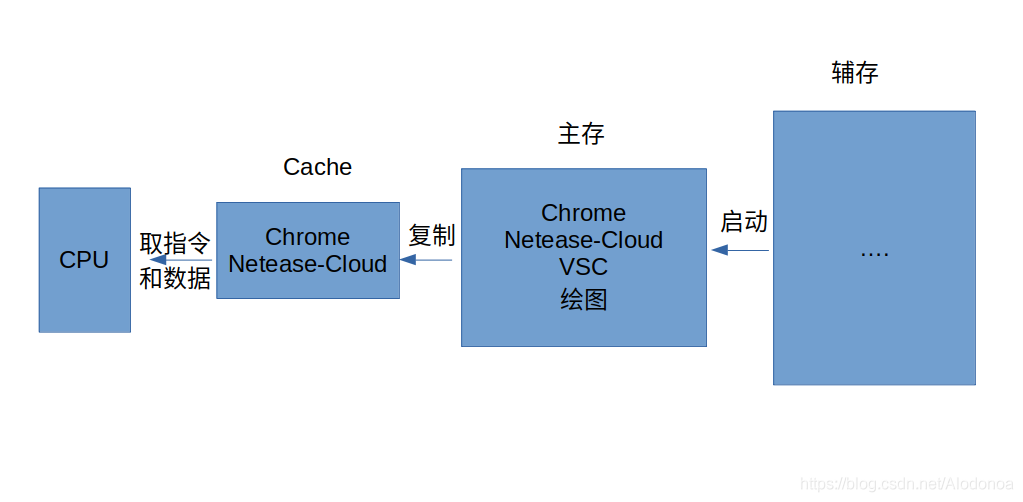
3.7.1虚拟存储器概念
3.7.2页式存储器
主存和Cache之间是分块映射存储,同样,利用局部性原理,也可以将主存和辅存之间进行分块映射存储。
举个粒子,假如现在使用微信文字聊天,该部分程序占用大小了4KB的空间,那么可以分为大小位1KB的四块,分别映射存储到主存中。如下图,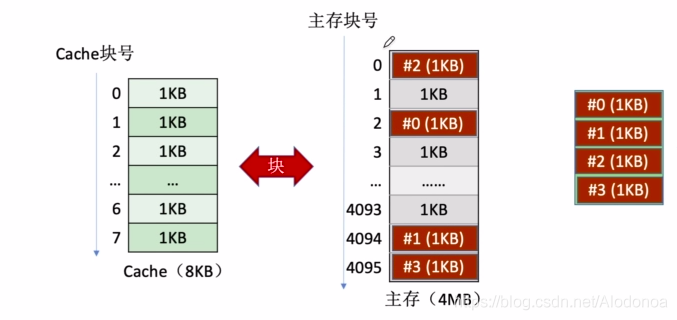 分页式存储,在这个问题中就是把程序进程逻辑上大小相等的四块页面,每个页面大小与主存块大小相等,可以离散的存储到主存块中。
那么,4KB的程序被拆分成四块存储到主存后,要如何执行该程序呢?这个问题留到3.7.3.3部分来回答。
分页式存储,在这个问题中就是把程序进程逻辑上大小相等的四块页面,每个页面大小与主存块大小相等,可以离散的存储到主存块中。
那么,4KB的程序被拆分成四块存储到主存后,要如何执行该程序呢?这个问题留到3.7.3.3部分来回答。
3.7.3页式虚拟存储器
3.7.3.1页表
虚拟存储,如上文提到的微信文字聊天,假设微信程序大小1GB,主存大小只有512MB,在文字聊天时候不需要把全部的微信程序相关数据调入到主存,只调入需要的4KB,剩余的空间可以继续调用其他程序进程,512MB大小的主存可以运行许多个1GB的程序,这就是虚拟存储。
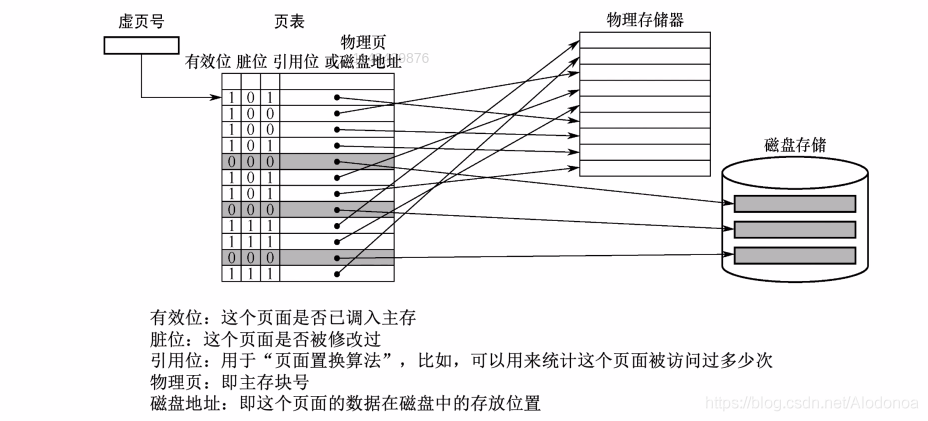
