
流的简介
官方解释,Stream是Java8的一大亮点,它与java.io包里的InputStream和OutputStream是完全不同的概念。它也不同于StAX对XML的解析的Stream,也不是Amazon Kinesis对大数据实时处理的Stream。它是对集合对象功能的增强,她专注于对集合对象进行各种非常便利、高效的聚合操作(aggregate operation)或者大批量数据操作(bulk data operation)。Stream API借助于同样新出现的Lambda表达式,极大的提高编程效率和程序可读性。同时,它提供串行和并行两种模式进行汇聚操作,并发模式能够充分利用多核处理器的优势,使用fork/join并行方式来拆分任务和加速处理过程,所以可以说,Java中出现的java.util.stream是一个函数式语言+多核时代综合影响的产物。
Stream不是集合元素,它不是数据结构并不保存数据,它是有关算法和计算的,它更像一个高级版本的Iterator。可以说流是一种处理数据的更好方式,正如之前我们处理集合数据,总是显示地一个个遍历元素并对其执行某些操作,使用流我们只要给出需要对其包含的元素执行什么操作即可,Stream会隐式地在内部进行遍历,做出相应的数据转换。
Stream就如同给一个迭代器(iterator),单向,不可往复,数据只能遍历一遍,遍历过一次后即用尽了。
流式操作节省了代码量,使用了更优雅的代码;其次对于空间复杂度,若入参是流的形式,就可以大大节省内存占用,意思就是之前的数据是全部放入内存中再进行处理,非常巨大的集合类会占用大量的内存,而现在可以来一个数据就用定义好的处理方式处理一个,因为Stream的元素是在访问的时候才被计算出来(延迟计算),而不用占用大量的内存。而且对于时间复杂度,Stream依赖于Java7中引入的Fork/Join框架就可以实现并行,来拆分任务和加速处理过程。
流和集合的差:
1)流并不存储其元素
2)流的操作不会修改其数据源
3)流的操作是尽可能惰性执行的。意味着直至需要其结果时,操作才被运行。可以操作无限流
4)对于大量数据可以不存入内存, 流式的处理
5)可以很方便的并行处理
总结一下,对集合进行代码简洁、清晰但不一定易读(可读性其实不高,而且不方便debug,不抛出checked异常) ,不一定高效(效率其实有时不如for‘循环)的转换、过滤、聚合等操作,属于“高级版”的迭代器,而和迭代器不同的是,Stream可以并行化操作,迭代器只能命令式地、串行化操作,注意并发功能慎用,对于IO密集型操作,都使用默认的线程池会导致其他任务被阻塞。
生成流
1、流的产生常用方式有以下几种:
java.util.stream.Stream 8
static
产生一个元素为给定值的流
static
产生一个不包含任何元素的流
static
产生一个无限流,它的值是通过反复调用函数而构建的
static
产生一个无限流,它的元素包含种子,在种子上调用f产生的值,在前一个元素上调用f产生的值等等
示例:
1、采用静态的Stream.of方法将一个数组转为流
Stream
2、创建不包含任何元素的流
Stream
3、创建无限流
例如获取常量值得流:
Stream
或随机数的值
Stream
产生无限序列,例如0 1 2 3.....
