不久前,我与几位朋友围坐一堂,畅聊起关于大模型的市场动态。当我们的话题转向大模型价格时,我深感这是一个特别适合用来阐述差异化定价的案例。于是,我研究了相关的数据和信息。现在,我将这些发现与大家分享,一同探讨这其中的奥妙。
01“ 百模大战”,你降价、我免费
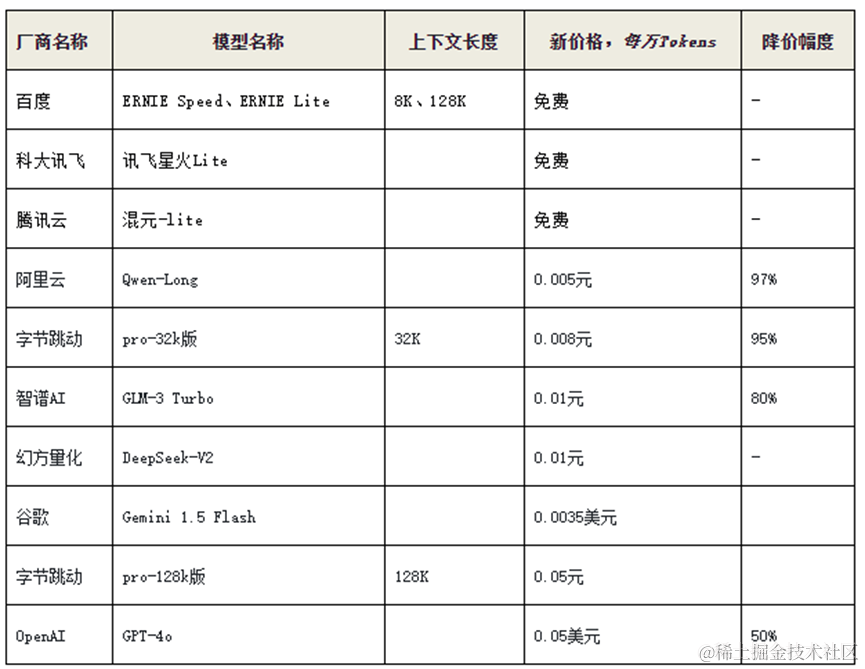
近期,国内外多个大模型相继宣布降价,掀起“价格战”。不到一个月时间,国内大模型每万Tokens从“以分计价”,到“以厘计价”,最终跨入“免费”时代。**
第一波次:以分计价
5月6日,幻方量化宣布旗下深度求索(DeepSeek)正式开源第二代MoE模型DeepSeek-V2,调用价格为输入0.01元/万Tokens、输出0.02元/万Tokens,约为GPT-4-Turbo的百分之一。
5月11日,智谱大模型跟进,官宣新价格:入门级产品GLM-3 Turbo模型调用价格从0.05元/万Tokens降至0.01元/万Tokens,降幅高达80%。**
第二波次:以厘计价
5月15日,字节跳动宣布豆包大模型正式开启对外服务,其中豆包通用模型pro-32k版在企业市场的推理输入价格仅为0.008元/万tokens。
5月21日,阿里云宣布其通义千问GPT-4级主力模型Qwen-Long的API输入价格从0.2元/万tokens降至0.005元/万tokens,降幅达97%。降价后,通义千问的价格仅为GPT-4价格的1/400。第三波次:“免费”
5月21日,百度宣布其文心大模型的两大主力模型ERNIE Speed、ERNIE Lite全面免费。第二日,科大讯飞宣布其讯飞星火Lite API永久免费开放。腾讯云公布了主力模型混元-lite的全新方案,提升了API输入输出总长度,并且也改为全面免费。
02 差异化定价,买的没有卖的精
本轮降价潮使得大模型更加亲民,让更多的企业和开发者能够使用大模型进行创新,有利于加速大模型的商业化进程,并促进各大模型厂商向更加多元的盈利模式转型,进入探索实现商业闭环路径的全新阶段。但不可忽视的是,大幅度的降价也使得企业短期的盈利空间受到挤压,那么,大模型企业采取了什么手段加以化解呢?
