1.采样(随机的将数据分成30%和70%)
esproc

A4:A.sort(x)按照x对A进行排序,并取长度的30%
A5:差集得到剩下的70%
python:
import timeimport pandas as pd
import datetime
import numpy as np
import random
s = time.time()
data = pd.read_csv("C:/Users/Sean/Desktop/esproc_vs_python/EMPLOYEE_nan.txt",sep="\t")
row_no = pd.Series(range(data.shape[0]))
per_30_no = row_no.sample(frac=0.3)
per_70_no = row_no[~row_no.isin(per_30_no)]
data_per_30 = data.iloc[per_30_no,:]
data_per_70 = data.iloc[per_70_no,:]
print(data_per_30)
print(data_per_70)
e = time.time()
print(e-s)
pd.Series()得到所有行的行号
Series.sample()进行抽样,~表示逻辑非。最后通过iloc[]切片截取数据。
结果:
esproc


python



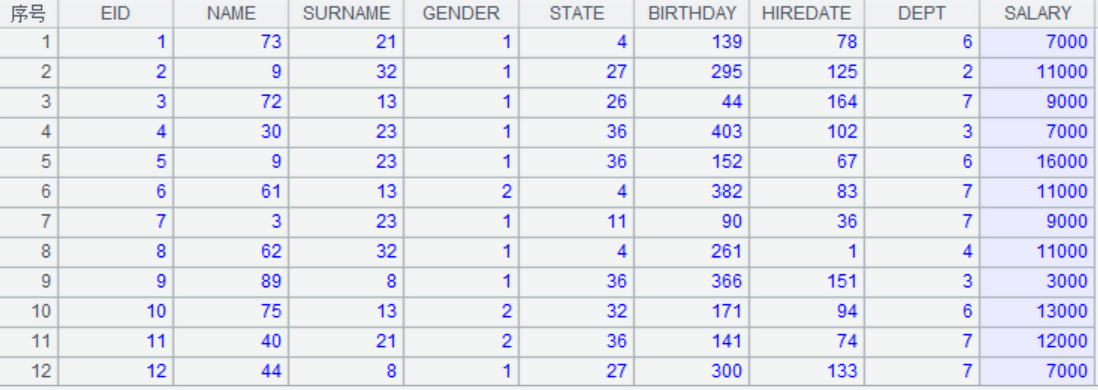
2.数字的字段不变,其他字段转换为数字
esproc

A4:A3(1).array()得到第一条记录的序列。r.ifnumber(~)判断记录中的字段是否是实数,如果是返回true,否则返回false;pselect@a()找到满足条件的序号组成序列
B5:分别按照字段分组
B6:A.run(xi)针对序列/排列A中每个成员计算表达式xi,计算过程中可能对A进行修改,最后返回修改后的A 。B5.#,表示当前的值。这里是用当前的组号修改原来的字段值。
python:
import timeimport pandas as pd
import datetime
import numpy as np
import random
s = time.time()
data = pd.read_csv("C:/Users/Sean/Desktop/esproc_vs_python/EMPLOYEE.txt",sep="\t")
class_mapping = {}
columns = data.columns
for column in columns:
try:
data[column] = data[column].apply(pd.to_numeric)
except ValueError:
lg = list(data.groupby(column))
class_mapping = {}
for i in range(len(lg)):
class_mapping[lg[i][0]]=i+1
data[column]=data[column].map(class_mapping)
print(data)
e = time.time()
print(e-s)
得到数据的字段序列;
pd.to_numric是将字符串化的数字(如‘1’,‘1.4’)转化成数字。
循环字段,尝试df.apply(pd.to_numric)将字段数字化。如果不能数字化,以该字段为key分组,形成该分组的字典。
最后利用df.map(dic)函数修改字段值为字典对应的数字。
结果:
esproc
python
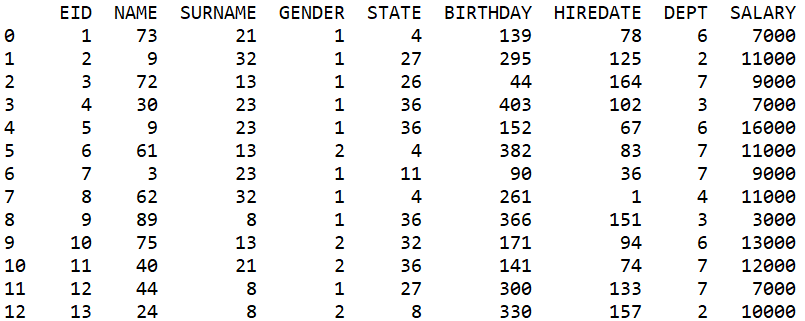

