
每年的三四月份是招聘高峰,也常被大家称为金三银四黄金招聘期,这时候上一年的总结做完了,奖金拿到了,职场人开始谋划着年初的找工作大戏,作为高薪行业之一的IT行业,程序员们也开始疯狂的往心仪公司投递简历,今年疫情影响是不是会变成「金四银五」呢?
文章每周持续更新,各位的「三连」是对我最大的肯定。可以微信搜索公众号「 后端技术学堂 」第一时间阅读(一般比博客早更新一到两篇)
作为IT人我们要发挥自己的专业特长,如何从各种招聘网上找到满意的职位?我分析了北京、广州、深圳三个一线城市的C++招聘岗位信息,篇幅限制文中只拿出北京深圳的数据分析,让我们看看C++岗位的招聘现状,以及如何科学提高应聘成功率。
文末分享本次分析的高清图表,需要的同学自取。同时我分享源码用于学习交流,若对其他岗位感兴趣可以自行运行源码分析。
需求分析
通过分析招聘网站发布的招聘数据,得出岗位分布区域、薪资水平、学历要求,岗位需求关键技能、匹配的人才具有哪些特点?从而帮助应聘者提高自身能力,补齐短板,有的放矢的应对校招社招,达成终极目标获得心仪的offer。
软件设计
数据分析是Python的强项,项目用Python实现。软件分为两大模块:数据获取 和 数据分析
详细实现
数据获取
request库构造请求获取数据
cookie = s.cookies
req = requests.post(self.baseurl, headers=self.header, data={'first': True, 'pn': i, 'kd':self.keyword}, params={'px': 'default', 'city': self.city, 'needAddtionalResult': 'false'}, cookies=cookie, timeout=3)
