
背景介绍
性能测试是 SDK 发版的重要依据,VolcRTC 的业务方对于性能指标都比较重视,对于 RTC 准入有明确的准入标准。因此我们建立了线下的性能自动化测试系统,测试过程中我们发现 VolcRTC 的内存占用较高存在较大的优化空间。
某个版本 1v1 语音通话 VolcRTC 1v1 语音通话内存占用:
| 占用的资源 | Memory[MB] |
|---|---|
| Android 高端机 | 17.87 |
| Android 中端机 | 17.58 |
| Android 低端机 | 16.06 |
| iOS 高端机 | 6.19 |
| iOS 中端机 | 6.52 |
| iOS 低端机 | 5.73 |
为了实现内存优化,首先需要理清两个问题:
- 哪些模块消耗多少内存?
- 如何优化?
内存组成
在回答以上两个问题之前,我们先了解下内存的主要组成部分有哪些。
在 Android 系统上,内存主要分为:
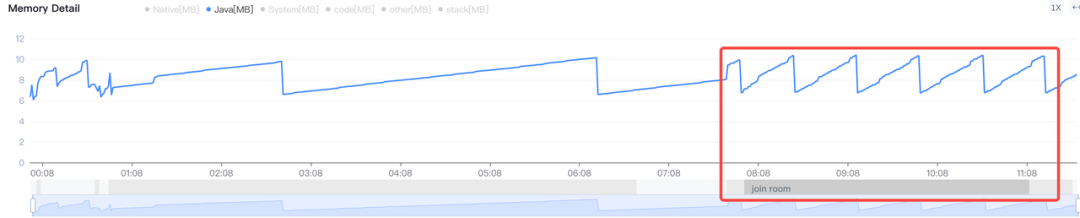
下图红框部分为 VolcRTC 通话过程
- Java Heap, 从 Java 代码分配的对象;通话过程中 Java 内存的分布曲线,主要呈锯齿状的周期性变化。结合 VolcRTC 的业务特点,可以知道这部分内存主要在 JNI 调用时分配临时对象,累计到一定程度后由系统的 GC 机制回收。
- Native Heap, 从 C 或 C++ 代码分配的对象。这部分为 VolcRTC 主要内存占用。
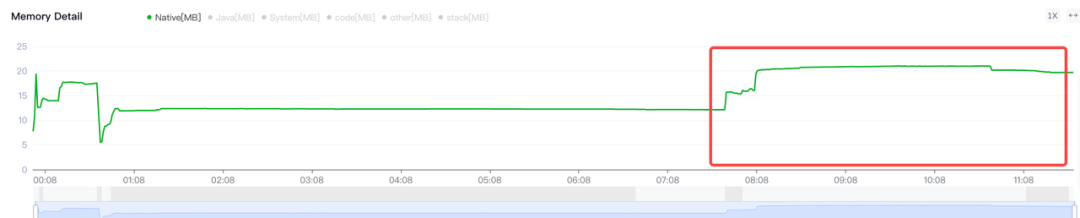
- Code, 用于处理代码和资源(如 dex 字节码、经过优化或编译的 dex 代码、.so 库和字体)的内存。VolcRTC 库所占用内存,但不等于动态库的包大小,主要原因在于代码段是按需分页加载的,所以部分代码不会被加载到内存。VolcRTC 是一个动态库,因此 Code 的内存也是在通话过程中主要部分。

优化方向
根据上文的初步分析,可以确定 VolcRTC 的内存占用主要分布在 Native Heap 与 Code 段。因此我们明确大体的优化方向为:
- Native 内存优化
- 动态库包体优化
内存归因分析
哪些模块如何消耗多少内存?
- 内存分配堆栈信息
- 按模块归因
Heapprofd 实现原理
- hook malloc、calloc、realloc、free 等内存分配相关的函数
- 拷贝寄存器与栈内存,存储到共享内存,用于栈回溯
- 根据堆栈信息聚类生成 Trace 文件

