
引言
在分布式系统中,保障数据一致性是至关重要的任务之一。数据一致性是指分布式系统中的各个节点在进行数据更新时能够保持数据的准确性和完整性。然而,由于网络延迟、节点故障等原因,分布式系统中的数据一致性问题变得复杂而具有挑战性。为了解决这一问题,二阶段提交(Two-Phase Commit)协议被广泛应用于保障分布式系统的数据一致性。本文将介绍二阶段提交协议的工作原理,并探讨其在分布式系统中的关键策略,亦将介绍在下一代数据集成工具 - Apache SeaTunnel 中实现二阶段提交的原理,探讨其在保障数据一致性方面的实践。
分布式一致性
分布式场景下,多个服务同时服务一个流程,比如电商下单场景,需要支付服务进行支付、库存服务扣减库存、物流服务更新物流信息等。如果某一个服务执行失败,或者网络不通引起的请求丢失,那么整个系统可能出现数据不一致。
上述场景就是分布式数据一致性的问题,其根本原因在于数据的分布式操作,引起本地事务无法保障数据的原子性。
分布式一致性问题的解决思路有两种,一种是分布式事务,一种是尽量通过业务流程避免分布式事务。由于分布式事务解决方案具有通用性,本文着重介绍分布式事务实现
分布式事务分类
分布式事务实现方案从类型上分为刚性事务和柔性事务。
刚性事务:保持强一致性,原生支持回滚/隔离性,低并发,适合短事务(XA协议(2PC、JTA、JTS)、3PC);
柔性事务:有业务改造,最终一致性,实现补偿接口,实现资源锁定接口,高并发,适合长事务(TCC、Saga(状态机模式,Aop模式)、本地事务消息、消息事务);本文主要介绍 XA
XA 两阶段提交协议
XA 协议即是通常所说的两阶段提交协议(Two-phase commit protocol),简称 2PC,过程涉及到协调者和参与者。
它是一种强一致性设计,引入一个协调者的角色来协调管理各参与者的提交和回滚,二阶段分别指的是准备(投票)和提交两个阶段。2PC 的算法思路可以概括为:参与者将操作成败通知协调者,再由协调者根据所有参与者的反馈结果决定各参与者是否要提交操作还是回滚操作。
第一阶段(准备阶段)
协调者节点(Coordinator)向所有参与者节点(Participants)发送 Prepare 提交请求,并等待它们的回复。
在接到 Prepare 请求之后,每一个参与者节点会各自执行与事务有关的数据更新,并将操作结果保存在本地的日志中。如果参与者执行成功,暂不提交事务,而是向协调节点返回 “完成” 消息。
当协调者接到了所有参与者的返回消息,整个分布式事务将会进入第二阶段。

假如在第一阶段有一个参与者返回失败,那么协调者就会向所有参与者发送回滚事务的请求,即分布式事务执行失败
第二阶段(提交阶段)
协调者节点根据参与者节点的回复情况,决定是否提交事务。
如果协调节点收到的都是同意提交,那么它将向所有事务参与者发出提交 Commit 请求,并等待参与者节点的确认。
参与者节点接到 Commit 请求后,将操作结果更新到数据库,并向协调者节点发送确认消息。
协调者节点收到所有参与者节点的确认消息后,最终决定提交或回滚事务,并将决策通知给所有参与者节点。
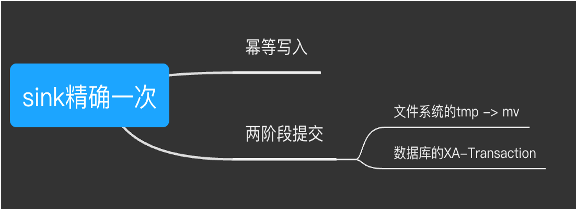
SeaTunnel 中的数据精确一致性实践
SeaTunnel 中的精确一次 Exactly-once 主要是以下 2 种方式来实现:
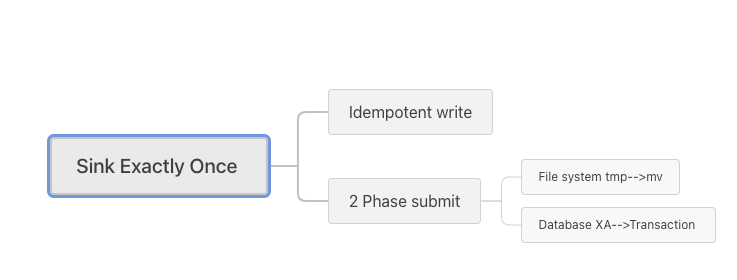
在 Sink 端为数据库时,通常采用的方式二阶段提交,以下为其流程图

其中涉及几个核心类:

特别的以 JDBC 的具体实现来看,
1、JdbcSink 实现了上述 SeaTunnelSink 接口

2、JdbcExactlyOnceSinkWriter 实现了 SinkWriter 接口
3、JdbcSinkCommitter 实现了 SinkCommitter
4、JdbcSinkAggregatedCommitter 实现 SinkAggregatedCommitter
类图如下:

如果有对 XA 事务实现感兴趣的同学可以看看 JdbcExactlyOnceSinkWriter 这类里的具体实现
总结
在 SeaTunnel 中,实现数据的精确一致性是一个重要的目标。SeaTunnel 采用了多种实践方法来保障数据的精确一致性。
SeaTunnel 支持二阶段提交,可以根据实际场景灵活定义和执行多个阶段的操作。这种灵活性使得 SeaTunnel 适用于更广泛的应用场景,并能够满足不同的一致性需求。
SeaTunnel 还具备强大的异常恢复和容错机制。它建立了心跳机制,定期检测节点的可用性。当节点故障或网络中断发生时,SeaTunnel 能够自动检测并进行相应的故障转移和恢复操作,以确保系统的稳定性和数据的一致性。
最后,SeaTunnel 提供了可定制的策略和扩展性。用户可以根据具体需求进行定制化设置,选择不同的数据一致性级别、超时机制、冲突解决策略等。此外,SeaTunnel 还支持水平扩展,能够轻松应对大规模分布式系统的需求。
综上所述,SeaTunnel 在实现数据的精确一致性方面采取了多种创新实践。通过二阶段提交、异常恢复和容错机制以及可定制的策略和扩展性,SeaTunnel 能够提供高性能、高可靠性的数据一致性保障。这些实践为分布式系统中的数据一致性问题提供了创新的解决方式!
参考:
https://www.jb51.net/article/236084.htm
https://zhuanlan.zhihu.com/p/417294966
本文由 白鲸开源科技 提供发布支持!






