大家好,我是皮皮。
一、前言
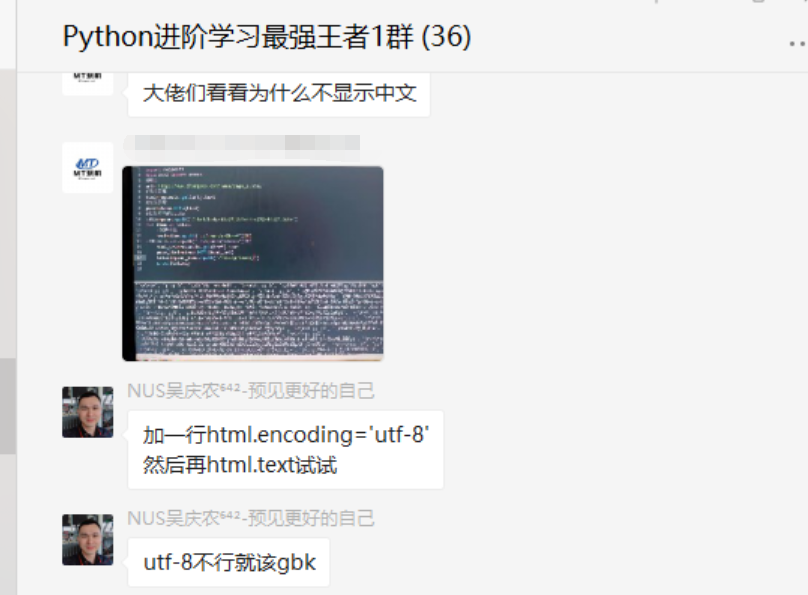
前几天在Python白银交流群【空翼】问了一个Python网络爬虫中文乱码的问题,提问截图如下:
原始代码如下:
import requests
import parsel
url='https://news.p2peye.com/article-514723-1.html'
headers={
'Accept-Language': 'zh-CN,zh;q=0.9',
'Accept': 'application/json, text/javascript, */*; q=0.01',
'Accept-Encoding': 'gzip, deflate, br',
'Cookie': 'A4gK_987c_saltkey=NEkW4yhb; A4gK_987c_lastvisit=1661338603; TYID=enABI2MGEfsNMDZOu4hwAg==; TJID=enABI2MGEfw+MDzqY2WWAg==; Hm_lvt_556481319fcc744485a7d4122cb86ca7=1661342207; Hm_lpvt_556481319fcc744485a7d4122cb86ca7=1661342851; A4gK_987c_sendmail=1; A4gK_987c_lastact=1661343292%09ajax.php%09advertisement',
'Host': 'news.p2peye.com',
'Referer': 'https://news.p2peye.com/article-514723-1.html',
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/101.0.0.0 Safari/537.36',
