
UDT协议是一个用于在高速Internet上传输大量数据的基于UDP的可靠传输协议。
我们可以将UDT协议的实现看作一个比较复杂的状态机。更准确的说,是一个主状态机,外加多个子状态机。主状态机是指协议实现中全局唯一、全局共享的状态与数据结构,主要对应于CUDTUnited类。子状态机则是对于一次UDT连接或一个Listening的UDT Server的抽象,是UDT自己创建的Socket抽象,一个与系统socket相似但又不同的概念,主要对应于CUDTSocket和CUDT类。UDT的Socket又可以分为3类,分别是Listening socket,read socket和write socket。尽管实际存在3种类型的socket,它们却都是由相同的几个类来表示的,但在这几个类中,它们却又都有着自己特有的数据结构/状态。
后面我们将主要用状态机的 网络协议分析方法 来分析UDT。具体而言,会主要从如下的一些方面来分析:
1. 这个协议定义了多少种类型的网络消息,每种消息的具体格式是什么?
2. 主要的一些动作具体的执行过程,比如建立连接,断开连接,心跳,丢失数据包的信息反馈等:
(1). 这些动作发起方和接受方各需要传递多少消息,传递什么类型的消息?各个消息的具体含义是什么?每条消息中具体携带了些什么信息,每种信息的含义又是什么?每条消息都是在什么时间点发送的?
(2). 动作执行过程中发送的每一条消息对于主状态机的影响有哪些?它会促使主状态机的状态作什么样的转换?
(3). 动作执行过程中发送的每一条消息对于相关联的具体的一个子状态机有何种影响?它会促使子状态机的状态作什么样的转换?
3. 协议层面提供了多少接口,即主状态机提供的public的,给调用者使用的接口都有哪些,比如startup,shutdown,newSocket,listen等。对于这些接口的调用会对主状态机的状态产生什么样的影响,会促使主状态机的状态作什么样的转换?
对于这些接口的调用是否会影响到子状态机?如果会,又会影响哪些,一个还是多个,对于相应的子状态机的状态有些什么样的影响,会促使它们作什么样的状态改变?
4. Socket(即子状态机)提供给用户调用的接口有哪些?对每个接口的调用对子状态机的影响是什么?会促使子状态机的状态作什么样的转换?
对于这些接口的调用是否会影响到主状态机?如果会,又是什么样的影响?会促使主状态机的状态作什么样的转换?
5. 状态机的激励源:
(1). 提供给调用者调用的接口。
(2). 从网络中传递进来的消息。
(3). 状态机内部起的一些定时执行的Task或其它的线程等。
UDT的初始化与销毁
这里从UDT全局初始化及销毁的部分开始分析。也就是主状态机的状态变化。
在调用UDT库提供的任何功能之前,需要首先调用UDT namespace的startup()函数来对这个库做初始化。UDT::startup()函数具体的执行过程如下(src/api.cpp):
int CUDTUnited::startup() {
CGuard gcinit(m_InitLock);
if (m_iInstanceCount++ > 0)
return 0;
// Global initialization code
#ifdef WIN32
WORD wVersionRequested;
WSADATA wsaData;
wVersionRequested = MAKEWORD(2, 2);
if (0 != WSAStartup(wVersionRequested, &wsaData))
throw CUDTException(1, 0, WSAGetLastError());
#endif
//init CTimer::EventLock
if (m_bGCStatus)
return true;
m_bClosing = false;
#ifndef WIN32
pthread_mutex_init(&m_GCStopLock, NULL);
pthread_cond_init(&m_GCStopCond, NULL);
pthread_create(&m_GCThread, NULL, garbageCollect, this);
#else
m_GCStopLock = CreateMutex(NULL, false, NULL);
m_GCStopCond = CreateEvent(NULL, false, false, NULL);
DWORD ThreadID;
m_GCThread = CreateThread(NULL, 0, garbageCollect, this, 0, &ThreadID);
#endif
m_bGCStatus = true;
return 0;
}
int CUDT::startup() {
return s_UDTUnited.startup();
}
namespace UDT {
int startup() {
return CUDT::startup();
}
UDT::startup()的调用过程为:UDT::startup()-> CUDT::startup() -> CUDTUnited::startup()。
这个地方我们可以看一下,在UDT中定义全局数据结构管理类——CUDTUnited类对象的方法。从语义上来说,CUDTUnited类对象应该是全局唯一的,通常可以用singleton模式来实现这种全局性和唯一性,或者在类外定义一个static的对象也可以。但在UDT中,考虑到CUDTUnited类并不会被导出给用户作为接口进行直接调用,而只是会作为UDT实现的一部分,因此不需要担心调皮的用户会破坏封装性;同时,CUDTUnited类提供的接口主要是给CUDT调用的,因而被定义为了CUDT类的private static成员变量(src/core.h):
private:
static CUDTUnited s_UDTUnited; // UDT global management base
另外我们可以看一下UDT中,类成员变量的命名方式:
1. 最开头是一个小写字母,表示变量的作用域,比如s表示静态成员变量static,m表示类非静态成员变量member等。
2. 第二个字符是下划线。
3. 在下划线之后,是0个、一个、两个或三个小写字母,表示变量的数据类型。如果是类(结构)类型变量,没有这个部分。其它一些常见的用于表示变量数据类型的小写字符/字符串有,i表示int整型值,b表示bool值,p表示指针类型,ll表示int64_t型值,ull表示uint64_t型值等。
4. 之后则是驼峰方式表示的一个描述变量含义的字符串。
最后,再来具体看一下实际执行初始化的CUDTUnited::startup()函数。在CUDTUnited中用m_iInstanceCount来记录UDT被引用的次数,每一次调用CUDTUnited::startup()函数时,这个数会被加一,而在调用CUDTUnited::cleanup()函数时,这个数会被减一,以避免重复的初始化,并在UDT没有被任何部分使用到时执行最终的销毁动作。这也就要求UDT的使用者,一定要成对地调用UDT::startup()和UDT::cleanup()。
1. CUDTUnited::startup()函数会首先增加m_iInstanceCount,并检查其值,若m_iInstanceCount在递增前的大于0,表明UDT已经被初始化过了,直接返回,否则,继续执行后面的初始化动作。
2. 检查m_bGCStatus的值,若该值为true,表明UDT已经被初始化,而无需再做进一步的动作,直接返回,为false,则继续执行初始化。
3. 设置m_bClosing为false,以指示GC线程的状态。CUDTUnited构造函数中会将此值设置为false,但执行UDT::cleanup()结束时,该值为false。
4. 初始化用于停掉GC线程的mutex和condition,然后创建并执行GC线程CUDTUnited::garbageCollect(void* p)。
5. 设置m_bGCStatus为true,以表明UDT的GC线程已经启动,UDT已可用,然后返回0。
看完了UDT的初始化过程,再来看UDT的销毁过程,也就是UDT::cleanup():
int CUDTUnited::cleanup() {
CGuard gcinit(m_InitLock);
if (--m_iInstanceCount > 0)
return 0;
//destroy CTimer::EventLock
if (!m_bGCStatus)
return 0;
m_bClosing = true;
#ifndef WIN32
pthread_cond_signal(&m_GCStopCond);
pthread_join(m_GCThread, NULL);
pthread_mutex_destroy(&m_GCStopLock);
pthread_cond_destroy(&m_GCStopCond);
#else
SetEvent(m_GCStopCond);
WaitForSingleObject(m_GCThread, INFINITE);
CloseHandle(m_GCThread);
CloseHandle(m_GCStopLock);
CloseHandle(m_GCStopCond);
#endif
m_bGCStatus = false;
// Global destruction code
#ifdef WIN32
WSACleanup();
#endif
return 0;
}
int CUDT::cleanup() {
return s_UDTUnited.cleanup();
}
int cleanup() {
return CUDT::cleanup();
}
销毁过程完全是初始化过程的逆过程。调用过程为UDT::cleanup() -> CUDT::cleanup() -> CUDTUnited::cleanup()。在CUDTUnited::cleanup()中:
1. 递减m_iInstanceCount,并检查其值,若m_iInstanceCount在递减后仍然大于0,表明UDT已还存在其它的使用者,直接返回,否则,继续执行后面的销毁动作。
2. 检查m_bGCStatus的值,若该值为false,表明UDT已经被销毁,而无需再做进一步的动作,直接返回,为true,则继续执行销毁动作。
3. 设置m_bClosing为true,以指示GC线程逐步退出执行。然后signal GCStopCond,以便于在GC线程休眠的时唤醒GC线程。
4. 等待GC线程执行结束,然后销毁用于停掉GC线程的mutex和condition。
5. 设置m_bGCStatus为false,以表明UDT的GC线程已经被销毁,UDT已不可用,然后返回0。
总结一下,UDT主状态机的描述与状态变化。在CUDTUnited类中,主要用如下的这几个变量来描述主状态机的状态(src\api.h):
private:
volatile bool m_bClosing;
pthread_mutex_t m_GCStopLock;
pthread_cond_t m_GCStopCond;
pthread_mutex_t m_InitLock;
int m_iInstanceCount; // number of startup() called by application
bool m_bGCStatus; // if the GC thread is working (true)
pthread_t m_GCThread;
#ifndef WIN32
static void* garbageCollect(void*);
#else
static DWORD WINAPI garbageCollect(LPVOID);
#endif
std::map<UDTSOCKET, CUDTSocket*> m_ClosedSockets; // temporarily store closed sockets
void checkBrokenSockets();
void removeSocket(const UDTSOCKET u);
可以发现,依赖于GC线程的状态,UDT主状态机主要有4个状态,分别是INIT,STARTING,RUNNING和CLOSING,在UDT中,主要用m_bGCStatus和m_bClosing这两个bool类型值来描述。这个状态机只提供了两个函数给调用者,以影响这个状态机的状态,也就是UDT::startup()和UDT::cleanup()函数。这个状态机的几个状态与m_bGCStatus和m_bClosing值的对应关系,及状态转换过程如下图所示:
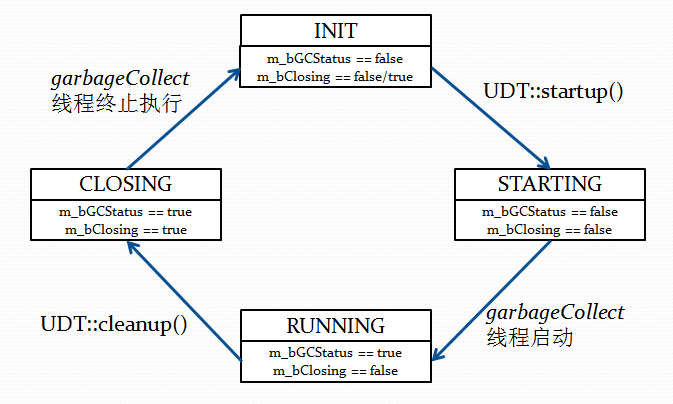
在使用UDT的程序启动起来时,或者执行了UDT::cleanup()函数之后,可以认为UDT处于INIT状态,也就是初始状态。在CUDTUnited的构造函数中,会将m_bGCStatus和m_bClosing这两个值都初始化为false,而UDT::cleanup()函数结束时,m_bGCStatus的值则为false,m_bClosing的值为true。
调用了UDT::startup()之后,m_bGCStatus的值仍然为false,m_bClosing的值首先被设置为false,然后启动garbageCollect线程。garbageCollect线程的启动需要一定的时间,在这段时间内可以认为UDT主状态机从INIT状态转换到了STARTING状态。
UDT::startup()会等待garbageCollect线程启动,在garbageCollect线程启动之后,m_bClosing的值仍然为false,m_bGCStatus的值被设置为true,以表示UDT已经可用了。这里可以认为UDT主状态机从STARTING状态切换到了RUNNING状态。
在UDT主状态机进入RUNNING状态之前,用户是无法创建Sokcet的,也就是还没有任何的子状态机被创建,因而还无需考虑这些状态的转换对于子状态机的影响。
使用UDT传输了数据之后,需要调用UDT::cleanup()函数来做清理动作。
调用UDT::cleanup()之后,m_bGCStatus的值仍然为true,但m_bClosing的值首先被设置为true,garbageCollect线程也会被唤醒。这个时候garbageCollect的处理可能比较复杂,可能已经创建了多个Socket,而Socket所处的状态可能也多种多样,因而可能会耗费一些时间。在这段时间内,可以认为UDT主状态机由RUNNING状态转换为了CLOSING状态。这个状态转换会对还在使用的Socket的状态做一个强制的转换,也就是说这个转换对子状态机的状态有巨大的影响,但此处先不讨论这种影响。
UDT::cleanup()函数会等待garbageCollect线程清理结束。在garbageCollect线程结束之后,m_bGCStatus被设置为false,以表明UDT不可用。此时m_bGCStatus的值为false,m_bClosing的值为false。可以认为,UDT主状态机的状态由CLOSING状态又回到了INIT状态。
可见,UDT主状态机状态改变的激励源,主要有UDT::startup()函数,UDT::cleanup()函数,和garbageCollect线程的执行。
UDT::startup()和UDT::cleanup()函数中都同时检查了m_iInstanceCount和m_bGCStatus的值,这里似乎有点多余了。
Done。