text = req.json()数据csv格式存储
with open(os.path.join(self.path, '招聘_关键词_{}_城市_{}.csv'.format(self.keyword, self.city)), 'w',newline='', encoding='utf-8-sig') as f:
f_csv = csv.DictWriter(f, self.csv_header)
f_csv.writeheader()
f_csv.writerows(data_list)数据分析
字段预处理
df_all.rename({'职位名称': 'position'}, axis=1, inplace=True) #axis=1代表index; axis=0代表column
df_all.rename({'详细链接': 'url'}, axis=1, inplace=True)
df_all.rename({'工作地点': 'region'}, axis=1, inplace=True)
df_all.rename({'薪资': 'salary'}, axis=1, inplace=True)
df_all.rename({'公司名称': 'company'}, axis=1, inplace=True)
df_all.rename({'经验要求': 'experience'}, axis=1, inplace=True)
df_all.rename({'学历': 'edu'}, axis=1, inplace=True)
df_all.rename({'福利': 'welfare'}, axis=1, inplace=True)
df_all.rename({'职位信息': 'detail'}, axis=1, inplace=True)
df_all.drop_duplicates(inplace=True)
df_all.index = range(df_all.shape[0]) 数据处理展示
from pyecharts.charts import Bar
regBar = Bar(init_opts=opts.InitOpts(width='1350px', height='750px'))
regBar.add_xaxis(region.index.tolist())
regBar.add_yaxis("区域", region.values.tolist())
regBar.set_global_opts(title_opts=opts.TitleOpts(title="工作区域分布"),
toolbox_opts=opts.ToolboxOpts(),
visualmap_opts=opts.VisualMapOpts())
from pyecharts.commons.utils import JsCode
shBar = Bar(init_opts=opts.InitOpts(width='1350px', height='750px'))
shBar.add_xaxis(sala_high.index.tolist())
shBar.add_yaxis("区域", sala_high.values.tolist())
shBar.set_series_opts(itemstyle_opts={
"normal": {
"color": JsCode("""new echarts.graphic.LinearGradient(0, 0, 0, 1, [{
offset: 0,
color: 'rgba(0, 244, 255, 1)'