3. 用户重复听的音乐的时间求平均值
esproc

A4:T.groups(),将序表按照一个或多个字段/表达式进行分组聚合后,形成新序表,这里是按照user,music两个字段进行分组聚合,将listen_time字段求均值,作为新的listen_time.
python:
import timeimport pandas as pd
import datetime
import numpy as np
import random
s = time.time()
user_watch_data = pd.read_csv('C:/Users/Sean/Desktop/kaggle_data/music_project_data/user_watch1.csv')
u_i_watch_list = []
u_i_listen_m = user_watch_data.groupby(by=['user','music'],as_index=False).mean()
print(u_i_listen_m)
e = time.time()
print(e-s)
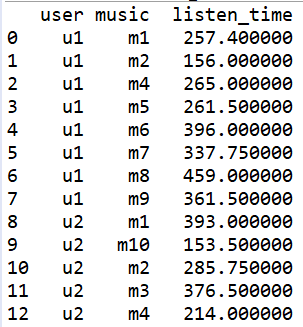
使用df.groupby(by,as_index),by参数代表需要分组的键,as_index参数代表是否将键当做索引,mean()函数代表求平均值
结果:
esproc
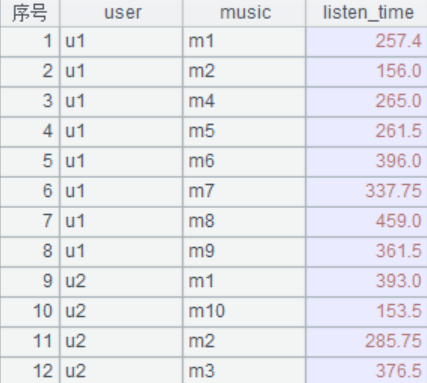
python

4. 用户重复听的音乐的时间求平均值后,按照music字段合并long字段,并用listen_time/long作为score字段
esproc

A5:T.keys()设置主键。
A7:T.join(C,T2:k,x)用序表T的字段C匹配序表/排列T2的键k找到相应记录,在T上拼接T2中的表达式x作为字段F添加到T上形成新序表。new()新建序表,用user,music,score作为字段
python:
import timeimport pandas as pd
import datetime
import numpy as np
import random
s = time.time()
user_watch_data = pd.read_csv('C:/Users/Sean/Desktop/kaggle_data/music_project_data/user_watch1.csv')
music_meta_data = pd.read_csv('C:/Users/Sean/Desktop/kaggle_data/music_project_data/music_meta1.csv')
u_i_watch_list = []
u_i_listen_m = user_watch_data.groupby(by=['user','music'],as_index=False).mean()
data_merge = pd.merge(u_i_listen_m,music_meta_data,on='music')
data_merge['score'] = data_merge['listen_time']/data_merge['long']
u_i_s_data = data_merge[['user','music','score']]
print(u_i_s_data)
e = time.time()
print(e-s)
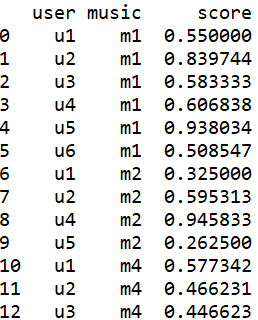
pd.merge(df1,df2,on),这里是以music作为键来合并df1和df2.
结果:
esproc
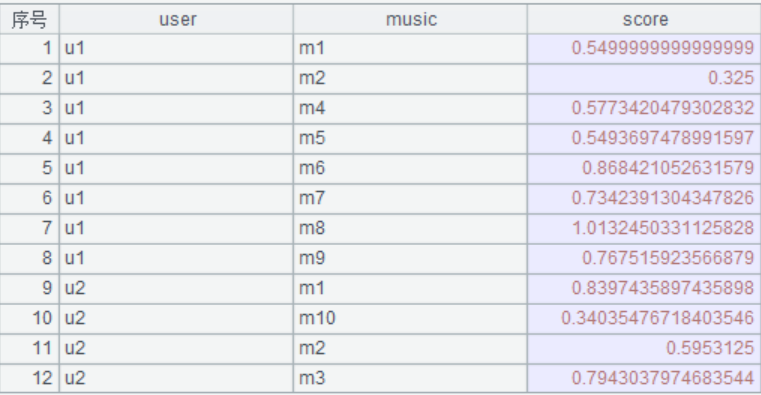
python