关于分页式虚拟存储,依然借用学习讲义里的图片,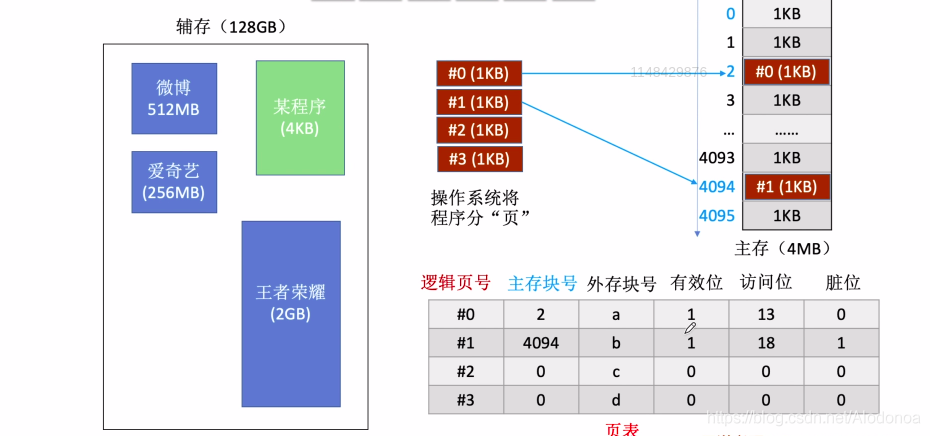 逻辑页号:记录程序数据在逻辑地址的哪一块地址页中。
主存块号:记录程序数据在主存储器的哪一块主存中,与逻辑页号有映射关系。
外存块号:记录程序数据在辅存的哪一块。
有效位:初始化位0,记录某一块程序数据所在的逻辑页面是否被调用到主存中,若是为1,若否为0。
访问位:初始化为0,记录某块程序数据被访问的次数,用访问位帮助实现页面替换,需要替换时优先淘汰访问位记录数较小的。
脏位:初始化为0,发生数据修改时变为1。
逻辑页号:记录程序数据在逻辑地址的哪一块地址页中。
主存块号:记录程序数据在主存储器的哪一块主存中,与逻辑页号有映射关系。
外存块号:记录程序数据在辅存的哪一块。
有效位:初始化位0,记录某一块程序数据所在的逻辑页面是否被调用到主存中,若是为1,若否为0。
访问位:初始化为0,记录某块程序数据被访问的次数,用访问位帮助实现页面替换,需要替换时优先淘汰访问位记录数较小的。
脏位:初始化为0,发生数据修改时变为1。
举个粒子,假设要访问逻辑页号为1的数据,则从页表中找到对应的对应逻辑页号,有效位是1,则直接根据映射访问主存块号位2的主存块,并且访问位+1。假设访问逻辑页号为3的数据,根据页表找到逻辑页号,有效位是0,主存中没有数据,则需要到辅存中找到外存块号为d的存储块,将数据调入到主存中,有效位修改为1,访问位+1;若对该块数据进行修改,则脏位0变1,这一块数据被替换掉时,需要把数据写入辅存。 这一部分主存和辅存的关系,与Cache和主存的关系类似。
3.7.3.2快表(TLB)