}, {
offset: 1,
color: 'rgba(0, 77, 167, 1)'
}], false)"""),
"barBorderRadius": [30, 30, 30, 30],
"shadowColor": 'rgb(0, 160, 221)',
}})
shBar.set_global_opts(title_opts=opts.TitleOpts(title="最高薪资范围分布"), toolbox_opts=opts.ToolboxOpts())
word.add("", [*zip(key_words.words, key_words.num)],
word_size_range=[20, 200], shape='diamond')
word.set_global_opts(title_opts=opts.TitleOpts(title="岗位技能关键词云图"),
toolbox_opts=opts.ToolboxOpts())数据分析
区域分布
C++岗位区域分布,北京 VS 深圳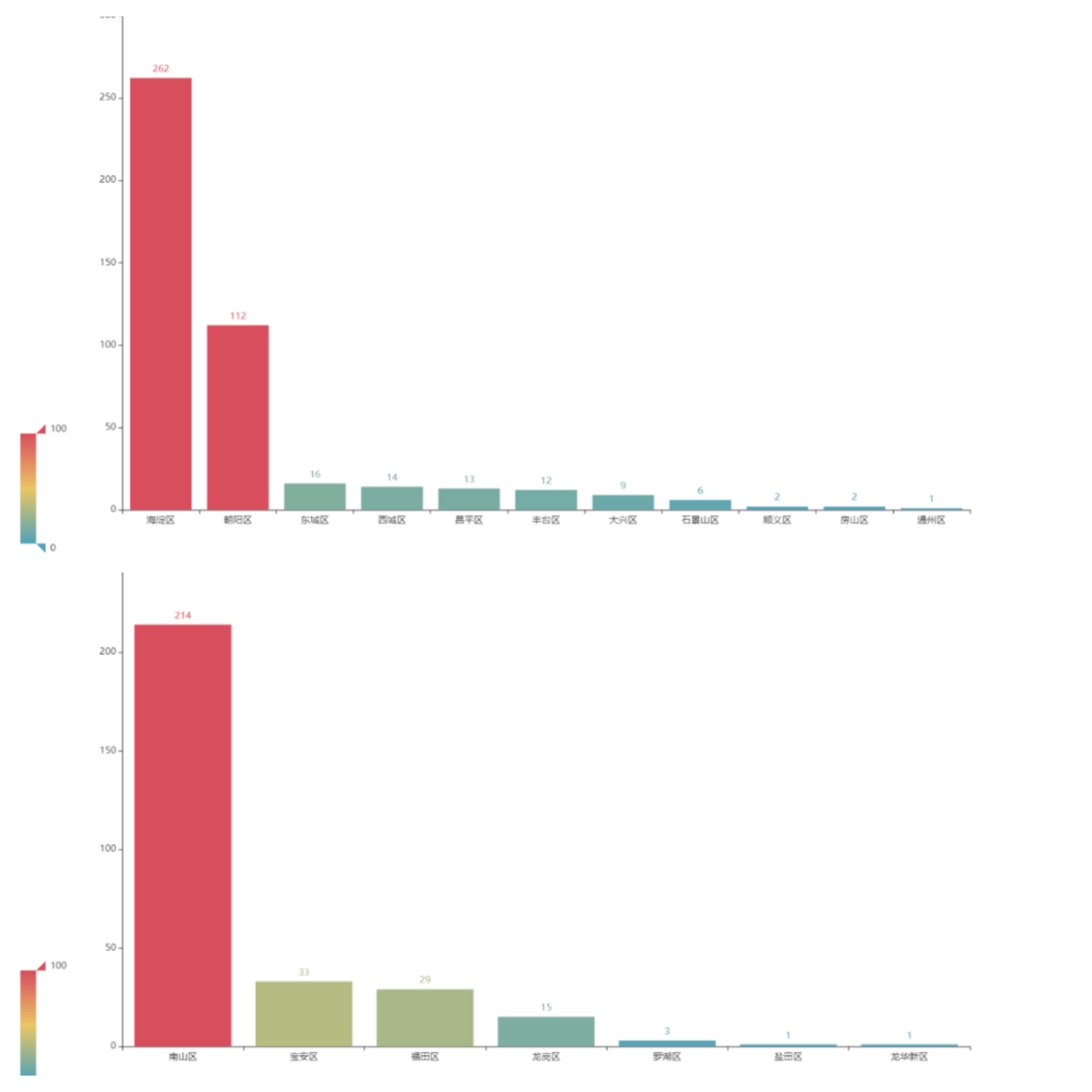
北京的C++岗位数量比深圳更多,首都buff加持,并且集中分布在海淀区和朝阳区这两个区域,中关村位于海淀区,还有位于海淀区西北旺镇的后厂村,腾讯、滴滴、百度、新浪、网易这些互联网巨头扎堆,自然能提供更多的岗位。
深圳的岗位则集中在南山区,猜测鹅厂C++大厂在南山区贡献了重大份额,第二竟然在宝安区。
学历分布
C++岗位学历分布,北京 VS 深圳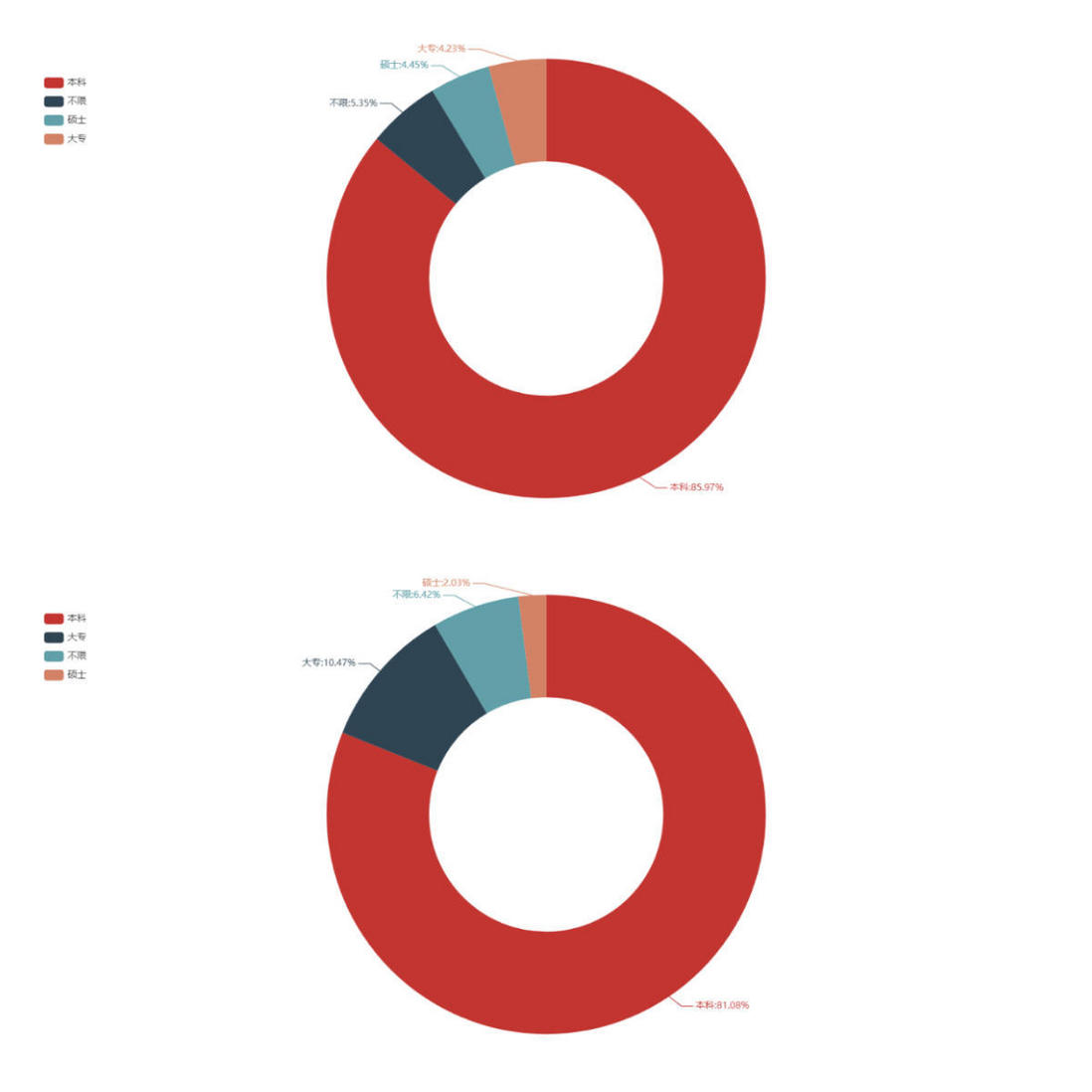
学历上两个城市的本科学历占比都是80%以上,北京岗位需求研究生占比和大专相当。可见大部分岗位本科学历即可胜任,或许能给即将毕业纠结考不考研的你一些参考。
