
此处是我自己的一个理解,防止以后忘记,如若那个地方理解不对,欢迎指出。
一、背景
在我们写代码的过程中一般会使用 @Autowired 来注入另外的一个对象,但有些时候发生了 循环依赖,但是我们的代码没有报错,这个是什么原因呢?
二、前置知识
1、考虑循环依赖的类型
此处我们考虑 单例 + @Autowired 的循环依赖,不考虑使用构造器注入或原型作用域的Bean的注入。
2、代理对象何时创建

注意:
正常情况下,即没有发生 循环依赖的时候,aop增强是在 bean 初始化完成之后的 BeanPostProcessor#postProcessAfterInitialization方法中,但是如果有循环依赖发生的话,就需要提前,在 getEarlyBeanReference中提前创建代理对象。
3、3级缓存中保存的是什么对象
| 缓存字段名 | 缓存级别 | 数据类型 | 解释 |
|---|---|---|---|
| singletonObjects | 1 | Map<String, Object> | 保存的是完整的Bean,即可以使用的Bean |
| earlySingletonObjects | 2 | Map<String, Object> | 保存的是半成品的Bean,即属性还没有设置,没有完成初始化工作 |
| singletonFactories | 3 | Map<String, ObjectFactory<?>> | 主要是生成Bean,然后放到二级缓存中 |
注意:ObjectFactory#getObject() 每调用一次,都会产生一个新的对象或返回旧对象,取决于是否存在代理等等。
4、从3级缓存中获取对象
org.springframework.beans.factory.support.DefaultSingletonBeanRegistry#getSingleton(java.lang.String, boolean)

5 Spring Bean的简化创建过程
1、实例化一个bean
Object bean = instanceWrapper.getWrappedInstance();实例化Bean 即 new Bean()
2、加入到三级缓存中
addSingletonFactory(beanName, () -> getEarlyBeanReference(beanName, mbd, bean));加入到三级缓存中是有一些条件判断的,一般都会是成立的,此处认为需要加入到三级缓存。
3、设置bean的属性
populateBean(beanName, mbd, instanceWrapper);第一步实例化了bean,但是此时是没有填充需要注入的属性的,通过这一步进行属性的填充。
4、初始化bean
Object exposedObject = initializeBean(beanName, exposedObject, mbd);初始化Bean,执行初始化方法、Aware回调、执行 BeanPostProcessor#postProcessAfterInitialization 方法 (aop的增强是在这个里面实现的)
如果有循环引用的话,则aop的增强需要提前。
5、加入到一级缓存中
addSingleton(......)三、理解
@Component
class A {
@Autowired
private B b;
}
@Transaction (存在代理)
@Component
class B{
@Autowired
private A a;
}1、假设只有singletonObjects和earlySingletonObjects可否完成循环依赖
| 缓存字段名 | 缓存级别 | 数据类型 | 解释 |
|---|---|---|---|
| singletonObjects | 1 | Map<String, Object> | 保存的是完整的Bean,即可以使用的Bean |
| earlySingletonObjects | 2 | Map<String, Object> | 保存的是半成品的Bean,即属性还没有设置,没有完成初始化工作 |
此时需要获取 B的实例,即 getBean("b"),由上方了解到的 Bean 的简化流程可知

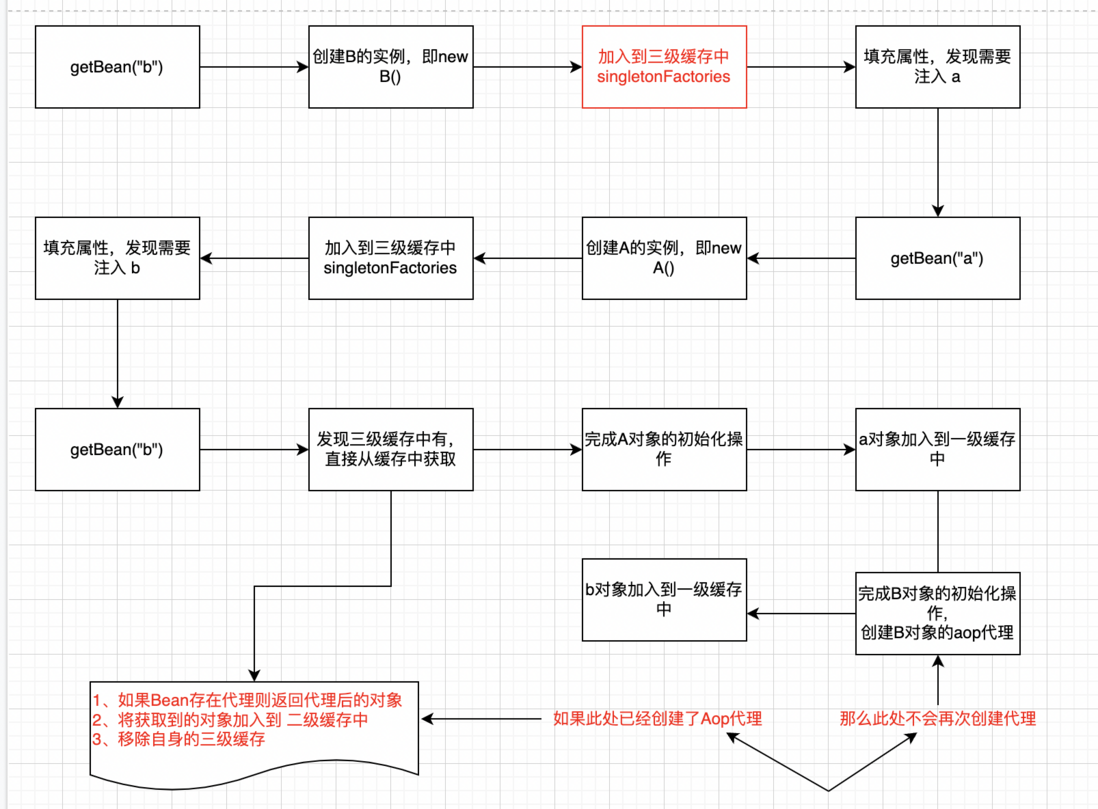
由上图可知,对象存在代理时,2级缓存无法解决问题。因为代理对象是通过BeanPostProcessor来完成,是在设置属性之后才产生的代理对象。
此时可能有人会说,那如果我在构建完B的实例后,就立马进行Aop代理,这样不就解决问题了吗?那假设A和B之间没有发生循环依赖,这样设计会不会不优雅?
2、假设只有singletonObjects和singletonFactories可否完成循环依赖

由图中可知也是不可以实现的。
3、3级缓存如何实现
1、解决代理问题
因为默认情况下,代理是通过BeanPostProcessor来完成,为了解决代理,就需要提前创建代理,那么这个代理的创建就放到3级缓存中来进行创建。
addSingletonFactory(beanName, () -> getEarlyBeanReference(beanName, mbd, bean));getEarlyBeanReference 此方法会返回代理bean
2、解决单例通过第3级缓存多次获取的值不一致
从上图中可知,对象是先从 一级->二级->三级缓存 这样查找,当三级缓存产生了对象后就放入二级缓存中缓存起来,同时删除三级缓存。
3、流程图
四、总结
1、一级缓存 singletonObjects 存放可以使用的单例。
2、二级缓存earlySingletonObjects存放的是早期的Bean,即是半成品,此时还是不可用的。
3、三级缓存singletonFactories 是一个对象工厂,用于创建对象,然后放入到二级缓存中。同时对象如果有Aop代理的话,这个对对象工厂返回的就是代理对象。
那可以在earlySingletonObjects中直接存放创建后的代理对象吗?这样是可以解决问题,但是设计可能就不合理了。因为在Spring中 Aop的代理是在对象完成之后创建的。而且如果没有发生循环依赖的话,有必要提前创建代理对象吗?分成三级缓存,代码结构更清楚,更合理。