Stream
可能会有疑问,流不会无限创建下去吗? 流是延迟计算的,这里只是定义,在使用流的时候进行规范就可以了
//对刚刚定义的流进行输出 限制为10位
randoms .limit(10).forEach(System.out::print);
4、集合产生
List
Stream
5、数组产生
String[] s = new String[]{"1","2","3","4"};
Stream
5、 由文件生成流
try {
Stream
} catch (IOException e) {
e.printStackTrace();
}
2、使用流的时候,通常包括三个节本步骤:
获取一个数据源(source)->数转换->执行操作获取想要的结果,每次转换原有Stream对象不变,返回一个新的Strean对象(可以有多次转换),这就允许对其操作像链条一样排列,变成一个管道。
流的操作类型分为两种:
Intermediate(中间操作):一个流可以后面跟随零个或多个intermediate操作。其目的主要是打开流,做出某种程度的数据映射/过滤,然后返回一个新的流,交给下一个操作使用。这类操作是惰性化的(lazy),就是说,仅仅调用到这类方法,并没有真正开始流的遍历。
Terminal(终端操作):一个流只能有一个terminal操作,当这个操作执行后,流就被使用“光”了,无法再被操作。所以这必定是流的最后一个操作。Terminal操作的执行,才会真正开始流的遍历,并且会生成一个结果,或者一个side effect。
操作
类型
返回值
使用的函数接口或者类型
filter
中间操作
Stream
Predicate
distinct
中间操作,有状态,无边界
Stream
skip
中间操作,有状态,无边界
Stream
long
limit
中间操作,有状态,无边界
Stream
long
map
中间操作
Stream
Function<T,R>
flatMap
中间操作
Stream
Function<T,Stream
sorted
中间操作,有状态,无边界
Stream
Comparator
anyMatch
终端操作
boolean
Predicate
noneMatch
终端操作
boolean
Predicate
allMatch
终端操作
boolean
Predicate
findAny
终端操作
Optional
findFirst
终端操作
Optional
forEach/forEachOrdered()
终端操作
void
Consumer
collect
终端操作
R
Collector<T,A,R>
reduce
终端操作,有状态,有边界
Optional
BinaryOperator
count
终端操作
long
max/min
终端操作
Optional
Comparator
从以上的介绍可以看出,流的简单使用就是对一串输入数的处理,本来非常复杂的处理可以使用简洁的代码实现。
使用方法
以上已经说明流就是定义一些想要执行的操作,以及结束操作,那如何定义呢,简单来说就是方法连点。
1)流的构造和转换
2)流的操作
3)终端操作
以下主要介绍常用操作,其他的可看这里:
sort 排序 [倒序 .reversed()]
filter 过滤
distinct 去重
limit(n) 流取前n个
skip(n) 忽略前n个
forEach 遍历
peek 对流进行任何操作,但不影响流
1、map/flatMap
map:作用是把input Stream 的每一个元素映射成output Stream的另外一个元素,即输入集合返回新集合。
List<String> dishName = menu.stream() .map(Dish::getName).collect(toList());
flatMap:扁平化
//现在有个数组,要统计出里面单词的不重复字母
String[] words = {"Hello", "world"};
List<String> word2 = Arrays.stream(words)
.map(word->word.split(""))
.flatMap(Arrays::stream)
.distinct()
.collect(toList());
word2.forEach(System.out::print);//HelowrdD
2、filter
filter对原始Stream进行过滤(其实就是if为true),被留下来的元素生成一个姓的Stream。
Integer[] sixNums = {1, 2, 3, 4, 5, 6};
Integer[] evens = Stream.of(sixNums).filter(n -> n%2 == 0).toArray(Integer[]::new);
List<String> output = reader.lines().flatMap(line -> Stream.of(line.split(REGEXP))).filter(word -> word.length() > 0).collect(Collectors.toList());
3、forEach
可以对stream的每个元素进行一个处理,没有返回值,可接收一个lambda表达式
// stream
roster.stream().filter(p -> p.getGender() == Person.Sex.MALE)
.forEach(p -> System.out.println(p.getName()));
// foreach
for (Person p : roster) {
if (p.getGender() == Person.Sex.MALE) {
System.out.println(p.getName());
}
但一般认为,forEach 和常规 for 循环的差异不涉及到性能,它们仅仅是函数式风格与传统 Java 风格的差别。对一个人员集合遍历,找出男性并打印姓名。可以看出来,forEach 是为 Lambda 而设计的,保持了最紧凑的风格。而且 Lambda 表达式本身是可以重用的,非常方便。当需要为多核系统优化时,可以 parallelStream().forEach(),只是此时原有元素的次序没法保证,并行的情况下将改变串行时操作的行为,此时 forEach 本身的实现不需要调整,而 Java8 以前的 for 循环 code 可能需要加入额外的多线程逻辑。
另外一点需要注意,forEach 是 terminal 操作,因此它执行后,Stream 的元素就被“消费”掉了,你无法对一个 Stream 进行两次 terminal 运算。下面的代码是错误的:
stream.forEach(element -> doOneThing(element));
stream.forEach(element -> doAnotherThing(element));//执行完第一行代码,再次执行会报异常(java.lang.IllegalStateException: stream has already been operated upon or closed)
4、peek
对每个元素执行操作并返回一个新的 Stream,相反,就是这里可以随意对流做操作, 但返回的结果还是原来的流.