模块归因

VolcRTC 归因规则
VolcRTC 主要分为底层媒体引擎与上层 RTC SDK 两部分。媒体引擎的整体架构是以流水线(Pipeline)的形式组成的,每个 Pipeline 由实现不同功能的 Node 构成。我们可以根据相关的命名空间进行堆栈过滤,再根据软件分层架构进行层层归因。
纯系统堆栈
VolcRTC 引起的系统堆栈内存分配,堆栈不包含 VolcRTC 符号信息,无法按前述规则归类,需要归类到由 VolcRTC 引起的系统内存分配。
归因示例
内存分配堆栈特征一般为栈底为__pthread_start(void*),栈顶为内存存分配方法,中间为 VolcRTC 堆栈信息。根据堆栈信息,结合归因规则然后层层向上归因,形成一个树状的结构,准确分析每一个 Pipeline、每一个 Node、每一个类型的对象所占用的内存大小。

碰到的问题
Hook malloc 得到的内存大小与 Native Heap 大小不一致
malloc 向内存分配器申请的内存,跟程序运行时传入的 size 一致。
内存分配器向操作系统申请的内存按页分配,一般每页为 4K,Native Heap 统计的是这部分的内存大小。
由于内存分配器的需要反复分配与释放内存,不可避免的产生内存空隙也就是内存碎片,另外内存分配器会缓存一部分小内存块以提升内存分配效率。

语音通话内存分析
通过性能自动化测试工具,生成分析报告。基于分析报告我们绘制语音通话内存全景图,再通过全景图识别出内存占用较高的几个模块,指引优化方向。
内存优化
编译优化
包大小会直接影响到内存大小,因此优化包大小也可以有效减少内存大小。通过打开 LTO、Oz 等编译选项,结合线下性能自动化测试评估是否对性能指标有负面影响来决定需要开启的编译优化选项。编译优化后 Android 端动态库包体减少了 900KB,通话过程内存优化 850KB 左右。
按需动态分配
VolcRTC 作为一个通用功能的 SDK,对于每个特定场景会有很多冗余逻辑与功能,这些逻辑与功能都存在较多的预分配内存。对应的优化方案是:
- 合理代码组件化,将不同的功能抽象成组件做到灵活组装与按需加载,如:AI 降噪功能内置的数据和模型会占用较大的内存空间。
- 内存尽量按需动态分配。如:AEC 回声消除在不同场景下有不同的算法,需要根据实际的场景按需分配内存,减少过多的内存预分配。
设置合理的缓存大小
不合理的缓存大小也会引起不必要的内存浪费。通过内存的归因分析,结合不同场景的业务特性,设置更加合理的缓存大小,可以减少内存占用。例如:RTC 采用了 RTP 包重传机制来对抗网络丢包,为了实现重传机制,需要缓存一定数量的包,缓存的数量需要跟进帧长、实时性要求等业务特性来设置合理的值。
合理的算法和数据结构设计
合理的算法和数据结构也可以有效降低内存。在保证计算准确性的前提下,通过减少数据值域范围,使用内存空间占用更小的数据类型来实现算法,比如统计与时间相关的数据时使用相对时间而非绝对时间、空间音频算法通过定点化使用short类型代替浮点型数据。另外数据结构设计时需要考虑内存对齐问题。
优化效果
1v1 语音通话
| 占用的资源 | 优化前 Memory[MB] | 优化后 Memory[MB] |
|---|---|---|
| Android 高端机 | 17.87 | 13.59 |
| Android 中端机 | 17.58 | 13.98 |
| Android 低端机 | 16.06 | 12.93 |
| iOS 高端机 | 6.19 | 3.87 |
| iOS 中端机 | 6.52 | 3.84 |
| iOS 低端机 | 5.73 | 3.14 |
本次内存优化,我们探索了 RTC 场景下性能归因分析驱动性能优化的实践。可以总结出以下经验:
- 构造稳定的测试用例
- 建立性能折损的数据归因模型
- 基于归因模型识别热点性能问题,形成优化方案
- 从 1v1 通话开始分析,然后逐步到多人、百人千人。
加入我们
字节跳动 RTC 团队,作为全球领先的音视频团队,我们致力于提供全球互联网范围内高品质、低延时的实时音视频通信能力,目前已经支撑了抖音、TikTok、清北网校、字节系游戏,视频会议等多个场景的应用,服务 10 亿用户,用户遍布全球每一个角落。
我们是 RTC Client(客户端)部门, 致力于维护多个功能/平台的 SDK 和最佳实践,满足灵活性和易用性的要求,在音视频通信、行业应用、信令等方向形成自己的特色,期待优秀同学的加入
扫码查看 RTC Client 在招岗位

参考文档:
Heapprofd: https://perfetto.dev/docs/desig









