
为了保证分布式环境下数据强一致性,需要引入分布式事务,而分布式事务由于网络环境的不确定性,天生就很难实现。具体可以见上一篇。
为了保证分布式事务的正确性,目前互联网领域有几种流行的解决方案,但是大部分都没有像XA事务一样形成标准的工业规范。但是这些方案在某些特定的行业或者业务场景下却得到了越来越多的开发者的认可。
避免分布式事务
此方案提倡尽量避免分布式事务,不仅仅是因为分布式事务的难度,更是因为实现分布式事务需要更多的高级人才。如果一个操作设计到事务操作,而这些事务操作可以利用单机事务来解决,推荐首选单机事务。
当然,是否可以避免分布式事务还要看具体业务,在微服务盛行的当下,更多的还要看领域的划分标准,如果两个微服务可以合并成一个微服务,一定程度上在领域划分标准接受范围之内,可以考虑利用合并的方式来避免分布式服务。
举一个很简单的栗子:一个用户基本信息服务和用户资产服务(比如:用户经验值),当用户修改资料的时候给用户加贡献值这个业务场景下,因为涉及到用户资料修改和加贡献值两个不同服务的操作,这个时候就可以考虑将两个服务合并为一个服务,用单机的数据库事务来代替分布式事务。
在可以避免分布式事务的情况下,首选避免分布式事务
二阶段提交
二阶段(2PC)提交方案是基于X/OpenDTP标准规范的,最大的缺点在于它在第一阶段需要锁定资源,会大大降低系统的性能,大型的互联网应用并不推荐这种方案,那种对性能不敏感的企业级应用可以尝试使用。
在asp.net中,微软已经提供了分布式事务的管理类型:TransactionScope,它依赖DTC(Distributed Transaction Coordinator)服务完成事务一致性。当它包裹的代码中如果设计到多个不同物理位置的数据库的时候,它会自动升级为分布式事务,使用起来非常方便。
using (TransactionScope ts = new TransactionScope())
{
数据库A操作();
数据库B操作();
数据库C操作();
ts.Complete();
}TCC
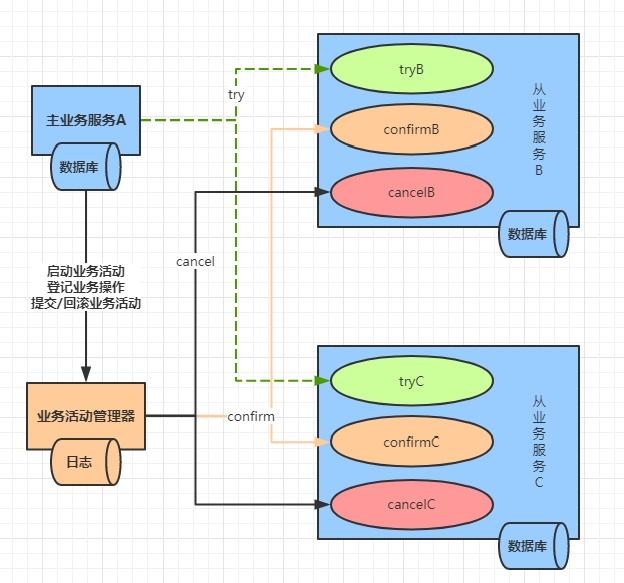
TCC本质上是一种编程模型,它提倡的是补偿操作,所以一般情况下它会有重试机制,它约定参与事务的每个业务方都需要提供三个接口,具体情况请查看上一篇文章。由于TCC的接口重试特性,所以提供的提交和取消接口必须实现幂等性。
2PC主要是针对数据库操作,而TCC主要是针对业务层面来进行操作,这在性能上比2PC要高很多,例如一个提交订单的场景,商品服务需要扣除库存,而订单系统需要创建订单,代码类似以下,请不要纠结命名和参数:
//订单服务
public interface IOrderService
{
//创建一个不可见的订单,返回订单号
Task<string> CreateOrder();
//根据订单号提交订单,使订单可见
Task<int> SubmitOrder(string orderNo);
//根据订单号取消订单
Task<int> CancleOrder(string orderNo);
}
//商品服务
public interface IProductService
{
//根据商品id,锁定库存,返回锁定的id
Task<int> LockProductStock(int productId);
//根据锁定的库存id,提交事务,扣除商品库存