Stream.of("one", "two", "three", "four")
.filter(e -> e.length() > 3)
.peek(e -> System.out.println("Filtered value:"+ e))
.map(String::toUpperCase)
.peek(e -> System.out.println("Mapped value : " + e))
.collect(Collectors.toList());
5、检查anyMatch\allMatch\noneMatch
//至少一个匹配
boolean isVegetarian = peopleList.stream().anyMatch(People::isaBoolean);
//都匹配
boolean isHealthy = peopleList.stream().allMatch(d->d.getSalary()<1000);
//都不匹配
boolean isNotHealthy = peopleList.stream().noneMatch(d->d.getSalary()<1000);
6、查找:findAny\findFirst
//找到任何一个就立即返回
Optional<People> dish = peopleList.stream().findAny();
//找到第一个元素
Optional<People> dishone = peopleList.stream().findFirst();
7、聚合操作reduce(归约)
归约就是把一个流归成一个值,比如把一个List的结果计算为一个值,术语叫折叠。
Stream.reduce,返回单个的结果值, 并且reduce操作每处理一个元素总是创建一个新值。常用的方法有average,sum,min,max,count,使用reduce方法都可实现。
T reduce(T identity, BinaryOperator
identity:它允许用户提供一个循环计算的初始值。accumulator:计算的列假期,其方法签名为apply(T t, U u),在该reduce方法中,第一个参数t为上次函数计算的返回值,第二个参数u为Stream中的元素,这个函数把这两个值计算apply,得到的和会被赋值给下次执行这个方法的第一个参数。
int value = Stream.of(1,2,3,4).reduce(100, (sum, item) -> sum + item);
//方法引用
int value = Stream.of(1,2,3,4).reduce(100, Integer::sum);
//最大最小值
Optional<Integer> max = numbers.stream().reduce(Integer::max);
Optional<Integer> min = numbers.stream().reduce(Integer::min);
该例子汇总100即为计算初始值, 每次相加计算值都会传递到下一次计算的第一个参数。
reduce的其他两个重载方法:
Optional
U reduce(U identity, BiFunction<U,? super T,U> accumulator, BinaryOperator combiner):与前面两个参数的reduce方法几乎一致,你只要注意到BinaryOperator其实实现了BiFunction和BinaryOperator两个接口
更多内容可查看:Java 8系列之Stream中万能的reduce
8、结果收集collect
方法字典:
//计数
collect(counting())
//求和
collect(summingInt()/summingDouble()/summingLong())
//平均
collect(avgeragingInt())
//最值
collect(maxBy()/minBy())
//分组
collect(groupingBy())
collect的基础方法:
supplier:一个能创造目标类型实例的档蛋。accumulator:一个将当前元素添加到目标中的方法。combiner:一个将中间状态的多个结果整合到一起的方法(并发的时候会用到)。
List<Integer> result = Stream.of(1,2,3,4).collect(() -> new ArrayList<>(), (arrayList, item) -> arrayList.add(item), (one, two) -> one.addAll(two));
//或使用方法引用
result = Stream.of(1,2,3,4).collect(ArrayList::new, List::add, List::addAll);
这个例子是将结果收集到一个新的list中:
第一个方法生成一个新的ArrayList;
第二个方法中第一个参数是前面生成的ArrayList对象,第二个参数是stream中包含的元素,方法体就是把stream中的元素加入ArrayList对象中。第二个方法被反复调用直到原stream的元素被消费完毕;
第三个方法也是接受两个参数,这两个都是ArrayList类型的,方法体就是把第二个ArrayList全部加入到第一个中;
collect重载方法:
<R,A> R collect(Collector<? super T,A,R> collector)
Collector其实是上面supplier、accumulator、combiner的聚合体。那么上面代码就变成:
List
更多内容可查看:Java 8系列之Stream的强大工具Collector
8.1、结果集收集到map中
People people1 = new People(10, "zhangsan", 5000, true);
People people2 = new People(11, "lisi", 6000, true);
People people3 = new People(8, "zhangsan", 4000, false);
People people4 = new People(9, "wangwu", 6000, true);
List<People> peopleList =Arrays.asList(people1,people2,people3,people4);
//假设你有一个Stream<Person>对象,希望将其中元素收集到一个map中,这样就可以根据他的名称来查找对应年龄,例如:
Map<String, Integer> peopleResult = peopleList.stream().collect(HashMap::new,(map, p)->map.put(p.name,p.age),Map::putAll);
/*使用Collectors.toMap形式, 第三个参数(exsit, newv) -> newv)为键值重复处理策略,若不传入第三个参数,当有相同键时,会抛出一个IlleageStateException*/