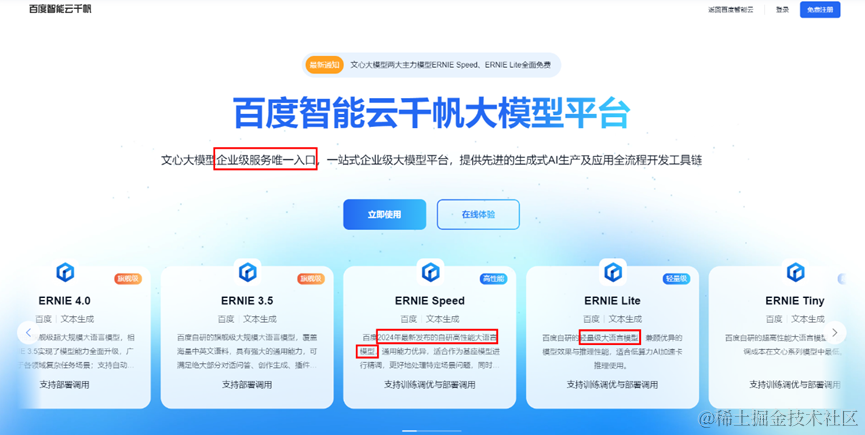
仔细分析各大模型厂商的完整价格表,不难发现,在不同情况下,各厂商都应用了差异化的定价策略,即面向不同的使用场景,包装出不同性能规格的大模型产品,并制定不同的价格,形成相互协同的大模型产品矩阵。无论是错位竞争还是直面价格战,差异化定价策略的应用,都给大模型厂商带来了极强的灵活性,也为更强产品的推出保留了溢价的机会。
1️ ⃣ 降价幅度最高的产品都是其偏轻量化的模型版本。**
大模型厂商的低价、免费,更像是引诱老鼠出洞的奶酪。降价幅度最高的产品都是其偏轻量化的模型版本,而且仅适用于使用频次不高、推理量不大、任务简单的中小企业、开发者短期使用。这样,低价、免费这些“互联网”手段成为了大模型厂商的获客策略,通过降低尝鲜和试验门槛,来提高市场渗透率,扩大用户规模,再将用户向更高阶的付费版本转化。
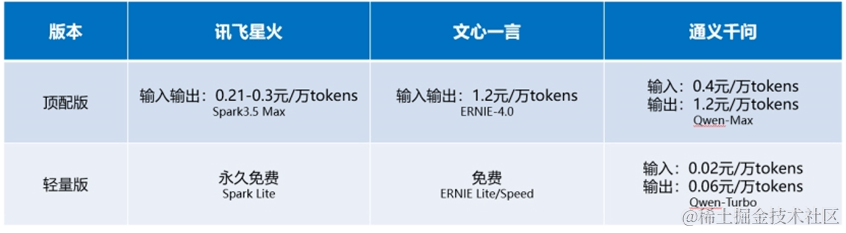
此外,从降价幅度看,input降价幅度普遍高于output降价幅度,进一步刺激模型输入调用量大于输出调用量场景的使用量,如用户结合长文本(论文、文档等)对大模型提问。这样的降价策略,有利于厂商获得更多的数据来优化模型效果,提升整体的产品竞争力。
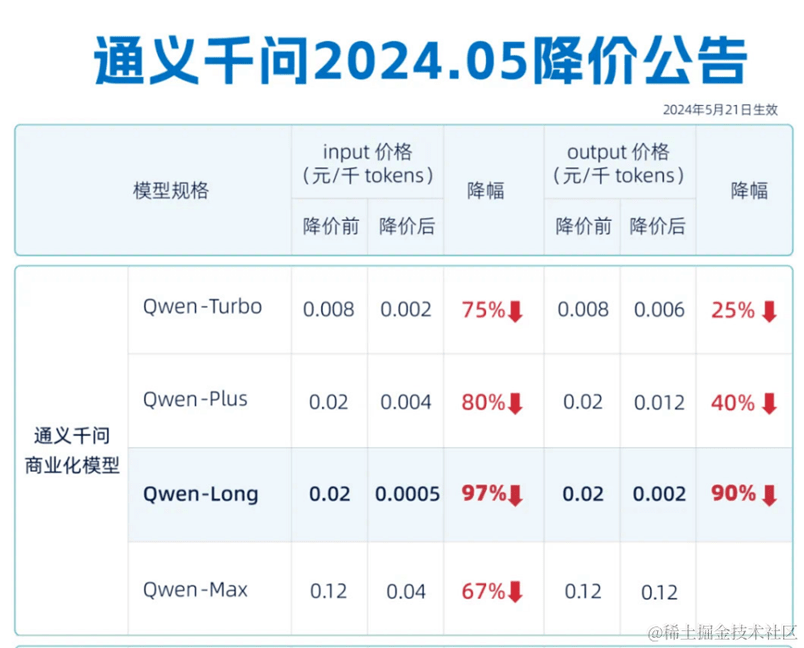
2️ ⃣ 基本能力免费,对于其他企业做不了的、性能更高的、个性化的定制服务收费。