Task<int> SubmitLockStock(int lockId);
//根据锁定的库存id,取消事务,商品库存回滚
Task<int> CancleLockStock(int lockId);
}其实TCC实现过程中,还有很多细节。比如:当提交事务阶段,有一个节点由于网络原因或者down机提交失败,该怎么办呢?这个时候我们要在本地引入本地消息机制,或者叫做业务活动管理器,把每个业务参与分布式事务的每个操作都记录下来,当某个过程的某个节点操作失败,无论是自动发起重试,还是手动重试都可以达到最终数据的一致性。
基于消息的事务
基于消息的分布式事务实现的是最终一致性,它是基于BASE理论的一个解决方案,最早由eBay提出并实施,它采用了消息队列来辅助实现事务控制流程,核心思想是将需要分布式处理的任务通过MQ分发给每个业务去异步执行,如果任务失败,则可以发起系统自动重试或者人工重试的纠正流程。
还是以上边的创建订单和扣减库存为栗子:
- 首先调用订单服务的创建订单接口创建订单,如果创建成功,则发送需要扣减库存的消息(也可以看做创建订单成功的消息)到MQ。
- 商品服务监听扣减库存消息队列,如果收到扣减库存消息,则执行扣减库存操作,如果操作成功,则回复MQ删除该消息。如果没有操作成功,则准备接收同样消息的下次投递。
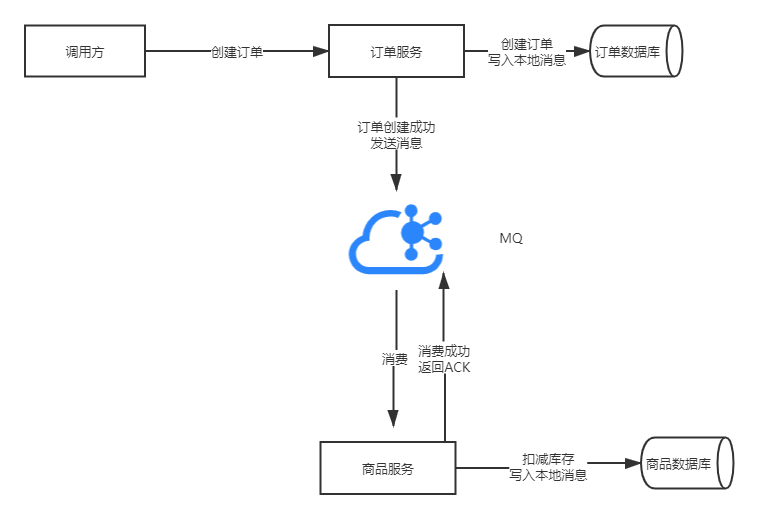
这个流程看似很完美,其实有很多漏洞。
- 创建订单是第一步操作,可以看做是单纯的单机操作,这个并没有问题,但是接着发送MQ消息这一步需要和创建订单保证事务性,因为会发生创建订单成功,发送mq消息失败的情况。如果不能用技术手段来保证这两步的事务,也可以采用引入本地消息的方案,在创建订单的时候,用订单数据库来保证订单创建成功和创建订单消息表的一致性。然后发送mq成功之后,修改订单消息表的状态为发送成功,如果发送mq消息失败,则启用另外一个线程或者进程进行重试。
- 商品服务扣减库存类似,扣减库存这个操作和回复mq消息这两个操作也可以利用本地消息表的方式来解决一致性问题。当收到扣减库存消息的时候,扣减库存和添加消息成功处理记录可以利用数据库的事务来保证一致性,如果回复消息队列ack失败,就算是有重复消息,也可以根据本地的消费消息表来过滤重复消息
基于消息的分布式解决方案还有一个劣势,如果一个事务的业务参与方非常多,消息的发送可能会非常复杂,需要非常谨慎的设计。比如以上订单的栗子,现在引入了优惠券服务,在订单创建成功,需要同时扣减库存和优惠券,如果优惠券扣减失败,需要同时回滚库存和取消订单,这也只是三个业务参与方,如果是四个,五个呢?当然这在业务中也许并不常见。
基于消息的分布式事务解决方案,由于引入了重试机制,也需要接口在实现的时候支持幂等性。但从开发的角度,这种方案要比tcc以及2pc都要有优势,把每个系统之间的耦合度降到了最低,而且每个业务方的实现技术可以非常灵活,无论是采用java还是c#活着是golang都无所谓。
当然市面上基于消息的分布式解决方案各式各样,但总体来说都属于最终一致性方案。如果引入消息通道MQ的不稳定性,那还需要在各个业务方引入查询机制来确保消息的ack机制。举个栗子:如果商品服务已经正常扣减库存,由于mq问题,始终不能正常ack。这个时候订单服务是否会主动查询商品服务是否已经正常扣库存?这个时候整个架构可能就非现在这个样子了,这个要是扯起来又是一篇文章了
更多精彩文章










