
转:
在做某个管理项目时,被要求实现一套流程管理,比如请假的申请审批流程等,在参考了很多资料,并和同事讨论后,得到了一个自主实现的流程管理。
以下提供我的设计思路,知道了思路,实现起来就简单很多了。
首先我设计了5个类来实现流程的自主设置,主要是对流程的定义和流程流转。
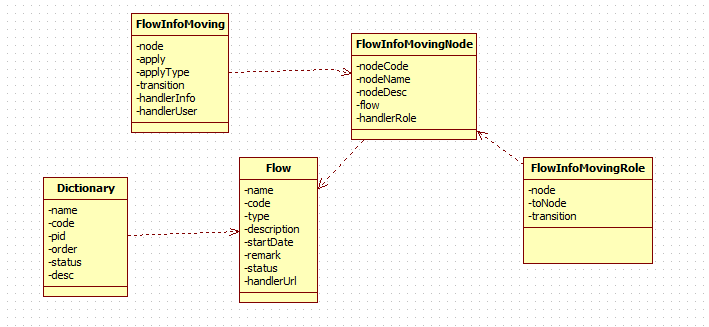
注:这是设计的图,并不是实现
Dictionary:数据字典,不多说,流程类型存在这里面
Flow:流程,即流程的定义,其中包括流程名称,描述,类型,启用时间,备注等;目前是通过判断某个类别的流程启用时间来进行判断当前流程是否启用的。
一个类别只启用一个流程。所以只需要通过流程类别即可确定流程,并不要特定的状态字段。
FlowInfoMovingNode:流程节点,在分析流程流转的时候,我们发现,流转一步就相当于从一个节点跳到另一个节点,所以我们设计这个流程节点类来表示每一步。
其中包括,所属流程,节点名称,节点描述,监听权限。
解释下监听权限是什么. 由于我们做的大部分是审核的流程,所以每个节点都需要有个审核的过程才进入下一个节点,所以我们要这个handlerRole属性来确定这个节点究竟是什么权限来审核。我们也知道,审核一般是某个人审核,这个我们后面说。这里是规定某个权限,即可以审核这个节点的权限。
FlowInfoMovingRole:流程流转规则,为了解决从节点出来的各个分支,我们设计了这个流转规则,本来其实可以一起放到FlowInfoMovingNode中,但这样话无论从数据上 还是管理上来说都不如加流转规则方便清楚。FlowInfoMovingRole主要用来确定流转规则,比如某个节点通过了应该去哪个节点,某个节点没通过应该去哪个节点,这样无论是分支还是单支还是循环都可以通过相同的方式来进行设置。transition为变换规则,参照shiro验证权限的方式,我们也使用纯字符串格式来进行判断变换规则。
FlowInfoMoving:流程流转信息,这里是每一步流转信息的存放,基本在进行流程流转的过程中,都是通过此类,其中包括:所属节点(得到所属节点同时也就得到所属流 程),申请源(因为我们不知道申请源是什么,我们只是管流程是怎么运转的,其申请源跟我们没有任何关系,我们保存申请源的唯一标识,若是想在审核的过程中进行查看申请源信息,则可以请求在Flow中监听的Url(handlerUrl),来进行查看,我会把申请源的唯一标识当做参数传递到Url中)。
由于这个是操作最频繁的,所以我来具体解释下这个类。
以下为本人具体实现的类设计,属性字段均有注释进行解释:


/**
* 流程流转信息
* @author lichao *
*/ @Entity @Table(name = FlowInfoMoving.TABLE_NAME) public class FlowInfoMoving extends BaseAuditEntity { private static final long serialVersionUID = 1L; public static final String TABLE_NAME = "t_flowInfoMoving"; // 流程节点,标识此流转信息是流转到了哪个节点 @ManyToOne(fetch = FetchType.EAGER) @JoinColumn(name = "node_id",nullable = true) private FlowInfoMovingNode node; // 申请源,具体申请信息的唯一标识 @Column private Long applyId; // 申请人,具体申请信息的申请人 @ManyToOne(fetch = FetchType.EAGER) @JoinColumn(name = "applyuser_id",nullable = false) private User applyUser; // 申请信息,具体申请信息的简要概述,由申请提供 @Column(length = 50) @Size(max = 50) private String discription; // 申请类别,即申请的流程的类型 @ManyToOne(fetch = FetchType.EAGER) @JoinColumn(name = "flowtype_id",nullable = false) private Dictionary applyType; // 变换的结果,即审核通过未通过等条件,此条件同FlowInfoMovingRole种的transition, // 但有一些区别,因为有添加待审核,已结束等其他信息条件 @Column(length = 50) @Size(max = 50) private String transition; // 处理信息,即审核信息,由审核人添加 @Column(length = 100) @Size(max = 100) private String handlerInfo; // 处理人,即此流转应该由谁来申请,由FlowInfoMovingNode中的handlerRole来进行筛选, //并由上一个节点的处理人来进行选择具体审核人。 @ManyToOne(fetch = FetchType.EAGER) @JoinColumn(name = "handleruser_id",nullable = false) private User handlerUser; // 此流转信息的状态,用于查询,0未审核,1已审核,2本申请已经结束 @Column() private int status; //getter...and setter.... }

这样整个流程定义就结束了,我们可以自由设置流程的流程规则,来设置流程的流转方式。这样无论任何复杂的流程都可以进行自定义,并且可以随意的修改。
这样设计的结果首先是可以任意的自定义流程,其次是申请源不需要去管流程的流转了,只需要提交一份申请,其他的事情均由流程进行操作实现。
那么我们来看看一个流程是如何进行运转的。
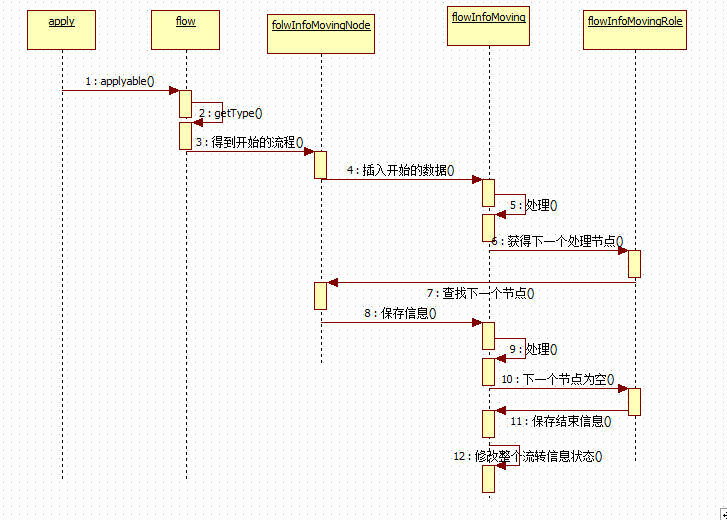
1.首先通过一个接口来传递具体的一些申请信息。
2.通过接口中的getType()来确定是哪个流程
3.查询到开始的流程节点。
4.将开始的信息保存到流转信息中,并等待处理
5.由审核人处理,指定下一个审核人
6.通过处理结果来获得下一个流程节点
7.查找下一个节点
8.将这次的处理信息和下一个节点的信息保存到流转信息中,并等待处理
9.由审核人处理,这样一直循环知道流程结束
10.通过审核信息查找的下一个节点为null,则表示此流程已经结束,
11.将结束的信息保存到流程流转信息中
12.将整个流程流转的状态改为已结束。
首先是Applyable是怎么设计的:其实一个接口,用于提供一些申请的信息

public interface Applyable {
// 得到申请的id,与类别进行联合查询,用于确定具体是哪个流程 Long getId(); // 得到申请的类别,用于确定具体是哪类流程 String getApplyType(); // 得到变换条件,用于确定申请后的第一个步骤 String getTransition(); // 得到此次申请的描述 String getDiscription(); // 得到审批人,即第一个步骤由谁审批 User getHandlerUser(); }

然后是主要的控制流程流转和申请的接口


/**
*
*@Description:处理流程业务的Service
*@Author:lichao
*@Since:Oct 10, 201412:02:39 PM
*/
public interface FlowMainService { /** * *@Description: 用于申请 *@Author: lichao *@Since: Oct 10, 20143:19:07 PM *@param applyable *@return * @throws Exception */ public void applyFlow(Applyable applyable) throws Exception; /** * *@Description: 查找当前所处的流转信息 *@Author: medees *@Since: Oct 13, 20148:56:00 AM *@param applyid 申请源 *@param applytype 申请类别 *@return */ public FlowInfoMoving findNowMoving(Long applyid,Dictionary applyType); /** * *@Description: 查找某一流程下的所有走过的流程 按创建时间升序排序 *@Author: lichao *@Since: Oct 13, 20141:46:54 PM *@param applyid 申请源 *@param applytype 申请类别 *@return */ public List<FlowInfoMoving> findAllMoving(Long applyid,Dictionary applyType); /** * *@Description: 获取所有变换条件 *@Author: lichao *@Since: Oct 13, 20144:27:41 PM *@param nodeid 所处节点的id *@return */ public List<String> findNextTransition(Long nodeid); /** * *@Description: 得到此节点可以审核的所有用户 *@Author: lichao *@Since: Oct 14, 201410:22:50 AM *@param nodeid 节点id *@param applyid 申请源 *@param applyUserId 申请人id *@return */ public List<User> findNextAppUser(Long nodeid,String transition,Long applyUserId); /** * *@Description: 分页查询自己所审批的流程 *@Author: lichao *@Since: Oct 14, 20141:39:50 PM *@return */ public Page<FlowInfoMoving> findMyMoving(Pageable pageRequest); /** * *@Description: 进行审核的方法 *@Author: lichao *@Since: Oct 15, 20142:11:18 PM *@param moving * @throws Exception 如果审核出错则抛出异常 */ public boolean approval(FlowInfoMoving moving) throws Exception; /** * *@Description: 查找一个流程的所有流转 *@Author: lichao *@Since: Oct 16, 201411:04:03 AM *@param applyid *@param applytype *@return */ public Page<FlowInfoMoving> findAllMoving(Long applyid,Long applytype,Pageable Pageable); /** * *@Description: 重新申请 *@Author: lichao *@Since: Oct 17, 20141:43:03 PM *@return */ public void resetApply(Applyable applyable) throws Exception; /** * *@Description: 是否需要重新申请 *@Author: lichao *@Since: Oct 17, 20141:43:03 PM *@return */ public boolean isNeedReset(Long applyid,Dictionary dic); }

申请源只要调用此接口中的applyFlow进行申请即可。
具体实现就不在提供了!