peopleResult = Arrays.asList(people1,people2,people3,people4).stream().collect(Collectors.toMap(p -> p.name, p -> p.age, (exsit, newv) -> newv));
//会抛出一个IlleageStateException
peopleResult = Arrays.asList(people1,people2,people3,people4).stream().collect(Collectors.toMap(p -> p.name, p -> p.age));
9、分组分片
对具有相同特性的值进行分组是一个很常见的任务,Collectors提供了一个groupingBy方法:
<T,K,A,D> Collector<T,?,Map<K,D>> groupingBy(Function<? super T,? extends K> classifier, Collector<? super T,A,D> downstream)
classifier:一个获取Stream元素中主键方法。downstream:一个操作对应分组后的结果的方法。
例如要根据年龄来分组:
Map<Integer, List<Person>> peropleByAge =
peopleList.filter(p -> p.age > 12) .collect(Collectors.groupingBy(p -> p.age, Collectors.toList()));
若我想要根据年龄分组,年龄对应的键值List存储的为People的姓名:
Map<Integer, List<String>> peropleByAge =peopleList.collect(Collectors.groupingBy( p -> p.age, Collectors.mapping((Person p) -> p.name, Collectors.toList())));
mapping即为对各组进行投影操作,和Stream的map方法基本一致。
若要根据姓名分组,获取每个姓名下人的年龄总和:
Map<String, Integer> sumAgeByName = peopleList.collect(
Collectors.groupingBy(
p -> p.name, Collectors.reducing(0, (Person p) -> p.age, Integer::sum)));
/* 或者使用summingInt方法 */
sumAgeByName = peopleList.collect(
Collectors.groupingBy(
p -> p.name, Collectors.summingInt((Person p) -> p.age)));
另外Collectors中还存在一个类似groupingBy的方法:partitioningBy,它们的区别是partitioningBy为键值为Boolean类型的groupingBy,这种情况下它比groupingBy更有效率
Map<Boolean, List<People>> children = Stream.generate(new PersonSupplier()).
limit(100).
collect(Collectors.partitioningBy(p -> p.getAge() < 18));
System.out.println("Children number: " + children.get(true).size());
System.out.println("Adult number: " + children.get(false).size());
Map<Boolean, List<People>> map = peopleList.stream()
.collect(partitioningBy(People::aBoolean));
10、join和统计功能
Java8中新增了一个StringJoiner,Collectors的join功能合它基本一样。用于将流中字符串拼接并收集起来。
String names = peopleList.map(p->p.name).collect(Collectors.joining(","));
Collectors分别提供了求平均值averaging、总数counting、最小值minBy、最大值maxBy、求和suming等操作。若希望将流中结果聚合为一个总和、平均值、最大值、最小值,那么Collectors.summarizing(Int/Long/Double)就准备好了,它可以一次性获取前面的所有结果,其返回值为(Int/Long/Double)SummaryStatistics。
DoubleSummaryStatistics dss = peopleList.collect(Collectors.summarizingDouble((Person p)->p.age));
double average=dss.getAverage();
double max=dss.getMax();
double min=dss.getMin();
double sum=dss.getSum();
double count=dss.getCount();
更多内容查看:Java 8系列之重构和定制收集器
11、sorted
对 Stream 的排序通过 sorted 进行,它比数组的排序更强之处在于你可以首先对 Stream 进行各类 map、filter、limit、skip 甚至 distinct 来减少元素数量后,再排序,这能帮助程序明显缩短执行时间。
List<Person> persons = new ArrayList();
for (int i = 1; i <= 5; i++) {
Person person = new Person(i, "name" + i);
persons.add(person);
}
List<Person> personList2 = persons.stream().limit(2).sorted((p1, p2) -> p1.getName().compareTo(p2.getName())).collect(Collectors.toList());
System.out.println(personList2);
并发流及其效率
1、并发的演变
Java并行的API演变历程基本如下:
1)1.0-1.4 中的 java.lang.Thread
2)5.0 中的 java.util.concurrent
3)6.0 中的 Phasers 等
4)7.0 中的 Fork/Join 框架
5)8.0 中的 Lambda
2、生成并发流
1、生成并发流的方式:
Collection.parallelStream();
Stream.parallel();
示例:
List<Integer> list1 = new ArrayList<>();
List<Integer> list2 = new ArrayList<>();
List<Integer> list3 = new ArrayList<>();
List<Integer> listx = new ArrayList<>();
