
背景
Redis 不管主从版还是集群规格,replica作为备库不对外提供服务,只有在发生HA的时候,replica提升为master后才承担读写流量。这种架构读写请求都在master上完成,一致性较高,但性能受到master数量的限制。经常有用户数据较少,但因为流量或者并发太高而不得不升级到更大的集群规格。
为满足读多写少的业务场景,最大化节约用户成本,云数据库Redis版推出了读写分离规格,为用户提供透明、高可用、高性能、高灵活的读写分离服务
架构
Redis集群模式有redis-proxy、master、replica、HA等几个角色。在读写分离实例中,新增read-only replica角色来承担读流量,replica作为热备不提供服务,架构上保持对现有集群规格的兼容性。redis-proxy按权重将读写请求转发到master或者某个read-only replica上;HA负责监控DB节点的健康状态,异常时发起主从切换或重搭read-only replica,并更新路由。
一般来说,根据master和read-only replica的数据同步方式,可以分为两种架构:星型复制和链式复制。
星型复制
星型复制就是将所有的read-only replica直接和master保持同步,每个read-only replica之间相互独立,任何一个节点异常不影响到其他节点,同时因为复制链比较短,read-only replica上的复制延迟比较小。
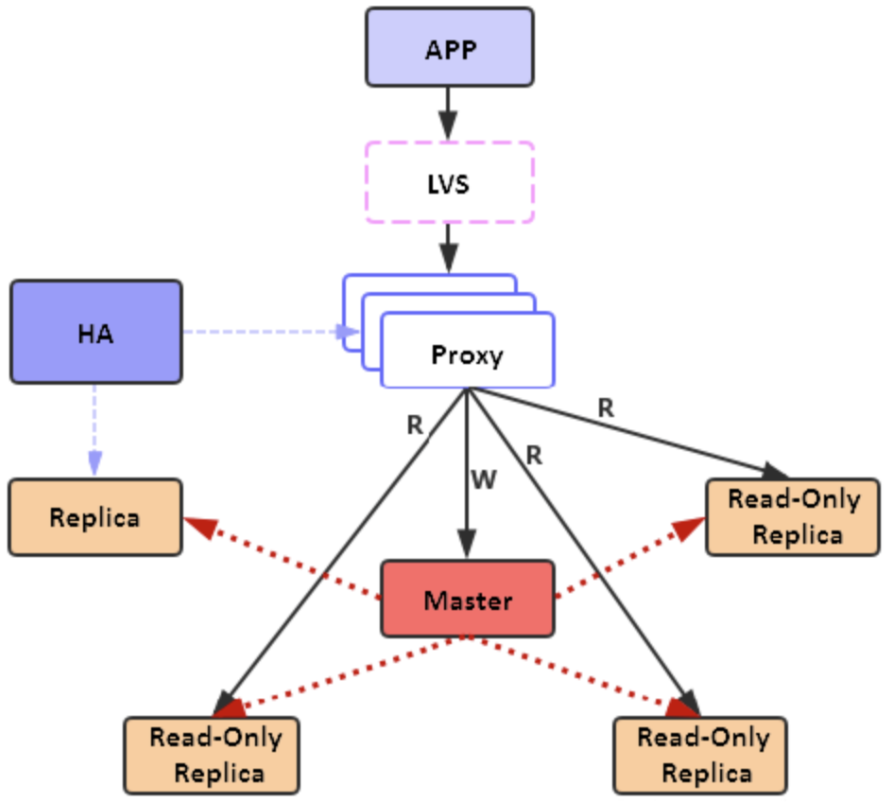
Redis是单进程单线程模型,主从之间的数据复制也在主线程中处理,read-only replica数量越多,数据同步对master的CPU消耗就越严重,集群的写入性能会随着read-only replica的增加而降低。此外,星型架构会让master的出口带宽随着read-only replica的增加而成倍增长。Master上较高的CPU和网络负载会抵消掉星型复制延迟较低的优势,因此,星型复制架构会带来比较严重的扩展问题,整个集群的性能会受限于master。
链式复制
链式复制将所有的read-only replica组织成一个复制链,如下图所示,master只需要将数据同步给replica和复制链上的第一个read-only replica。
链式复制解决了星型复制的扩展问题,理论上可以无限增加read-only replica的数量,随着节点的增加整个集群的性能也可以基本上呈线性增长。
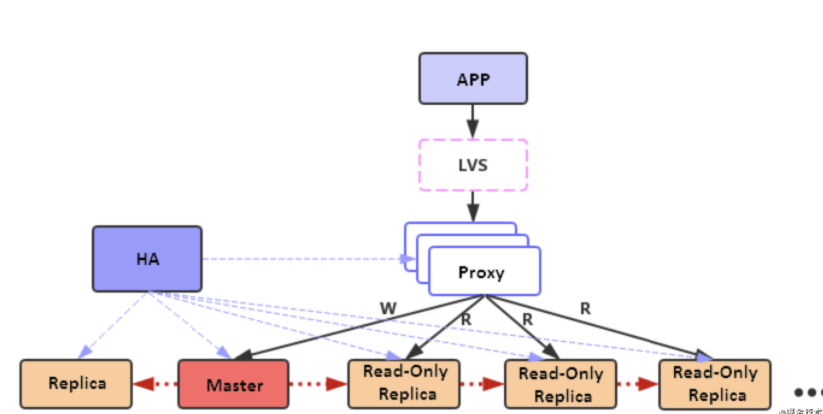
链式复制的架构下,复制链越长,复制链末端的read-only replica和master之间的同步延迟就越大,考虑到读写分离主要使用在对一致性要求不高的场景下,这个缺点一般可以接受。但是如果复制链中的某个节点异常,会导致下游的所有节点数据都会大幅滞后。更加严重的是这可能带来全量同步,并且全量同步将一直传递到复制链的末端,这会对服务带来一定的影响。为了解决这个问题,读写分离的Redis都使用阿里云优化后的binlog复制版本,最大程度的降低全量同步的概率。
更多关于Redis技术栈的学习,可以关注民工哥技术之路公众号,在 Redis专栏 中查看相关的技术文章、面试题及答案,非常详细,持续更新中。
Redis读写分离优势
透明兼容
读写分离和普通集群规格一样,都使用了redis-proxy做请求转发,多分片令使用存在一定的限制,但从主从升级单分片读写分离,或者从集群升级到多分片的读写分离集群可以做到完全兼容。
用户和redis-proxy建立连接,redis-proxy会识别出客户端连接发送过来的请求是读还是写,然后按照权重作负载均衡,将请求转发到后端不同的DB节点中,写请求转发给master,读操作转发给read-only replica(master默认也提供读,可以通过权重控制)。
用户只需要购买读写分离规格的实例,直接使用任何客户端即可直接使用,业务不用做任何修改就可以开始享受读写分离服务带来的巨大性能提升,接入成本几乎为0。
高可用
高可用模块(HA)监控所有DB节点的健康状态,为整个实例的可用性保驾护航。master宕机时自动切换到新主。如果某个read-only replica宕机,HA也能及时感知,然后重搭一个新的read-only replica,下线宕机节点。
除HA之外,redis-proxy也能实时感知每个read-only replica的状态。在某个read-only replica异常期间,redis-proxy会自动降低这个节点的权重,如果发现某个read-only replica连续失败超过一定次数以后,会暂时屏蔽异常节点,直到异常消失以后才会恢复其正常权重。
redis-proxy和HA一起做到尽量减少业务对后端异常的感知,提高服务可用性。可以参考:Redis低成本高可用方案
高性能
对于读多写少的业务场景,直接使用集群版本往往不是最合适的方案,现在读写分离提供了更多的选择,业务可以根据场景选择最适合的规格,充分利用每一个read-only replica的资源。
目前单shard对外售卖1 master + 1/3/5 read-only replica多种规格(如果有更大的需求可以提工单反馈),提供60万QPS和192 MB/s的服务能力,在完全兼容所有命令的情况下突破单机的资源限制。后续将去掉规格限制,让用户根据业务流量随时自由的增加或减少read-only replica数量。

Redis主从异步复制,从read-only replica中可能读到旧的数据,使用读写分离需要业务可以容忍一定程度的数据不一致,后续将会给客户更灵活的配置和更大的自由,例如配置可以容忍的最大延迟时间。
作者:小热爱
来源:juejin.cn/post/6955355686108659726