与Cache和主存的关系类似,利用程序局部性原理,访问的某块数据,如上文的4KB程序进程,可能会在未来一段时间内继续访问。将刚访问过的页表复制一份,放入用SRAM制作的更高速存储器中,后续将逻辑地址转换成物理地址时直接访问快表。与Cache类似,快表也需要替换算法,这需要学习OS才能明白。
3.7.3.3关于页式虚拟存储器执行过程
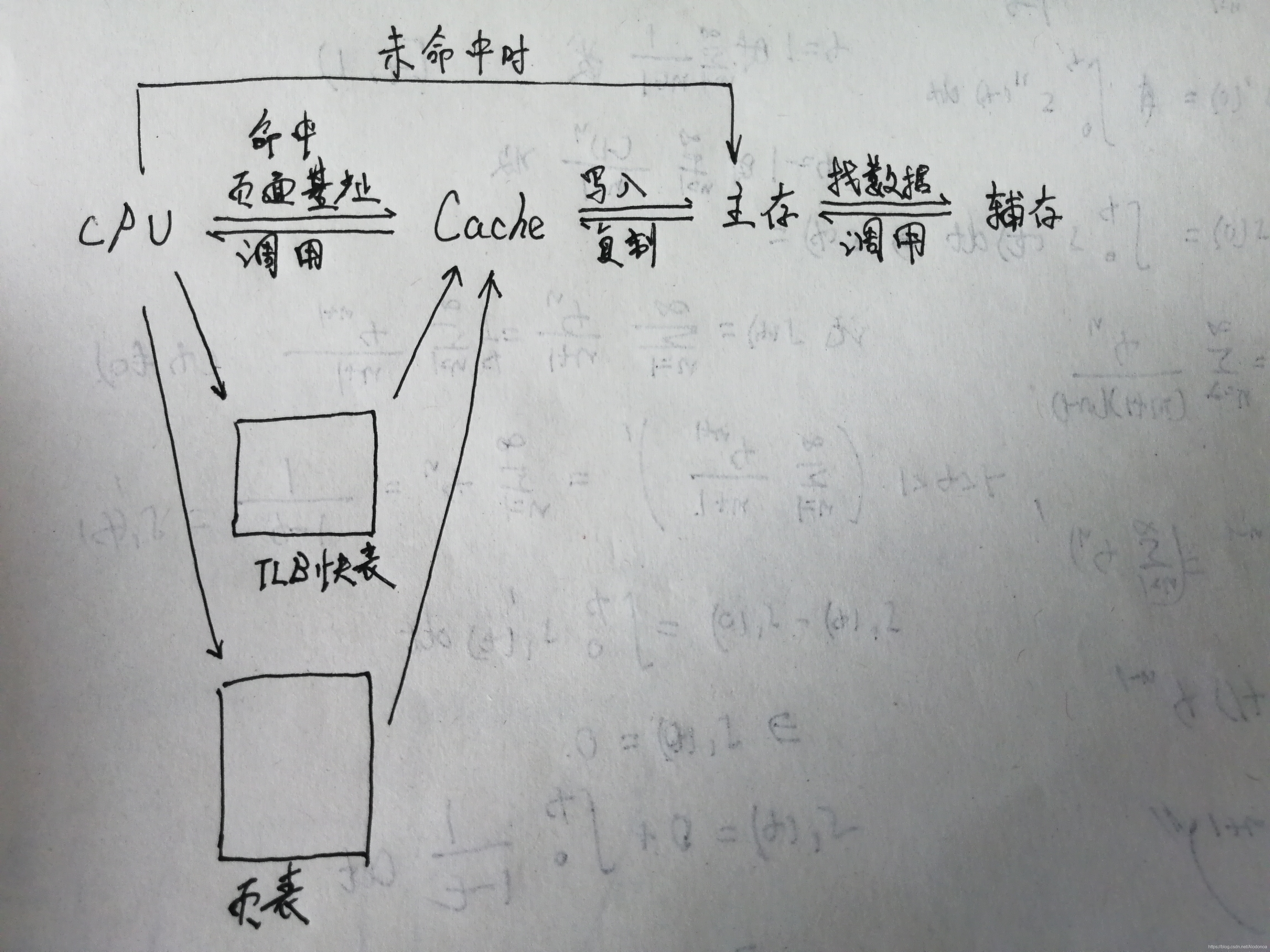
先把关于页表的详细工作流程贴上来。
 这里需要先了解一个定义,页表基址寄存器。CPU中,每一个进程都有一个页表基址寄存器,存储相应进程的页表首地址,页表首地址对于页表相当于数组首地址对于数组的关系。
这里需要先了解一个定义,页表基址寄存器。CPU中,每一个进程都有一个页表基址寄存器,存储相应进程的页表首地址,页表首地址对于页表相当于数组首地址对于数组的关系。
举个粒子,假设一台小型计算机,Cache为8KB,主存为4MB,辅存为1GB。要调用4KB=2^12^B的聊天小程序,程序中有一个变量X的逻辑地址是001000000011。
现在需要其中的2KB=2^11^B文字聊天进程,CPU中页表基址寄存器寻找页表,根据页表将程序逻辑地址转换成物理地址,根据物理地址同时从Cache和主存中寻找,由于是第一次调用该程序,因此Cache未名中,因此CPU会继续到主存中寻找,从辅存中把所需数据调用到主存,再把2KB的数据从主存复制一个数据副本到Cache中,提供CPU调用程序。下图是整体流程,
