前言
在 《一篇带你用 VuePress + Github Pages 搭建博客》中,我们使用 VuePress 搭建了一个博客,最终的效果查看:TypeScript 中文文档。
在搭建博客的过程中,我们出于实际的需求,在《VuePress 博客优化之拓展 Markdown 语法》中讲解了如何写一个 markdown-it插件,本篇我们将深入markdown-it的源码,讲解 markdown-it的执行原理,旨在让大家对 markdown-it有更加深入的理解。
介绍
引用 markdown-it Github 仓库的介绍:
Markdown parser done right. Fast and easy to extend.
可以看出 markdown-it是一个 markdown 解析器,并且易于拓展。
其演示地址为:https://markdown-it.github.io/
markdown-it具有以下几个优势:
- 遵循 CommonMark spec 并且添加了语法拓展和语法糖(如URL 自动识别,针对印刷做了特殊处理)
- 可配置语法,你可以添加新的规则或者替换掉现有的规则
- 快
- 默认安全
- 社区有很多的插件或者其他包
使用
// 安装
npm install markdown-it --save// node.js, "classic" way:
var MarkdownIt = require('markdown-it'),
md = new MarkdownIt();
var result = md.render('# markdown-it rulezz!');
// browser without AMD, added to "window" on script load
// Note, there is no dash in "markdownit".
var md = window.markdownit();
var result = md.render('# markdown-it rulezz!');源码解析
我们查看 markdown-it 的入口代码,可以发现其代码逻辑清晰明了:
// ...
var Renderer = require('./renderer');
var ParserCore = require('./parser_core');
var ParserBlock = require('./parser_block');
var ParserInline = require('./parser_inline');
function MarkdownIt(presetName, options) {
// ...
this.inline = new ParserInline();
this.block = new ParserBlock();
this.core = new ParserCore();
this.renderer = new Renderer();
// ...
}
MarkdownIt.prototype.parse = function (src, env) {
// ...
var state = new this.core.State(src, this, env);
this.core.process(state);
return state.tokens;
};
MarkdownIt.prototype.render = function (src, env) {
env = env || {};
return this.renderer.render(this.parse(src, env), this.options, env);
};从 render方法中也可以看出,其渲染分为两个过程:
- Parse:将 Markdown 文件 Parse 为 Tokens
- Render:遍历 Tokens 生成 HTML
跟 Babel 很像,不过 Babel 是转换为抽象语法树(AST),而 markdown-it 没有选择使用 AST,主要是为了遵循 KISS(Keep It Simple, Stupid) 原则。
Tokens
那 Tokens 长什么样呢?我们不妨在演示页面中尝试一下:
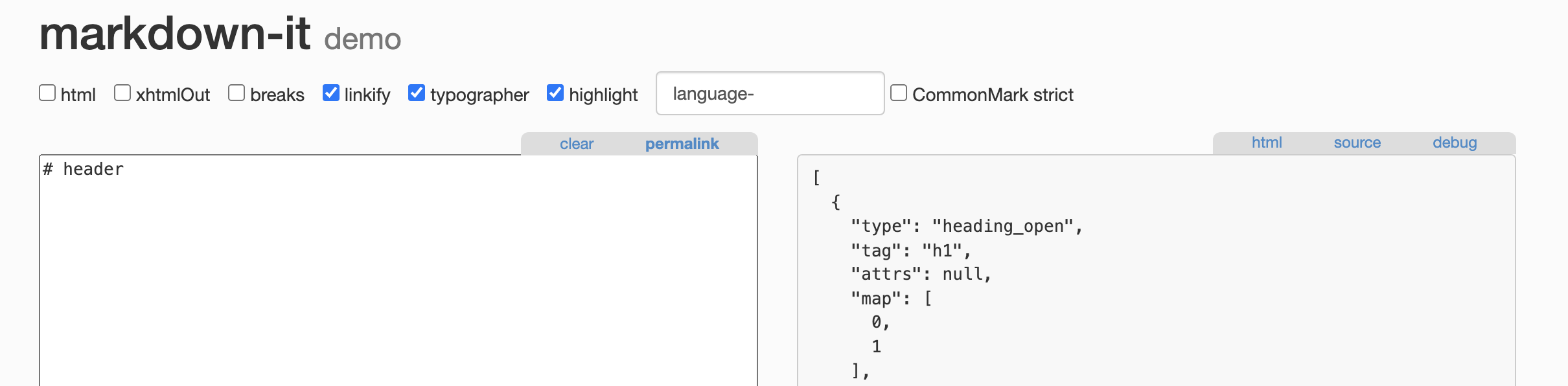
可以看出 # header生成的 Token 格式为(注:这里为了展示方便,简化了):
[
{
"type": "heading_open",
"tag": "h1"
},
{
"type": "inline",
"tag": "",
"children": [
{
"type": "text",
"tag": "",
"content": "header"
}
]
},
{
"type": "heading_close",
"tag": "h1"
}
]具体 Token 里的字段含义可以查看 Token Class。
通过这个简单的 Tokens 示例也可以看出 Tokens 和 AST 的区别:
- Tokens 只是一个简单的数组
- 起始标签和闭合标签是分开的
Parse
查看 parse 方法相关的代码:
// ...
var ParserCore = require('./parser_core');
function MarkdownIt(presetName, options) {
// ...
this.core = new ParserCore();
// ...
}
MarkdownIt.prototype.parse = function (src, env) {
// ...
var state = new this.core.State(src, this, env);
this.core.process(state);
return state.tokens;
};可以看到其具体执行的代码,应该是写在了./parse_core 里,查看下 parse_core.js 的代码:
var _rules = [
[ 'normalize', require('./rules_core/normalize') ],
[ 'block', require('./rules_core/block') ],
[ 'inline', require('./rules_core/inline') ],
[ 'linkify', require('./rules_core/linkify') ],
[ 'replacements', require('./rules_core/replacements') ],
[ 'smartquotes', require('./rules_core/smartquotes') ]
];
function Core() {
// ...
}
Core.prototype.process = function (state) {
// ...
for (i = 0, l = rules.length; i < l; i++) {
rules[i](state);
}
};可以看出,Parse 过程默认有 6 条规则,其主要作用分别是:
1. normalize
在 CSS 中,我们使用normalize.css 抹平各端差异,这里也是一样的逻辑,我们查看 normalize 的代码,其实很简单:
// https://spec.commonmark.org/0.29/#line-ending
var NEWLINES_RE = /\r\n?|\n/g;
var NULL_RE = /\0/g;
module.exports = function normalize(state) {
var str;
// Normalize newlines
str = state.src.replace(NEWLINES_RE, '\n');
// Replace NULL characters
str = str.replace(NULL_RE, '\uFFFD');
state.src = str;
};我们知道 \n是匹配一个换行符,\r是匹配一个回车符,那这里为什么要将 \r\n替换成 \n 呢?
我们可以在阮一峰老师的这篇 《回车与换行》中找到\r\n出现的历史:
在计算机还没有出现之前,有一种叫做电传打字机(Teletype Model 33)的玩意,每秒钟可以打10个字符。但是它有一个问题,就是打完一行换行的时候,要用去0.2秒,正好可以打两个字符。要是在这0.2秒里面,又有新的字符传过来,那么这个字符将丢失。
于是,研制人员想了个办法解决这个问题,就是在每行后面加两个表示结束的字符。一个叫做"回车",告诉打字机把打印头定位在左边界;另一个叫做"换行",告诉打字机把纸向下移一行。
这就是"换行"和"回车"的来历,从它们的英语名字上也可以看出一二。
后来,计算机发明了,这两个概念也就被般到了计算机上。那时,存储器很贵,一些科学家认为在每行结尾加两个字符太浪费了,加一个就可以。于是,就出现了分歧。
Unix系统里,每行结尾只有"<换行>",即"\n";Windows系统里面,每行结尾是"<回车><换行>",即"\r\n";Mac系统里,每行结尾是"<回车>"。一个直接后果是,Unix/Mac系统下的文件在Windows里打开的话,所有文字会变成一行;而Windows里的文件在Unix/Mac下打开的话,在每行的结尾可能会多出一个^M符号。
之所以将 \r\n替换成 \n其实是遵循规范:
A line ending is a newline (U+000A), a carriage return (U+000D) not followed by a newline, or a carriage return and a following newline.
其中 U+000A 表示换行(LF) ,U+000D 表示回车(CR) 。
除了替换回车符外,源码里还替换了空字符,在正则中,\0表示匹配 NULL(U+0000)字符,根据 WIKI 的解释:
空字符(Null character)又称结束符,缩写 NUL,是一个数值为 0 的控制字符。
在许多字符编码中都包括空字符,包括ISO/IEC 646(ASCII)、C0控制码、通用字符集、Unicode和EBCDIC等,几乎所有主流的编程语言都包括有空字符
这个字符原来的意思类似NOP指令,当送到列表机或终端时,设备不需作任何的动作(不过有些设备会错误的打印或显示一个空白)。
而我们将空字符替换为 \uFFFD,在 Unicode 中,\uFFFD表示替换字符:

之所以进行这个替换,其实也是遵循规范,我们查阅 CommonMark spec 2.3 章节:
For security reasons, the Unicode character U+0000 must be replaced with the REPLACEMENT CHARACTER (U+FFFD).
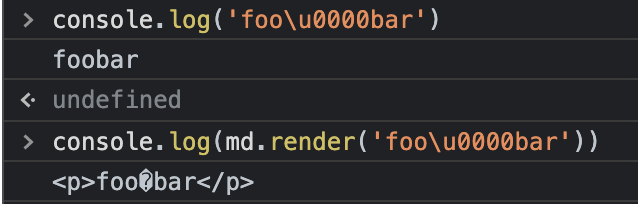
我们测试下这个效果:
md.render('foo\u0000bar'), '<p>foo\uFFFDbar</p>\n'效果如下,你会发现原本不可见的空字符被替换成替换字符后,展示了出来:
2. block
block 这个规则的作用就是找出 block,生成 tokens,那什么是 block?什么是 inline 呢?我们也可以在CommonMark spec 中的 Blocks and inlines 章节 找到答案:
We can think of a document as a sequence of blocks—structural elements like paragraphs, block quotations, lists, headings, rules, and code blocks. Some blocks (like block quotes and list items) contain other blocks; others (like headings and paragraphs) contain inline content—text, links, emphasized text, images, code spans, and so on.
翻译一下就是:
我们认为文档是由一组 blocks 组成,结构化的元素类似于段落、引用、列表、标题、代码区块等。一些 blocks (像引用和列表)可以包含其他 blocks,其他的一些 blocks(像标题和段落)则可以包含 inline 内容,比如文字、链接、 强调文字、图片、代码片段等等。
当然在markdown-it中,哪些会识别成 blocks,可以查看 parser_block.js,这里同样定义了一些识别和 parse 的规则:
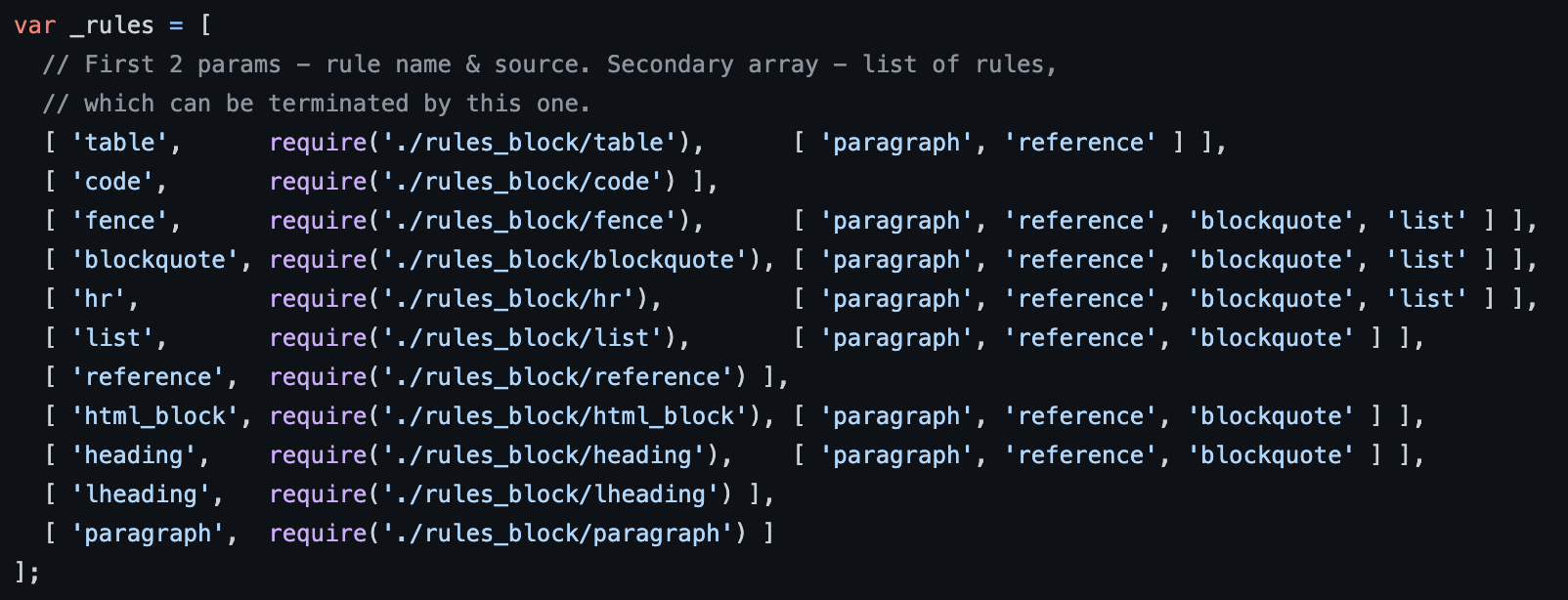
关于这些规则我挑几个不常见的说明一下:
code 规则用于识别 Indented code blocks (4 spaces padded),在 markdown 中:

fence 规则用于识别 Fenced code blocks,在markdown 中:

hr 规则用于识别换行,在 markdown 中:

reference 规则用于识别 reference links,在 markdown 中:

html_block 用于识别 markdown 中的 HTML block 元素标签,就比如div。
lheading 用于识别 Setext headings,在 markdown 中:

3. inline
inline 规则的作用则是解析 markdown 中的 inline,然后生成 tokens,之所以 block 先执行,是因为 block 可以包含 inline ,解析的规则可以查看 parser_inline.js:
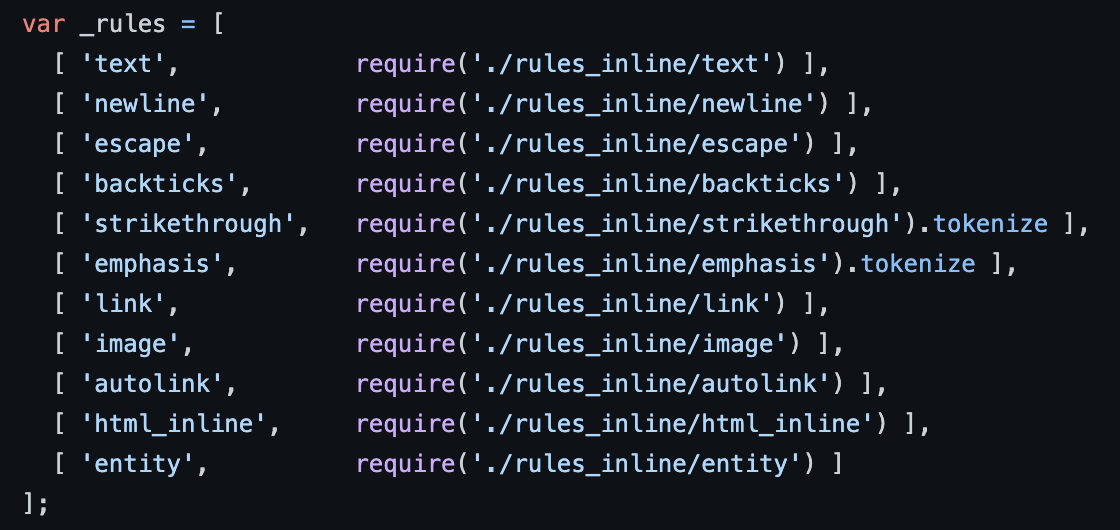
关于这些规则我挑几个不常见的说明一下:
newline规则用于识别 \n,将 \n 替换为一个 hardbreak 类型的 token
backticks 规则用于识别反引号:

entity 规则用于处理 HTML entity,比如 {``¯``"等:

4. linkify
自动识别链接

5. replacements
将 (c)`` (C) 替换成 ©,将 ???????? 替换成 ???,将 !!!!! 替换成 !!!,诸如此类:

6. smartquotes
为了方便印刷,对直引号做了处理:

Render
Render 过程其实就比较简单了,查看 renderer.js 文件,可以看到内置了一些默认的渲染 rules:
default_rules.code_inline
default_rules.code_block
default_rules.fence
default_rules.image
default_rules.hardbreak
default_rules.softbreak
default_rules.text
default_rules.html_block
default_rules.html_inline其实这些名字也是 token 的 type,在遍历 token 的时候根据 token 的 type 对应这里的 rules 进行执行,我们看下 code_inline 规则的内容,其实非常简单:
default_rules.code_inline = function (tokens, idx, options, env, slf) {
var token = tokens[idx];
return '<code' + slf.renderAttrs(token) + '>' +
escapeHtml(tokens[idx].content) +
'</code>';
};自定义 Rules
至此,我们对 markdown-it 的渲染原理进行了简单的了解,无论是 Parse 还是 Render 过程中的 Rules,markdown-it 都提供了方法可以自定义这些 Rules,这些也是写 markdown-it 插件的关键,这些后续我们会讲到。
系列文章
博客搭建系列是我至今写的唯一一个偏实战的系列教程,讲解如何使用 VuePress 搭建博客,并部署到 GitHub、Gitee、个人服务器等平台。
- 一篇带你用 VuePress + GitHub Pages 搭建博客
- 一篇教你代码同步 GitHub 和 Gitee
- 还不会用 GitHub Actions ?看看这篇
- Gitee 如何自动部署 Pages?还是用 GitHub Actions!
- 一份前端够用的 Linux 命令
- 一份简单够用的 Nginx Location 配置讲解
- 一篇从购买服务器到部署博客代码的详细教程
- 一篇域名从购买到备案到解析的详细教程
- VuePress 博客优化之 last updated 最后更新时间如何设置
- VuePress 博客优化之添加数据统计功能
- VuePress 博客优化之开启 HTTPS
- VuePress 博客优化之开启 Gzip 压缩
- 从零实现一个 VuePress 插件
微信:「mqyqingfeng」,加我进冴羽唯一的读者群。
如果有错误或者不严谨的地方,请务必给予指正,十分感谢。如果喜欢或者有所启发,欢迎 star,对作者也是一种鼓励。