'X-Requested-With': 'XMLHttpRequest'
}
res=requests.get(url=url, headers=headers)
print(res.status_code)
res.encoding = res.apparent_encoding
# print(res.text)
selector_1 = parsel.Selector(res.text)
title = selector_1.css('#plat-title').get()
print(title)
输出的话,看上去确实有乱码,如下图所示:
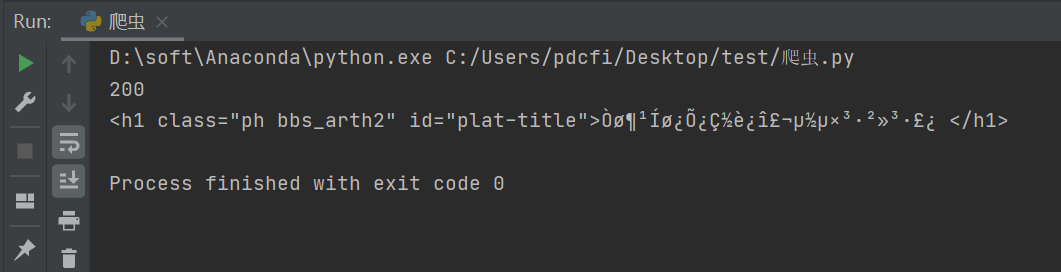
二、实现过程
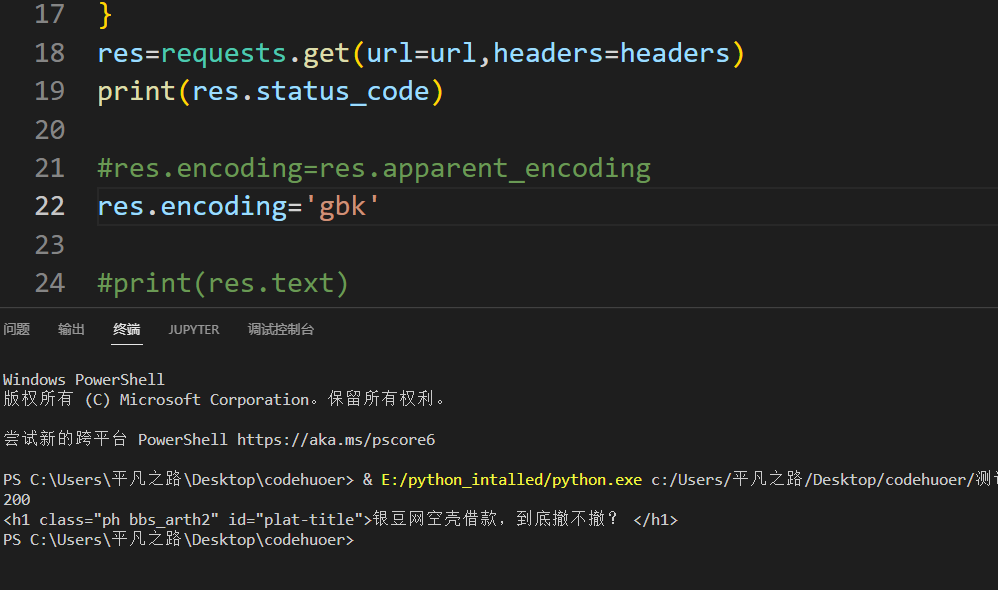
这里【空翼】自己后来稍微调整了下编码,代码如下所示:
res.encoding = 'gbk'
就可以得到预期的效果了
只是有点不太明白,为啥res.encoding=res.apparent_encoding就不好用了,之前都无往不利的。其实这个是让它直接推测编码,肯定没有自己指定的准。
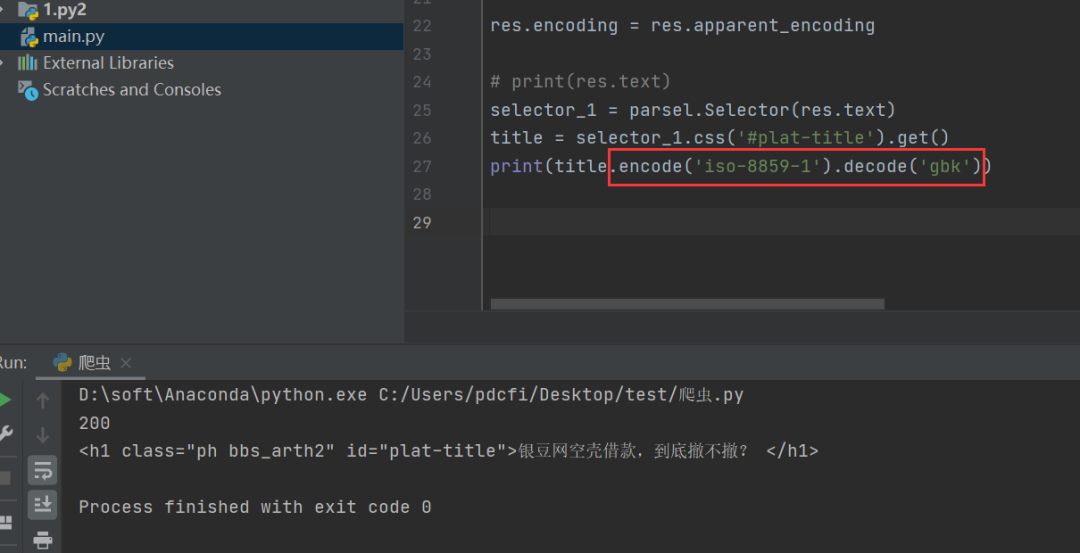
后来【皮皮】也给了一个代码,如下所示:
title.encode('iso-8859-1').decode('gbk')
也是可以得到正常的结果的:
三、总结
大家好,我是皮皮。这篇文章主要盘点了一个Python网络爬虫过程中中文乱码的问题,文中针对该问题给出了具体的解析和代码实现,帮助粉丝顺利解决了问题。
最后感谢粉丝【空翼】提问,感谢【皮皮】、【甯同学】给出的思路和代码解析,感谢【dcpeng】、【冫马讠成】等人参与学习交流。