如果你的学历是专科,那么需要加倍的努力,因为留给你的职位并不是很多。同时,从图表数据来看,深圳的岗位对大专生需求10%而对硕士仅占2%,或许去深圳比去北京更加友好,emmm...仅供参考。
薪资分布
C++岗位薪资分布,薪资单位K。
北京最高薪资 VS 最低薪资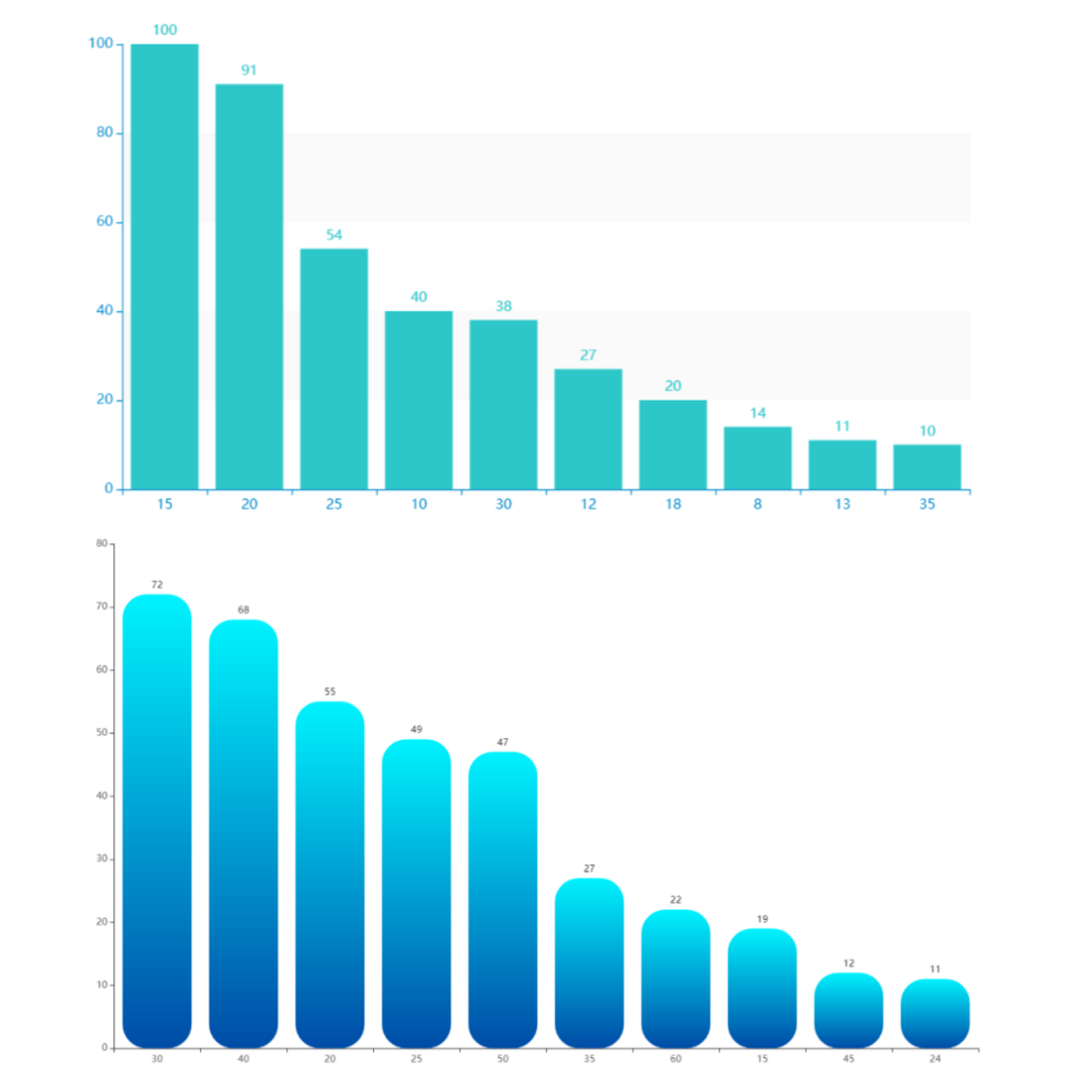
深圳最高薪资 VS 最低薪资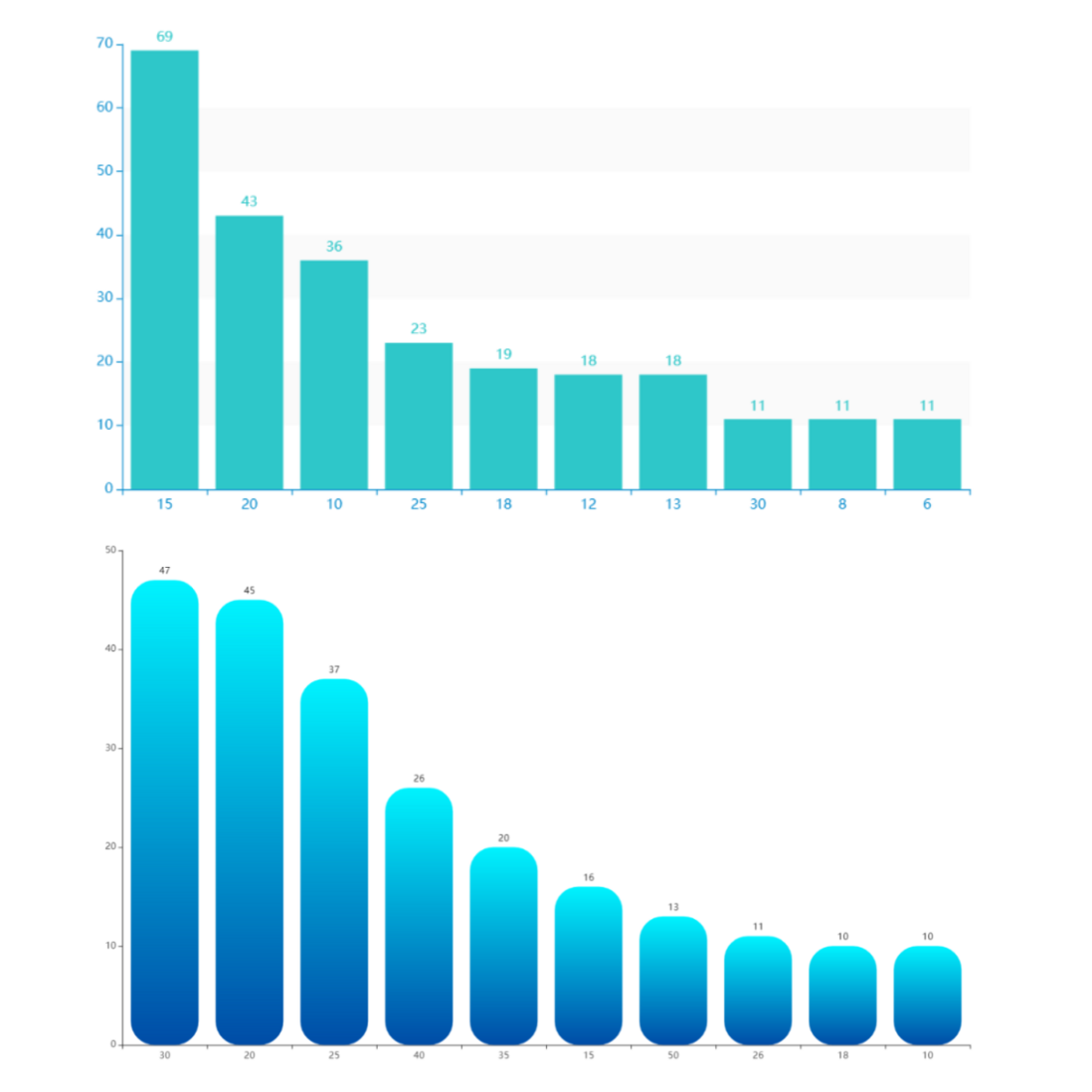
薪资对比没啥好说的,大家看图说话,只想说帝都果然财大气粗。
技能储备
C++岗位关键技能词云,北京 VS 深圳
首先在脱离开发走上管理岗位之前,编程解决问题能力是最重要,可以看到「编程」能力在技能词云中占比最大。
岗位技能词云可以看出,大部分岗位要求较高的「算法、数据结构、Linux、数据库(存储)、多线程(操作系统)」计算机基础素养,所以不管你是在校学生准备校招或者职场老人准备跳槽,都需要储备好这些计算机基础能力。
同时,除去硬核技术要求,岗位对候选人的软实力也有要求,比如更加偏爱具备「团队、协作、学习、沟通」这些能力的候选人,大家在提高技术能力的同时,也要注重这些软实力的培养。
有个有趣的发现,Linux和window下都有C++开发岗位需求,相对而言Linux下C++开发占比更多,词云更大,如果你对这两个平台没有特殊偏爱,那么学Linux下开发大概能加大应聘成功率。
本文程序完整源码以及高清分析图表,在公众号「后端技术学堂」回复 「工作」获取。
原创不易,看到这里动动手指,各位的「三连」是对我持续创作的最大支持。
可以微信搜索公众号「 后端技术学堂 」回复「资料」有我给你准备的各种编程学习资料。文章每周持续更新,我们下期见!