Lock lock = new ReentrantLock();
long startTime=System.currentTimeMillis(); //获取开始时间
IntStream.range(0, 10000).forEach(list1::add);
long endTime=System.currentTimeMillis(); //获取结束时间
System.out.println("串行执行程序运行时间: "+(endTime-startTime)+"ms");
startTime=System.currentTimeMillis(); //获取开始时间
IntStream.range(0, 10000).parallel().forEach(list2::add);
endTime=System.currentTimeMillis(); //获取结束时间
System.out.println("并行执行程序运行时间: "+(endTime-startTime)+"ms");
startTime=System.currentTimeMillis(); //获取开始时间
IntStream.range(0, 10000).parallel().forEachOrdered(listx::add);
endTime=System.currentTimeMillis(); //获取结束时间
System.out.println("并行执行forEachOrdered方法程序运行时间: "+(endTime-startTime)+"ms");
startTime=System.currentTimeMillis(); //获取开始时间
IntStream.range(0, 10000).parallel().forEach(i -> {
lock.lock();
try {
list3.add(i);
} finally {
lock.unlock();
}
});
endTime=System.currentTimeMillis(); //获取结束时间
System.out.println("加锁并行执行程序运行时间: "+(endTime-startTime)+"ms");
System.out.println("串行执行的大小:" + list1.size());
System.out.println("并行执行的大小:" + list2.size());
System.out.println("并行执行forEachOrdered:" + listx.size());
System.out.println("加锁并行执行的大小:" + list3.size());
执行结果:
//计时实际都是分开测试的 可能因为缓存的原因 如果一起运行之后运行的代码块比第一次运行的要块10倍左右
串行执行程序运行时间: 65ms
并行执行程序运行时间: 58ms
并行执行forEachOrdered方法程序运行时间: 76ms
加锁并行执行程序运行时间: 76ms
串行执行的大小:10000
并行执行的大小:5709
并行执行forEachOrdered:10000
加锁并行执行的大小:10000
每次执行结果中并行执行的大小不一致,而串行和加锁后的结果一直都是正确结果。显而易见,stream.parallel.forEach()中执行的操作并非线程安全 如果需要保证原来的顺序可以使用forEachOrdered()方法 或者直接加锁。
2、并发性能测试
long startTime = System.currentTimeMillis(); //获取开始时间
for (int i = 0; i < 100000; i++) {
lists.add(i);
}
long endTime = System.currentTimeMillis(); //获取结束时间
System.out.println("for循环执行程序运行时间: " + (endTime - startTime) + "ms");//8ms
List<Integer> list1 = new ArrayList<>();
List<Integer> list2 = new ArrayList<>();
List<Integer> lists = new ArrayList<>();
for (int i = 0; i < 10000000; i++) {
lists.add(i);
}
long startTime1 = System.currentTimeMillis(); //获取开始时间
for (Integer list : lists) {
list1.add(list);
}
long endTime1 = System.currentTimeMillis(); //获取结束时间
System.out.println("for执行程序运行时间: " + (endTime1 - startTime1) + "ms");//219ms
long startTimex = System.currentTimeMillis(); //获取开始时间
lists.stream().parallel().forEach(list2::add);
long endTimex = System.currentTimeMillis(); //获取结束时间
System.out.println("并行执行程序运行时间: " + (endTimex - startTimex) + "ms");//283ms
虽然还是使用for循环快一些 但是没有了在低数量级的很多倍的差距了 而这样的代价我们还是可以接受的.
这里有一个大数量级的测试可以去看一下
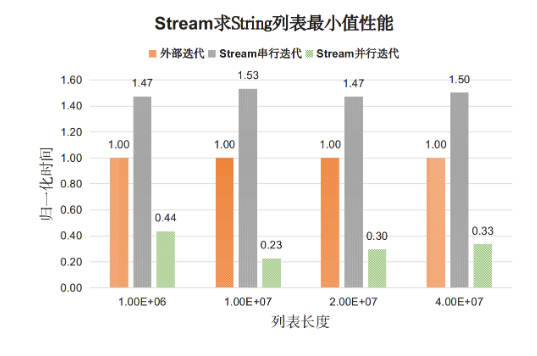
对于基本数据展示的是for循环外部迭代耗时为基准的时间比值。分析如下:
- 对于基本类型Stream串行迭代的性能开销明显高于外部迭代开销(两倍);
- Stream并行迭代的性能比串行迭代和外部迭代都好。
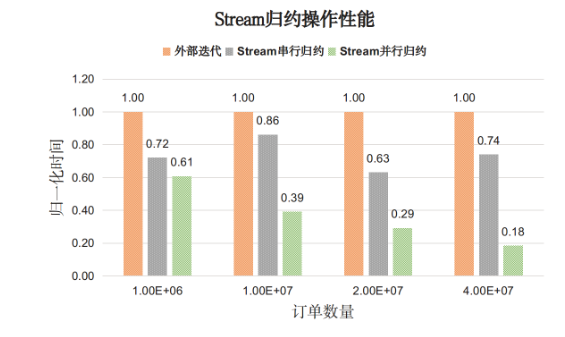
Stream API的性能普遍好于外部手动迭代,并行Stream效果更佳;
3、collect()保证有序性
如果不想用Lock锁 或者不用forEach的forEachOrdered方法 可以使用collect() 方法在聚合数据的时候进行约束.。
List<Integer> numbers = Arrays.asList(1, 2, 3, 4, 5, 6, 7, 8, 9);
numbers.parallelStream()
.forEachOrdered(out::println);
//以下代码就可以保证结果与原始列表中的顺序相同
// ["a", "b", "c"]
List<String> toProcess;
// should be ["a", "b", "c"]
List<String> results = toProcess.parallelStream()
.map(s -> s)
.collect(Collectors.toList());
在encounter order中工作的操作以元素的原始顺序操作元素。但文档也说了是不保证有序性的.