5月22日,科大讯飞在投资者关系活动上表示,讯飞星火API免费的相关商业逻辑在讯飞人工智能开放平台已经有成功实践和验证:讯飞开放平台面向全行业提供人工智能能力和整体解决方案,以免费+扶持的策略为主,基本能力免费,对于其他企业做不了的、性能更高的、个性化的定制服务收费。

3️ ⃣ 领先者同时扮演“颠覆者”和“防御者”,多个梯队参与竞争。**
大模型领域加速迭代,领先厂商必须同时扮演“颠覆者”和“防御者” ,至少两个梯队来参与竞争。一个梯队负责进攻,孵化全新的模型和产品,追逐技术上的颠覆式创新;另一个梯队负责防御,通过低价、生态等守住现有业务和用户,抵御对手的袭击。例如,GPT-4o虽然免费,但免费版本只提供有限的次数,而天花板级别的语音交互能力又带来了极强的付费潜力。而未来推出的GPT-5可能具备超级智能能力。谷歌也采用类似的策略,更低价格、更低成本的模型,与高性能的付费模型,以及庞大的软硬件生态来让AI落地,共同构成商业版图。
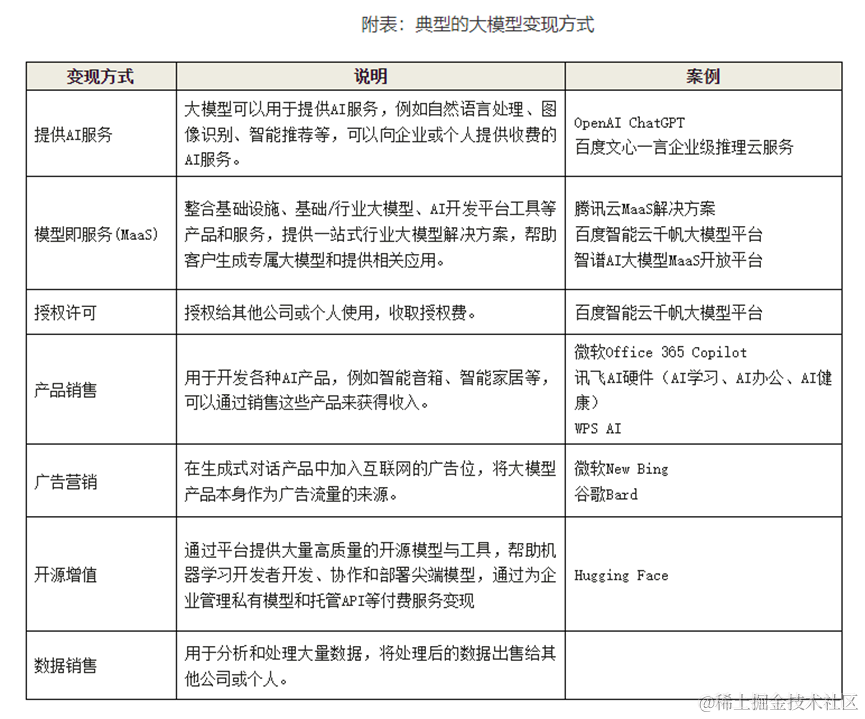
当前,大模型行业整体尚处于商业模式探索阶段,各大厂商的商业化路径不尽相同(可参考文末附表:典型的大模型变现方式),但普遍基于大模型能力或应用场景差异,将大模型产品系列化、矩阵化,并根据市场竞争需要,采用差异化定价策略制定和调整价格。
需要注意的是,有效的差异化定价需要以精准的市场细分和客户画像为基础,实质是为不同需求偏好和支付意愿的客户提供能够充分平衡其需求和支付能力的产品。单纯的“向下定价”、鱼目混珠的大模型产品,最终将被市场所淘汰。
最后引用网友的一句话来结尾, “百模大战,看token价格,也要看模型的质量,如果质量不行,价格再低也是无徒劳” 。
附表: