
什么是webpack
可以引用官网的一幅图解释,我们可以看到webpack,可以分析各个模块的依赖关系,最终打包成我们常见的静态文件,.js 、 .css 、 .jpg 、.png。今天我们先不弄那么复杂,我们就介绍webpack是怎么分析ES6的模块依赖,怎么把ES6的代码转成ES5的。

实现
由于ES6转ES5中需要用到babel,所以要用到一下插件
npm install @babel/core @babel/parser @babel/traverse @babel/preset-env --save-dev
需要的文件
使用webpack肯定少不了原文件,我们会涉及三个需要打包的js文件(entry.js、message.js、name.js)
// entry.js
import message from './message.js';
console.log(message);// message.js
import {name} from './name.js';
export default `hello ${name}!`;// name.js
export const name = 'world';//bundler.js
// 读取文件信息,并获得当前js文件的依赖关系
function createAsset(filename) {//代码略}
// 从入口开始分析所有依赖项,形成依赖图,采用广度遍历
function createGraph(entry) {//代码略}
// 根据生成的依赖关系图,生成浏览器可执行文件
function bundle(graph) {//代码略}entry.js 就是我们的入口文件,文件的依赖关系是,entry.js依赖message.js,message.js依赖name.js。
bundler.js 是我们简易版的webpack
目录结构
- example
- entry.js
- message.js
- name.js
- bundler.js如何分析依赖
webpack分析依赖是从一个入口文件开始分析的,当我们把一个入口的文件路径传入,webpack就会通过这个文件的路径读取文件的信息(读取到的本质其实是字符串),然后把读取到的信息转成AST(抽象语法树),简单点来说呢,就是把一个js文件里面的内容存到某种数据结构里,里面包括了各种信息,其中就有当前模块依赖了哪些模块。我们暂时把通过传文件路径能返回文件信息的这个函数叫 createAsset 。
createAsset返回什么
第一步我们肯定需要先从 entry.js 开始分析,于是就有了如下的代码,我们先不关心createAsset具体代码是怎么实现的,具体代码我会放在最后。
createAsset("./example/entry.js");当执行这句代码,createAsset 会返回下面的数据结构,这里包括了模块的id,文件路径,依赖数组(entry.js依赖了message.js,所以会返回依赖的文件名),code(这个就是entry.js ES6转ES5的代码)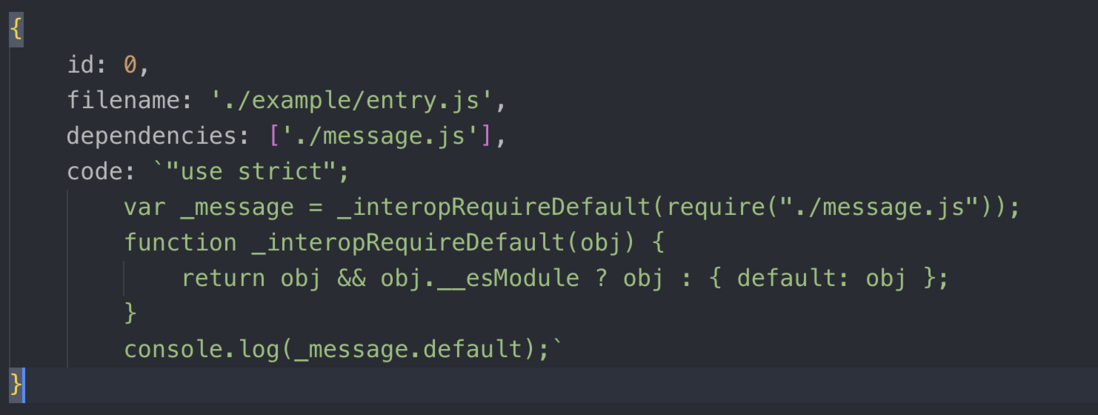
通过 createAsset 我们成功拿到了entry.js的依赖,就是 dependencies 数组。
createGraph返回什么,如何找下一个依赖
我们通过上面可以拿到entry.js依赖的模块,于是我们就可以接着去遍历dependencies 数组,循环调用createAsset这样就可以得到全部模块相互依赖的信息。想得到全部依赖信息需要调用 createGraph 这个一个函数,它会进行广度遍历,最终返回下面的数据

我们可以看到返回的数据,字段之前都和大家解释了,除了 mapping,mapping这个字段是把当前模块依赖的文件名称 和 模块的id 做一个映射,目的是为了更方便查找模块。
bundle返回什么 && 最后步骤
我们现在已经能拿到每个模块之前的依赖关系,我们再通过调用bundle函数,我们就能构造出最后的bundle.js,输出如下图

源码
最后
文章可能有不足的地方,请大家见谅,如果有什么疑问可以下方留言讨论。
如果大家对文字描述还是不太清楚,建议看我下方提供的视频,我就是从视频中学的,这个是在youtube上的视频,大家懂的,有条件的还是建议看一下。?