实现代码
检查Collectors.java的实现,确认toList()不包括CONCURRENT或UNORDERED traits。
public static <T>
Collector<T, ?, List<T>> toList() {
return new CollectorImpl<>((Supplier<List<T>>) ArrayList::new, List::add,
(left, right) -> { left.addAll(right); return left; },
CH_ID);
}
// ...
static final Set<Collector.Characteristics> CH_ID
= Collections.unmodifiableSet(EnumSet.of(Collector.Characteristics.IDENTITY_FINISH));
注意收集器如何具有CH_ID trait集合,它只有单个IDENTITY_FINISH trait。 CONCURRENT和UNORDERED不存在,因此减少不能并发。
非并发减少意味着,如果流是并行的,则可以并行地进行收集,但是它将被分割成几个线程限制的中间结果,然后被组合。这确保组合结果是顺序的。
4、并发流的实现方法
fork/join模式自动对数据拆分,充分利用多核
fork就是把一个大任务切分为若干子任务并行的执行,Join就是合并这些子任务的执行结果,最后得到这个大任务的结果。
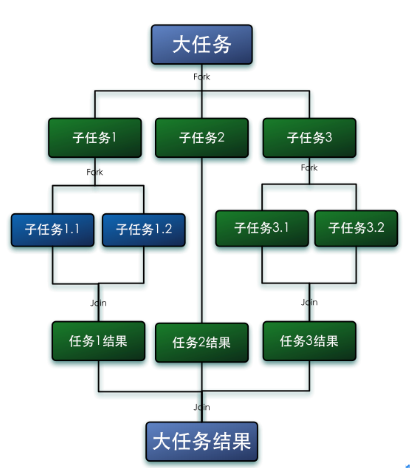
parallelStream的实现:ForkJoinPool
要想深入的研究parallelStream之前,那么我们必须先了解ForkJoin框架和ForkJoinPool.
ForkJoin框架是从jdk7中新特性,它同ThreadPoolExecutor一样,也实现了Executor和ExecutorService接口。它使用了一个无限队列来保存需要执行的任务,而线程的数量则是通过构造函数传入,如果没有向构造函数中传入希望的线程数量,那么当前计算机可用的CPU数量会被设置为线程数量作为默认值。
ForkJoinPool主要用来使用分治法(Divide-and-Conquer Algorithm)来解决问题。典型的应用比如快速排序算法。这里的要点在于,ForkJoinPool需要使用相对少的线程来处理大量的任务。比如要对1000万个数据进行排序,那么会将这个任务分割成两个500万的排序任务和一个针对这两组500万数据的合并任务。以此类推,对于500万的数据也会做出同样的分割处理,到最后会设置一个阈值来规定当数据规模到多少时,停止这样的分割处理。比如,当元素的数量小于10时,会停止分割,转而使用插入排序对它们进行排序。那么到最后,所有的任务加起来会有大概2000000+个。问题的关键在于,对于一个任务而言,只有当它所有的子任务完成之后,它才能够被执行。
所以当使用ThreadPoolExecutor时,使用分治法会存在问题,因为ThreadPoolExecutor中的线程无法像任务队列中再添加一个任务并且在等待该任务完成之后再继续执行。而使用ForkJoinPool时,就能够让其中的线程创建新的任务,并挂起当前的任务,此时线程就能够从队列中选择子任务执行。
那么使用ThreadPoolExecutor或者ForkJoinPool,会有什么性能的差异呢?