5. music作为索引,user作为字段,score作为分数,产生透视表
Esproc
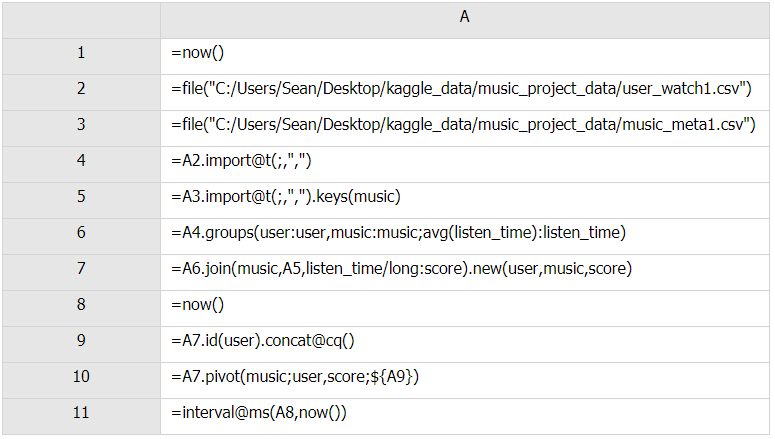
A8:从这里计算时间。
A9:A.concat(d)用分隔符d连接A中成员返回成字符串,并处理子序列。d省略时将成员直接连起来。@c选项表示用逗号连接,相当于A.concat(“,”),@q选项串成员接入时加上引号,缺省不会处理
C10: A.pivot(g,…;F,V;Ni:N'i,…) 以字段/表达式g为组,将每组中的以F和V为字段列的数据转换成以Ni和N'i为字段列的数据,以实现行和列的转换。Ni缺省为F中的不重复字段值,N'i缺省为Ni。
python:
import timeimport pandas as pd
import numpy as np
import random
user_watch_data = pd.read_csv('C:/Users/Sean/Desktop/kaggle_data/music_project_data/user_watch1.csv')
music_meta_data = pd.read_csv('C:/Users/Sean/Desktop/kaggle_data/music_project_data/music_meta1.csv')
u_i_watch_list = []
u_i_listen_m = user_watch_data.groupby(['user','music'],as_index=False).mean()
data_merge = pd.merge(u_i_listen_m,music_meta_data,on='music')
data_merge['score'] = data_merge['listen_time']/data_merge['long']
u_i_s_data = data_merge[['user','music','score']]
s = time.time()
u_i_s_data = pd.pivot_table(u_i_s_data,index = 'music',columns='user',values='score')
print(u_i_s_data)
e = time.time()
print(e-s)
使用pd.pivot_table(df,index,columns,values)生成透视表。
结果:
esproc

python


小结:本节我们对数据进行处理,包含了数据的采样、合并、计算、产生透视表,在处理过程中,esproc分步显示结果的优势就体现出来了,每对数据进行处理一步,我们就可以清晰的查看结果,而不必像python那样每次都要print()一下。这里想吐槽一下,esproc中没有提供查看字段类型的函数,这带来了一些麻烦,但没有更好的办法,因为esproc是泛型的,它支持同一列的数据类型不一样,不支持判定单一类型字段的类型。