
相比现在流行大数据技术,你可能觉得 Kettle 的使用场景太少了,或者没有必要使用这么个玩意儿,查看了下 github kettle 发现最近也有一些更新,另外,对于没有编程经验的数据使用人员,使用非常简单的 Kettle,通过图形界面设计实现做什么业务,无需写代码去实现,就可以做一些实验,比如:抓取网站上的股票数据、外汇信息等等。
Kettle 支持很多种输入和输出格式,包括文本文件,数据表,以及数据库引擎。总之,Kettle 强大的输入、输出、转换功能让你非常方便的操作数据。
常用的输入步骤
文件输入步骤
常见文本文件输入步骤包括:CSV 文件输入、Excel输入、文本文件输入等。
在之前的文章中已经介绍过 HelloWorld 级别的功能「把数据从 CSV 文件复制到 Excel 文件」,详细步骤可查阅。
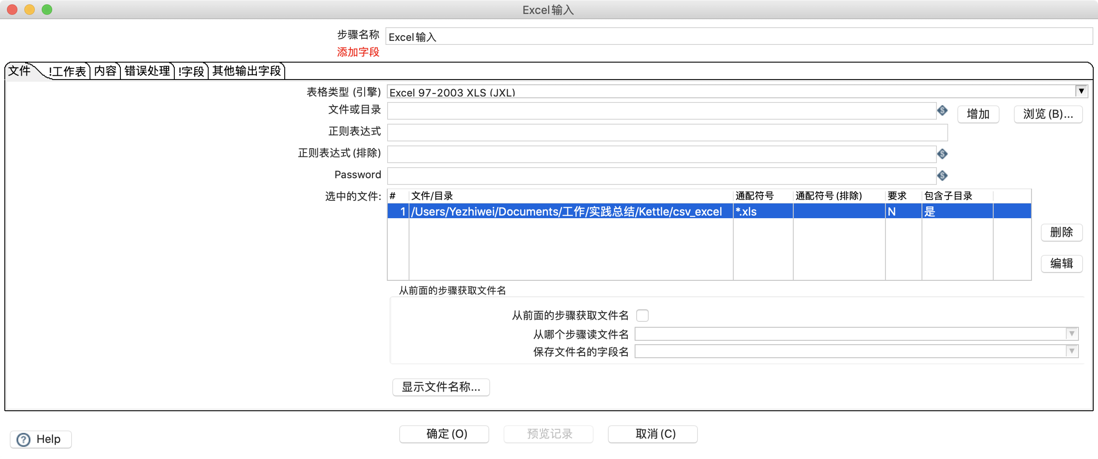
可以选择同一目录下的所有文件,通过选择目录,然后通配符号通配文件,也可以选择是否读取当前目录下子目录的文件,如下图:
XML 输入步骤
XML 是可扩展标记语言,主要用来传输与存储数据,在一些比较传统的系统还在使用这种方式进行数据传输对接,借助「Get data from XML」输入步骤,获取 XML 文件中的数据信息,通过使用 xpath 来确定 XML 文档中某部分数据的位置,xpath 基于 XML 的树状结构,提供在数据结构树中找寻节点的能力。
示例
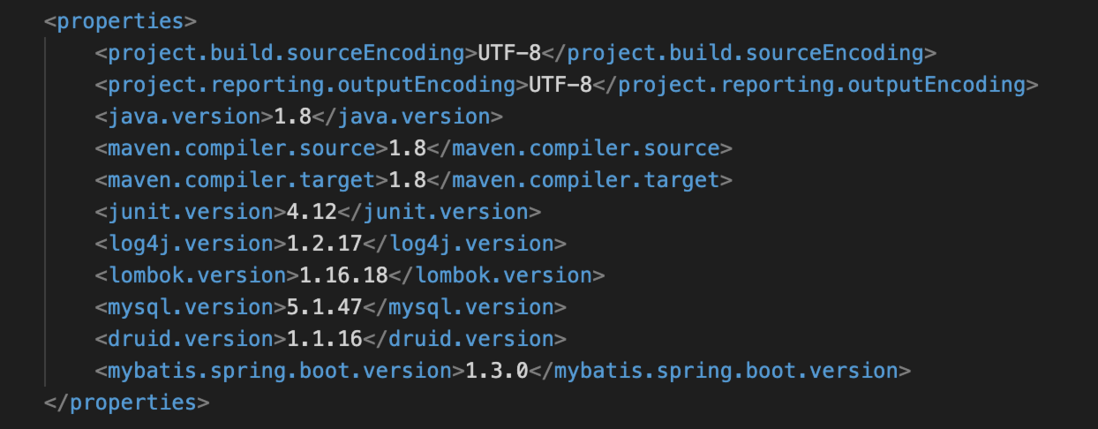
通过向导完成一个示例,读取 POM 文件中的属性配置信息,如下图:


xpath 常用表达式
| 表达式 | 说明 |
|---|---|
| nodename | 选取此节点的所有子节点 |
| / | 从根节点选取 |
| // | 从匹配选择的当前节点选择文档中的节点,而不考虑它们的位置 |
| . | 选取当前节点 |
| ... | 选取当前节点的父节点 |
| @ | 选取属性 |
| div | 选取 div 元素的所有子节点 |
| /div | 选取根元素 div |
| div/p | 选取 div 元素下的子元素 p |
| //div | 选取所有的 div 元素 |
| div//p | 选取 div 元素下的所有 p 元素 |
| //@lang | 选取名为 lang 的所有属性 |
JSON 输入步骤
相比于 XML,是一种轻量型的数据交换格式。JSON 核心概念:数组( [] 中的数据),对象( {} 中的数据),属性( k:v 的数据)
实现「调用 RESTful 接口导入 JSON 结果入库」的功能,不管是通过 Java 或者是 Python 编码的方式调用 RESTful接口将结果入库,都是有一定复杂度的,首先你要加载第三方 REST 组件依赖,然后连接数据库,写 SQL 语句,最后插入的目标数据库中。但我们有了 Kettle 这个工具之后,只需要使用图形化界面 Spoon 就可以很方便的完成接口调用及入库的操作。
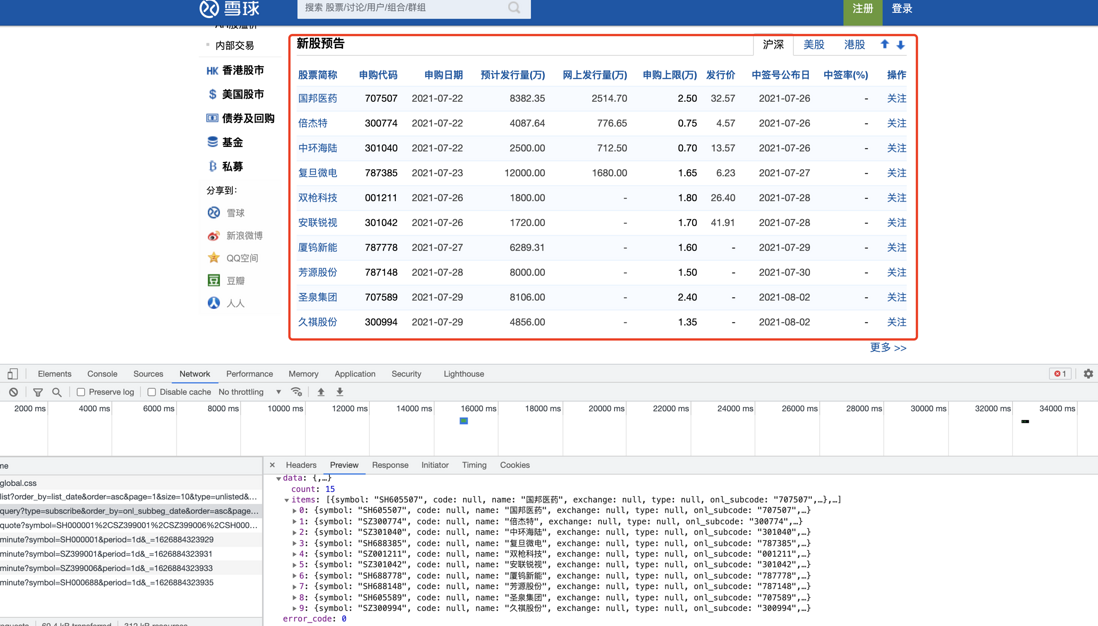
通过一个简单的 GET 请求,获取「沪深新股预告」信息,数据情况及操作如下
数据示例
接口信息
https://xueqiu.com/service/v5...
转换步骤:
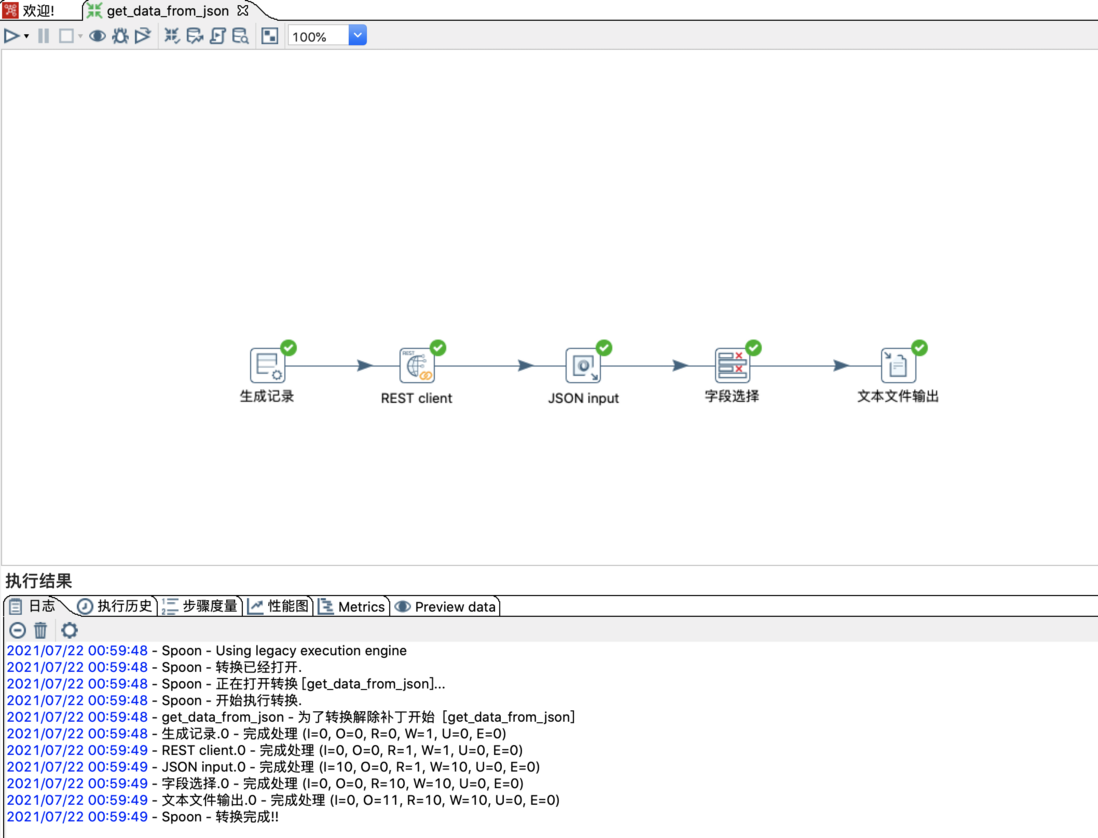
输出结果
具体配置步骤

表输入步骤
添加数据库驱动
要是想要操作数据库,就得先下载数据库驱动,然后放置在 /data-integration/lib 下,默认包括如下驱动:
(base) ~/Documents/apps/data-integration/lib ls -al | grep sql
-rw-r--r--@ 1 Yezhiwei staff 1473091 Jun 11 2019 hsqldb-2.3.2.jar
-rw-r--r--@ 1 Yezhiwei staff 825943 Jun 11 2019 postgresql-42.2.5.jar
-rw-r--r--@ 1 Yezhiwei staff 3201133 Jun 11 2019 sqlite-jdbc-3.7.2.jar添加 MySQL 驱动 jar 包 mysql-connector-java-5.1.41.jar 到 /data-integration/lib 下:

配置数据库连接
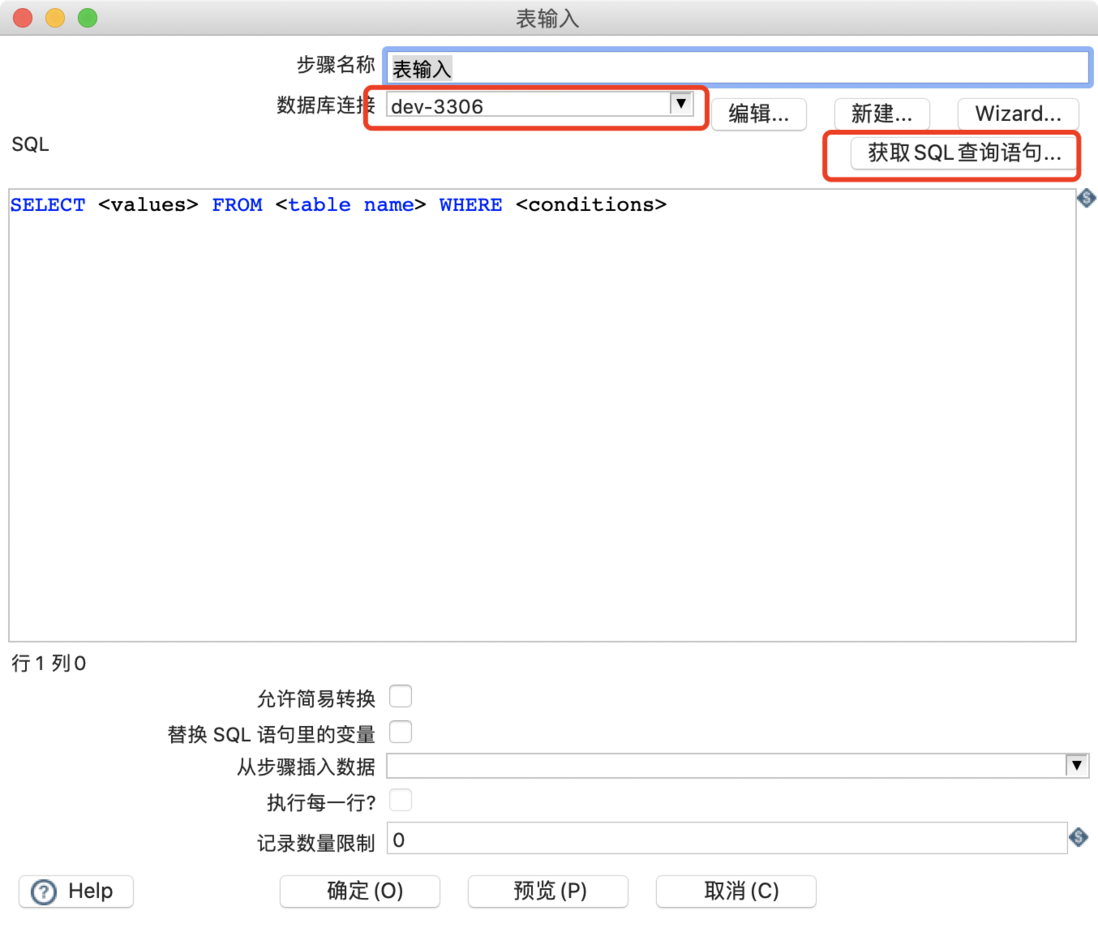
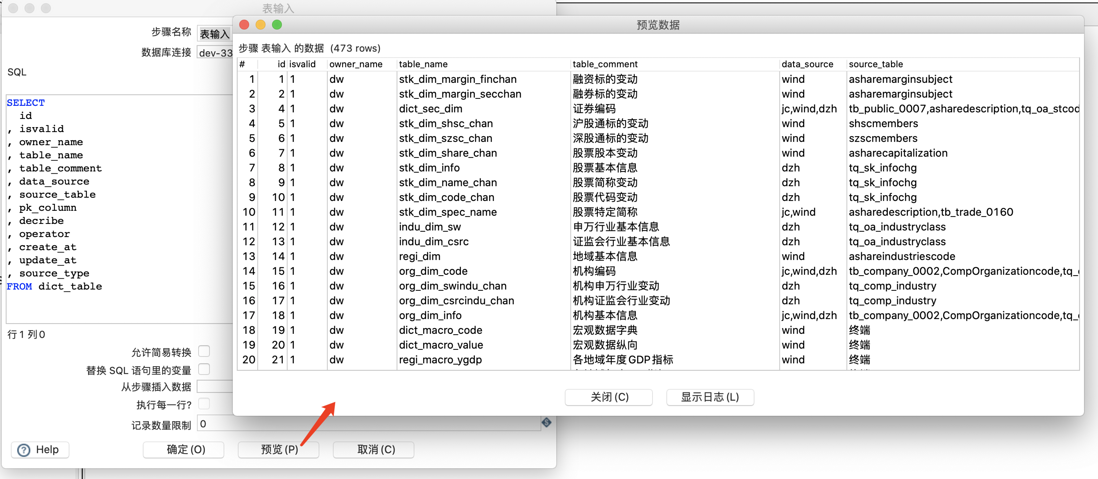
获取表 SQL 查询语句,数据预览
选择数据库连接配置,然后点击「获取 SQL 查询语句」
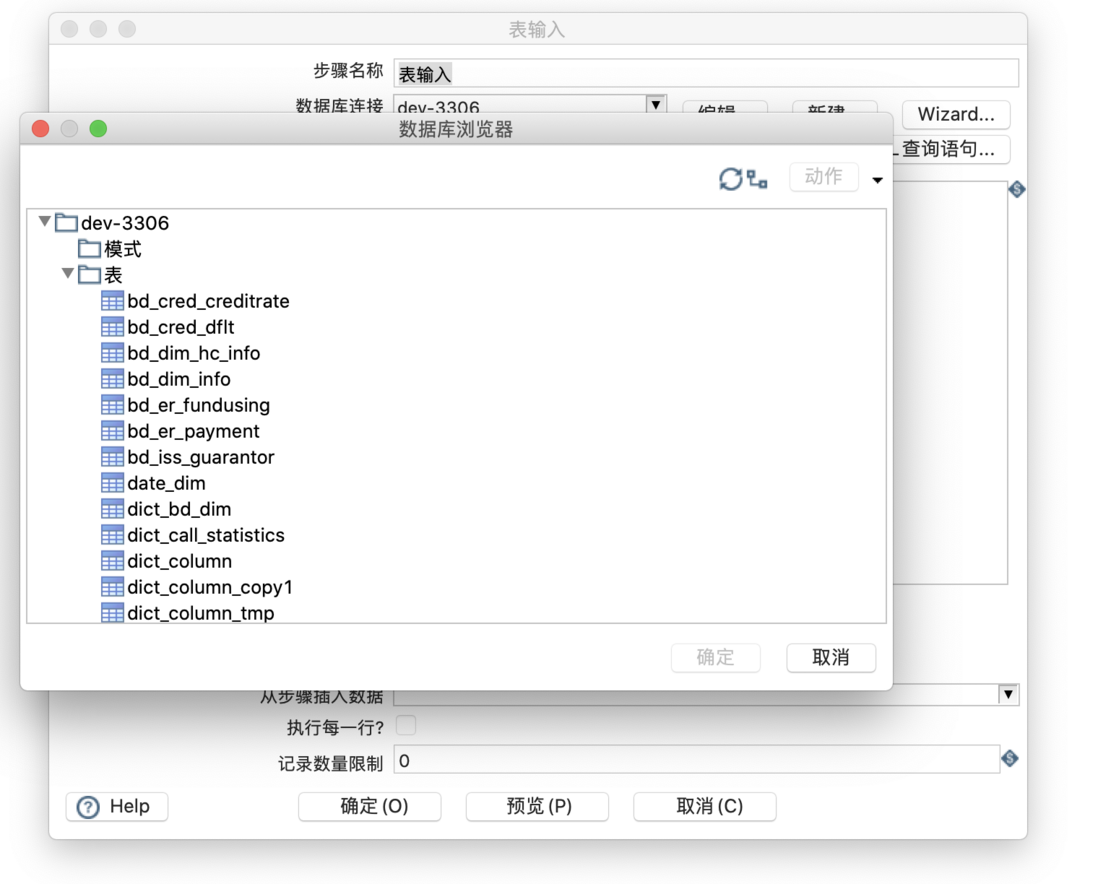
选择表,根据提示完成设置,自动生成 SQL,「预览」可以查看数据。

常用的输出步骤
通常将数据处理完成后需要保存到一个地方,方便后续使用,通常情况下输出为 Excel 或数据库中,前面的示例中已经介绍过 Excel 输出,下面重点介绍数据库方面的输出步骤。
数据库输出步骤常用的有插入/更新/删除,示例重点体现「插入/更新」和「删除」输出步骤
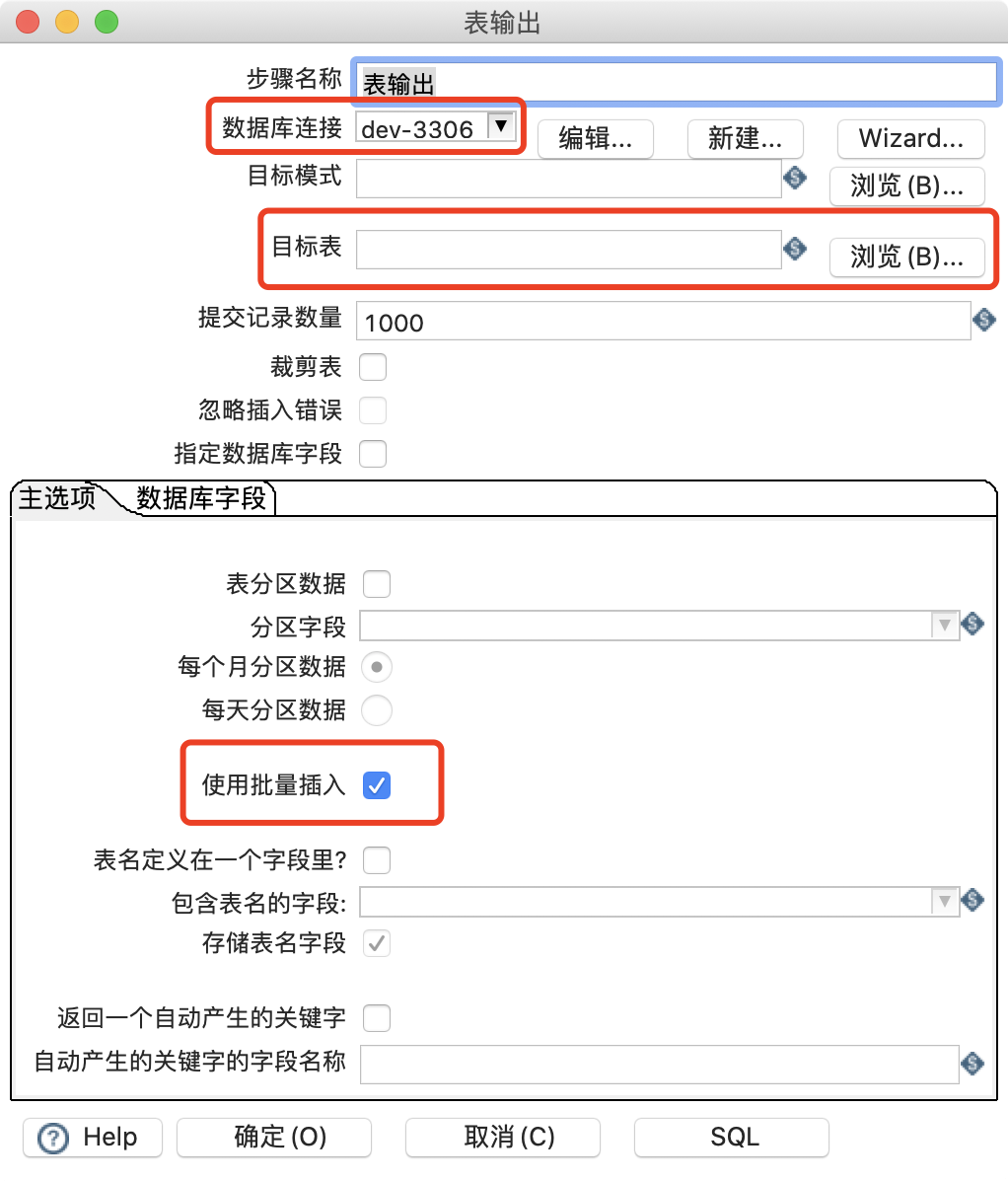
表输出
将其他输入源的数据输出到表中
更新
更新就是把数据库中已经存在的记录与数据流里面的记录进行对比,如果不同就进行更新
插入更新
插入更新就是在更新的基础上插入了数据流中多余的数据
删除
删除可以和自定义常量输入一起使用,定义一个常量条件,不符合这个条件的数据全部删除
示例
数据准备
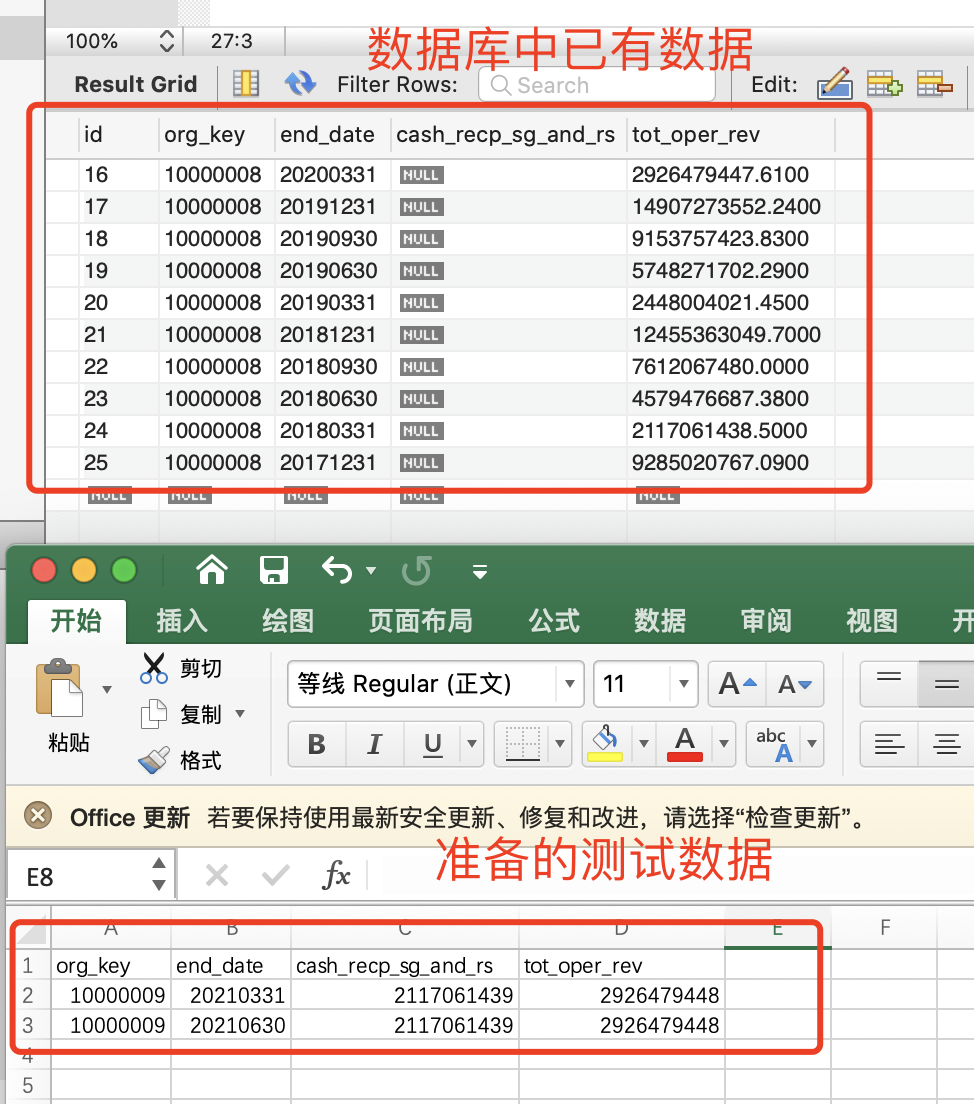
数据从 Excel 插入或更新到 MySQL
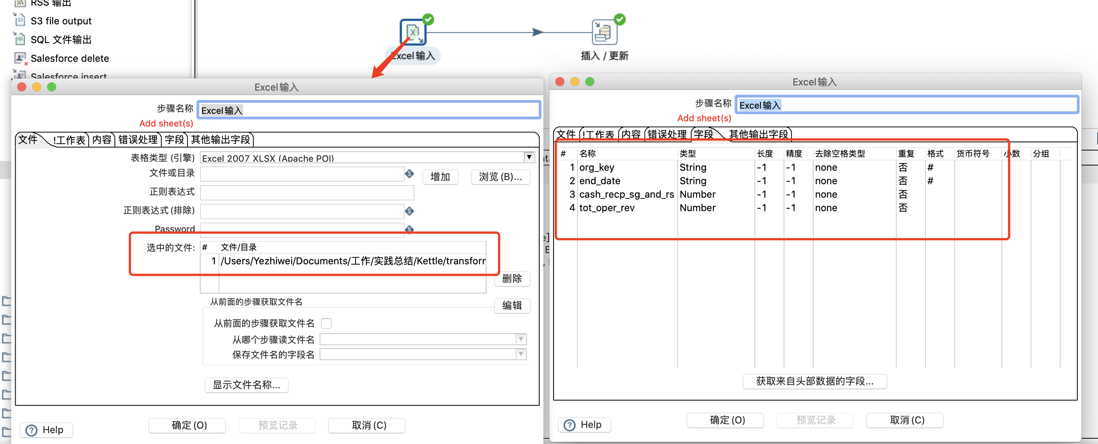
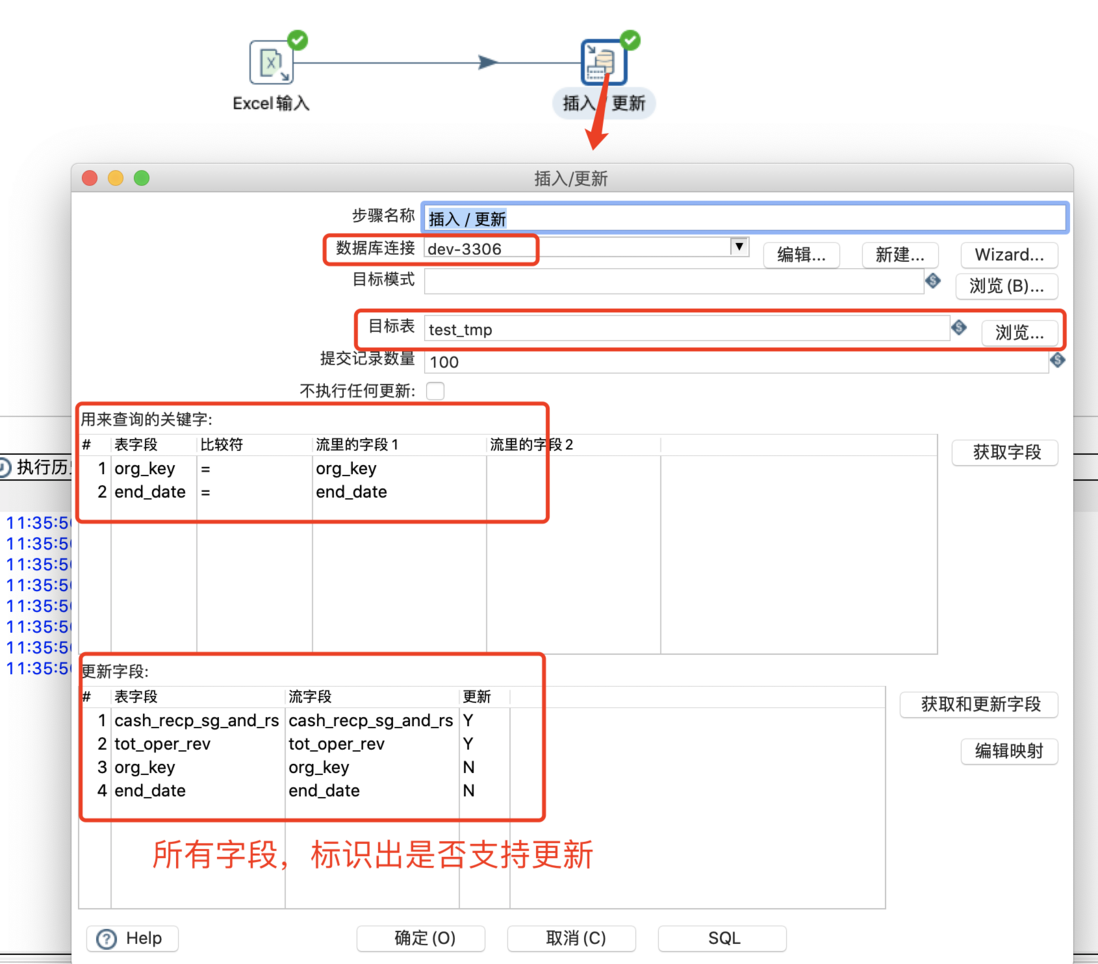
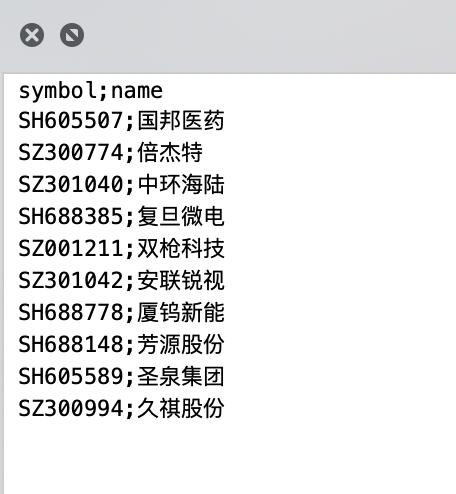
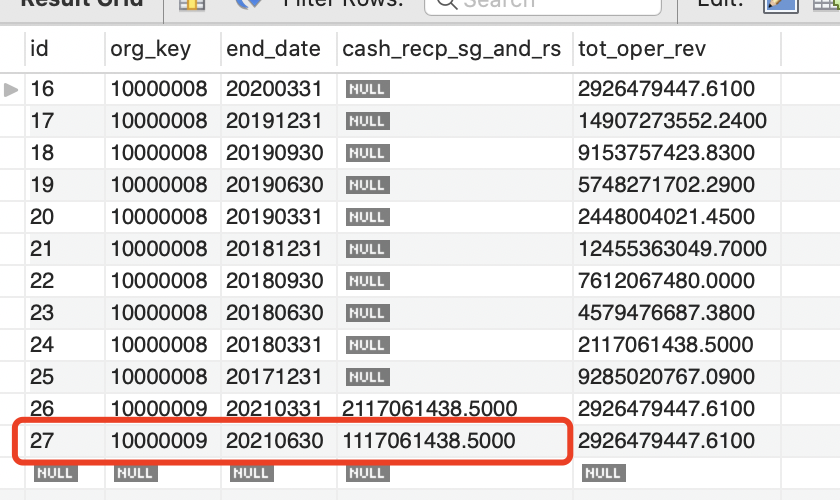
新数据插入结果
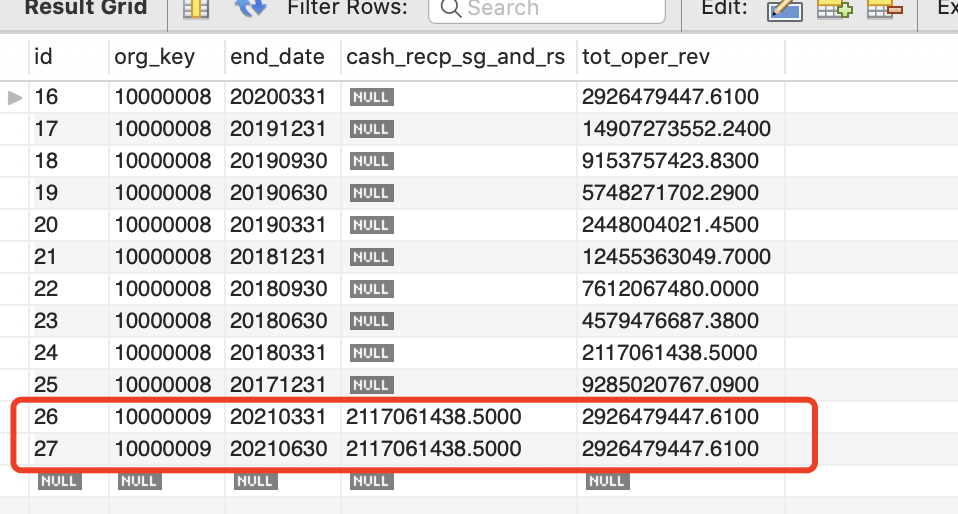
更新结果
结语
在数据仓库技术中,ETL 是必不可少,Kettle 作为 ETL 的经典工具,通过图形界面设计实现做什么业务,无需写代码去实现,对于没有编程经验的数据使用人员来说,也是非常简单的。
当然,也存在一些问题,比如:处理的数据量相对小些、文档资料相对少些等等。有机会再总结一下使用过程中遇到的问题。
欢迎关注公众号:HelloTech,获取更多内容