首先,使用ForkJoinPool能够使用数量有限的线程来完成非常多的具有父子关系的任务,比如使用4个线程来完成超过200万个任务。但是,使用ThreadPoolExecutor时,是不可能完成的,因为ThreadPoolExecutor中的Thread无法选择优先执行子任务,需要完成200万个具有父子关系的任务时,也需要200万个线程,显然这是不可行的。
工作窃取算法
forkjoin最核心的地方就是利用了现代硬件设备多核,在一个操作时候会有空闲的cpu,那么如何利用好这个空闲的cpu就成了提高性能的关键,而这里我们要提到的工作窃取(work-stealing)算法就是整个forkjion框架的核心理念,工作窃取(work-stealing)算法是指某个线程从其他队列里窃取任务来执行。
那么为什么需要使用工作窃取算法呢?
假如我们需要做一个比较大的任务,我们可以把这个任务分割为若干互不依赖的子任务,为了减少线程间的竞争,于是把这些子任务分别放到不同的队列里,并为每个队列创建一个单独的线程来执行队列里的任务,线程和队列一一对应,比如A线程负责处理A队列里的任务。但是有的线程会先把自己队列里的任务干完,而其他线程对应的队列里还有任务等待处理。干完活的线程与其等着,不如去帮其他线程干活,于是它就去其他线程的队列里窃取一个任务来执行。而在这时它们会访问同一个队列,所以为了减少窃取任务线程和被窃取任务线程之间的竞争,通常会使用双端队列,被窃取任务线程永远从双端队列的头部拿任务执行,而窃取任务的线程永远从双端队列的尾部拿任务执行。
工作窃取算法的优点是充分利用线程进行并行计算,并减少了线程间的竞争,其缺点是在某些情况下还是存在竞争,比如双端队列里只有一个任务时。并且消耗了更多的系统资源,比如创建多个线程和多个双端队列。
List<Integer> list = new ArrayList<>();
for (int i = 0; i < 10; i++) {
list.add(i);
}
// 统计并行执行list的线程
Set<Thread> threadSet = new CopyOnWriteArraySet<>();
// 并行执行
list.parallelStream().forEach(integer -> {
Thread thread = Thread.currentThread();
System.out.println(thread.getName());
// 统计并行执行list的线程
threadSet.add(thread);
});
System.out.println("threadSet一共有" + threadSet.size() + "个线程");
System.out.println("系统一个有"+Runtime.getRuntime().availableProcessors()+"个cpu");
}
输出:
ForkJoinPool.commonPool-worker-2
ForkJoinPool.commonPool-worker-1
main
threadSet一共有3个线程
系统一个有8个cpu
可以看到创建了3个线程来执行 main代表的是foreach的主线程也算一个线程 而ForkJoinPool.commonPool-worker才是动态调用的线程
这里看到只有3个线程是因为数量级太小了 如果list的元素有1000000个那么会把8个线程都用满
Java 8为ForkJoinPool添加了一个通用线程池,这个线程池用来处理那些没有被显式提交到任何线程池的任务。它是ForkJoinPool类型上的一个静态元素,它拥有的默认线程数量等于运行计算机上的处理器数量
5、ParallelStreams 的陷阱
上文中我们已经看到了ParallelStream他强大无比的特性,但这里我们就讲告诉你ParallelStreams不是万金油,而是一把双刃剑,如果错误的使用反倒可能伤人伤己.
以下是一个我们项目里使用 parallel streams 的很常见的情况。在这个例子中,我们想同时调用不同地址的api中并且获得第一个返回的结果。
public static String query(String q, List<String> engines) { Optional<String> result = engines.stream().parallel().map((base) -> {
String url = base + q;
return WS.url(url).get();
}).findAny();
return result.get();
}
可能有很多朋友在jdk7用future配合countDownLatch自己实现的这个功能,但是jdk8的朋友基本都会用上面的实现方式,那么自信深究一下究竟自己用future实现的这个功能和利用jdk8的parallelStream来实现这个功能有什么不同点呢?坑又在哪里呢?
让我们细思思考一下整个功能究竟是如何运转的。首先我们的集合元素engines 由ParallelStreams并行的去进行map操作(ParallelStreams使用JVM默认的forkJoin框架的线程池由当前线程去执行并行操作).
然而,这里需要注意的一地方是我们在调用第三方的api请求是一个响应略慢而且会阻塞操作的一个过程。所以在某时刻所有线程都会调用 get() 方法并且在那里等待结果返回.