 题目中已知4KB数据,假设分成大小相同的四块逻辑页面,其中2KB被调用,4MB主存块号的块内地址和逻辑页面的页内地址,地址长度相同,因此逻辑页面和块内地址的详细分配分别是,
题目中已知4KB数据,假设分成大小相同的四块逻辑页面,其中2KB被调用,4MB主存块号的块内地址和逻辑页面的页内地址,地址长度相同,因此逻辑页面和块内地址的详细分配分别是,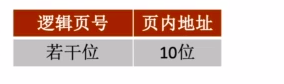
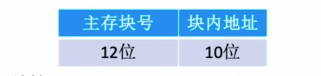 题目中已知001000000011是程序变量X的逻辑地址,逻辑页面的页内地之长度为10位,因此逻辑地址后10位存入逻辑页面,前两位00作为页号。主存块的块内地址与逻辑页面的页内地之是一样的,因此根据主存块块号与页内地址拼接出最终需要的物理地址。
题目中已知001000000011是程序变量X的逻辑地址,逻辑页面的页内地之长度为10位,因此逻辑地址后10位存入逻辑页面,前两位00作为页号。主存块的块内地址与逻辑页面的页内地之是一样的,因此根据主存块块号与页内地址拼接出最终需要的物理地址。
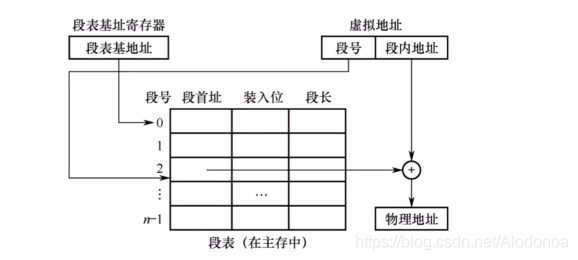
3.7.4段式虚拟存储器
段式虚拟存储的具体实现需要在OS中学习,这里不再赘述。
3.7.5关于Cache和虚拟存储器的比较
虚拟存储由主存和辅存完成,需要操作系统和硬件共同完成,Cache由硬件实现。 虚拟存储器解决存储容量不足的问题,Cache解决CPU和主存速度部匹配的问题。 两者的替换算法思想相同,且有依据了程序局部性原理,两者都有价格、容量、速度的梯度。