其他业务的稳定性。在落地时我们发现深度学习训练任务从机房的存储集群拉取数据,确实对专线造成压力,为此平台采取了以下措施:
1、监控云主机的网络使用情况,由网络组协助监控对专线的影响。
2、使用 tc 工具对云主机 eth0 网卡的下行带宽进行限流。
3、支持业务使用云主机的数据盘,将训练数据进行预加载,避免反复从机房拉取数据。
落地效果
数个业务方临时需要大量的算力用于深度学习模型的训练。通过混合云的能力,平台将数十台 GPU 云主机加入到集群,提供给用户在 VTraining 训练平台上使用,及时满足了业务的算力需求。用户的使用体验和之前完全一致。这批资源根据不同业务的情况,使用周期在一个月到数个月。经过估算,使用费用大大低于自行采购物理机的费用,有效降低了成本。
未来展望
混合云的建设和落地取得了阶段性的成果,在未来我们会持续完善功能机制和探索新特性:
支持 AI 在线服务通过混合云能力部署到云主机,满足在线业务临时算力需求。
建立一套简单有效的资源申请、释放、续期的流程机制,提升跨团队的沟通协作效率。
针对云主机的成本、利用率进行度量和考核,促使业务方使用好资源。
将云主机申请、加入集群整个流程自动化,减少人工操作,提高效率。
探索云上的高级特性,提升大规模分布式训练的性能。
致谢
感谢阿里云容器团队的华相、建明、流生等和公司基础平台一部的杨鑫、黄海廷、王伟等对混合云方案的设计和落地过程中提供的大力支持。
作者介绍:
刘东阳,vivo AI 研究院计算平台组的资深工程师,曾就职于金蝶、蚂蚁金服等公司;关注 k8s、容器等云原生技术。
吴梓洋,vivo AI 研究院计算平台组的资深工程师,曾就职于 Oracle、Rancher 等公司;kube-batch, tf-operator 等项目的 contributor;关注云原生、机器学习系统等领域。
文内相关链接:
1)vivo AI 计算平台实战:
https://www.infoq.cn/theme/93
2)AWS Outpost:
https://aws.amazon.com/cn/out...
3)GEC Anthos:
https://cloud.google.com/anthos
4)ACK 混合云:
https://help.aliyun.com/docum...
5)AI 高性能存储CPFS:
https://www.alibabacloud.com/...
6)深度学习加速引擎AIACC:
https://market.aliyun.com/pro...
7)vivo AI 计算平台云原生自动化实践:
https://www.infoq.cn/article/...
点击下方,深入了解阿里 ACK 混合云!
https://help.aliyun.com/docum...