再回过头仔细思考一下这个功能的实现过程是我们一开始想要的吗?我们是在同一时间等待所有的结果,而不是遍历这个列表按顺序等待每个回答.然而,由于ForkJoinPool workders的存在,这样平行的等待相对于使用主线程的等待会产生的一种副作用.
现在ForkJoin pool (关于forkjion的更多实现你可以去搜索引擎中去看一下他的具体实现方式) 的实现是: 它并不会因为产生了新的workers而抵消掉阻塞的workers。那么在某个时间所有 ForkJoinPool.common() 的线程都会被用光.也就是说,下一次你调用这个查询方法,就可能会在一个时间与其他的parallel stream同时运行,而导致第二个任务的性能大大受损。或者说,例如你在这个功能里是用来快速返回调用的第三方api的,而在其他的功能里是用于一些简单的数据并行计算的,但是假如你先调用了这个功能,同一时间之后调用计算的函数,那么这里forkjionPool的实现会让你计算的函数大打折扣.
不过也不要急着去吐槽ForkJoinPool的实现,在不同的情况下你可以给它一个ManagedBlocker实例并且确保它知道在一个阻塞调用中应该什么时候去抵消掉卡住的workers.现在有意思的一点是,在一个parallel stream处理中并不一定是阻塞调用会拖延程序的性能。任何被用于映射在一个集合上的长时间运行的函数都会产生同样的问题.
正如我们上面那个列子的情况分析得知,lambda的执行并不是瞬间完成的,所有使用parallel streams的程序都有可能成为阻塞程序的源头,并且在执行过程中程序中的其他部分将无法访问这些workers,这意味着任何依赖parallel streams的程序在什么别的东西占用着common ForkJoinPool时将会变得不可预知并且暗藏危机.
怎么正确使用parallelStream
如果你正在写一个其他地方都是单线程的程序并且准确地知道什么时候你应该要使用parallel streams,这样的话你可能会觉得这个问题有一点肤浅。然而,我们很多人是在处理web应用、各种不同的框架以及重量级应用服务。一个服务器是怎样被设计成一个可以支持多种独立应用的主机的?谁知道呢,给你一个可以并行的却不能控制输入的parallel stream.
很抱歉,请原谅我用的标注[怎么正确使用parallelStream],因为目前为止我也没有发现一个好的方式来让我真正的正确使用parallelStream.下面的网上写的两种方式:
一种方式是限制ForkJoinPool提供的并行数。可以通过使用-Djava.util.concurrent.ForkJoinPool.common.parallelism=1 来限制线程池的大小为1。不再从并行化中得到好处可以杜绝错误的使用它(其实这个方式还是有点搞笑的,既然这样搞那我还不如不去使用并行流)。
另一种方式就是,一个被称为工作区的可以让ForkJoinPool平行放置的 parallelStream() 实现。不幸的是现在的JDK还没有实现。
Parallel streams 是无法预测的,而且想要正确地使用它有些棘手。几乎任何parallel streams的使用都会影响程序中无关部分的性能,而且是一种无法预测的方式。。但是在调用stream.parallel() 或者parallelStream()时候在我的代码里之前我仍然会重新审视一遍他给我的程序究竟会带来什么问题,他能有多大的提升,是否有使用他的意义.
stream or parallelStream?
上面我们也看到了parallelStream所带来的隐患和好处,那么,在从stream和parallelStream方法中进行选择时,我们可以考虑以下几个问题
1. 是否需要并行?
2. 任务之间是否是独立的?是否会引起任何竞态条件?
3. 结果是否取决于任务的调用顺序?
对于问题1,在回答这个问题之前,你需要弄清楚你要解决的问题是什么,数据量有多大,计算的特点是什么?并不是所有的问题都适合使用并发程序来求解,比如当数据量不大时,顺序执行往往比并行执行更快。毕竟,准备线程池和其它相关资源也是需要时间的。但是,当任务涉及到I/O操作并且任务之间不互相依赖时,那么并行化就是一个不错的选择。通常而言,将这类程序并行化之后,执行速度会提升好几个等级。
对于问题2,如果任务之间是独立的,并且代码中不涉及到对同一个对象的某个状态或者某个变量的更新操作,那么就表明代码是可以被并行化的。
对于问题3,由于在并行环境中任务的执行顺序是不确定的,因此对于依赖于顺序的任务而言,并行化也许不能给出正确的结果。
6、何时使用并发流
–较“重”的定时任务
–指定线程池
参考:
https://blog.csdn.net/qq\_30054997/article/details/81134626#










