原文链接:https://ethsonliu.com/2018/04...
一:背景
SPFA(Shortest Path Faster Algorithm)算法,是西南交通大学段凡丁于 1994 年发表的,其在 Bellman-ford 算法的基础上加上一个队列优化,减少了冗余的松弛操作,是一种高效的最短路算法。
二:算法过程
设立一个队列用来保存待优化的顶点,优化时每次取出队首顶点 u,并且用 u 点当前的最短路径估计值dist[u]对与 u 点邻接的顶点 v 进行松弛操作,如果 v 点的最短路径估计值dist[v]可以更小,且 v 点不在当前的队列中,就将 v 点放入队尾。这样不断从队列中取出顶点来进行松弛操作,直至队列空为止。(所谓的松弛操作,简单来说,对于顶点 i,把dist[i]调整更小。更多解释请参考百科:松弛操作)
而其检测负权回路的方法也很简单,如果某个点进入队列的次数大于等于 n,则存在负权回路,其中 n 为图的顶点数。
三:代码
#include <iostream>
#include <queue>
#include <stack>
using namespace std;
int matrix[100][100]; // 邻接矩阵
bool visited[100]; // 标记数组
int dist[100]; // 源点到顶点 i 的最短距离
int path[100]; // 记录最短路的路径
int enqueue_num[100]; // 记录入队次数
int vertex_num; // 顶点数
int edge_num; // 边数
int source; // 源点
bool SPFA()
{
memset(visited, 0, sizeof(visited));
memset(enqueue_num, 0, sizeof(enqueue_num));
for (int i = 0; i < vertex_num; i++)
{
dist[i] = INT_MAX;
path[i] = source;
}
queue<int> Q;
Q.push(source);
dist[source] = 0;
visited[source] = 1;
enqueue_num[source]++;
while (!Q.empty())
{
int u = Q.front();
Q.pop();
visited[u] = 0;
for (int v = 0; v < vertex_num; v++)
{
if (matrix[u][v] != INT_MAX) // u 与 v 直接邻接
{
if (dist[u] + matrix[u][v] < dist[v])
{
dist[v] = dist[u] + matrix[u][v];
path[v] = u;
if (!visited[v])
{
Q.push(v);
enqueue_num[v]++;
if (enqueue_num[v] >= vertex_num)
return false;
visited[v] = 1;
}
}
}
}
}
return true;
}
void Print()
{
for (int i = 0; i < vertex_num; i++)
{
if (i != source)
{
cout << source << " 到 " << i << " 的最短距离是:" << dist[i] << ",路径是:" << i;
int t = path[i];
while (t != source)
{
cout << "--" << t;
t = path[t];
}
cout << "--" << source << endl;
}
}
}
int main()
{
cout << "请输入图的顶点数,边数,源点:";
cin >> vertex_num >> edge_num >> source;
for (int i = 0; i < vertex_num; i++)
for (int j = 0; j < vertex_num; j++)
matrix[i][j] = (i != j) ? INT_MAX : 0; // 初始化 matrix 数组
cout << "请输入 " << edge_num << " 条边的信息:\n";
int u, v, w;
for (int i = 0; i < edge_num; i++)
{
cin >> u >> v >> w;
matrix[u][v] = w;
}
if (SPFA())
Print();
else
cout << "存在负权回路!\n";
return 0;
}运行如下:
/* Test 1 */
请输入图的顶点数,边数,源点:5 7 0
请输入 7 条边的信息:
0 1 100
0 2 30
0 4 10
2 1 60
2 3 60
3 1 10
4 3 50
0 到 1 的最短距离是:70,路径是:1--3--4--0
0 到 2 的最短距离是:30,路径是:2--0
0 到 3 的最短距离是:60,路径是:3--4--0
0 到 4 的最短距离是:10,路径是:4--0
/* Test 2 */
请输入图的顶点数,边数,源点:4 6 0
请输入 6 条边的信息:
0 1 20
0 2 5
3 0 -200
1 3 4
3 1 4
2 3 2
存在负权回路!四:判断负权回路的证明
如果某个点进入队列的次数大于等于 n,则存在负权回路。为什么偏偏是 n?
对于一个不存在负权回路的图,设其顶点数为 n,我们把图稍微“转换”下,如下图 A:

- 与源点 0 邻接的点{ 1, 2, 3 }作为第一批次;
- 与第一批次邻接的点{ 4, 5, 6, 7, 8, 9 }作为第二批次;
- ......
- 与第 k-1 批次邻接的点{ ...... }作为第k批次。
其中 k≤n-1,当 k=n-1 时,即为上图 B。
每操作完一个批次的点,至少有一个点的最短路径被确定。这里读者只需从 Dijkstra 算法方面来考虑即可。Dijkstra 每次循环都找出dist[]里的最小值,可以对应到这里的每个批次。
一个不存在负权回路的图,最多有 n-1 个批次,每做完一个批次至少有一个点的最短路径被确定,即一个点的入队次数不超过 n-1。因为若一个顶点要入队列,则必存在一条权值之和更小的路径,而在最多做完 n-1 个批次后,所有顶点的最短路径都被确定。(这里需要注意的是,如果一个批次中,有多条路径对某顶点进行更新,则该顶点只会被入队一次,这从代码就可以看出)
五:时间复杂度
对于一个不存在负权回路的图,我们假设其顶点数为 n,边数为 m。
引自 SPFA 论文:考虑一个随机图,运用均摊分析的思想,每个点的平均出度为 $O(\frac m n)$,而每个点的平均入队次数为 2,因此时间复杂度为 $O(n⋅\frac m n⋅2)=O(2m)=O(m)$。
关于上述的“平均入队次数为 2”,2 这个数字从何得来,我也找不到证明,从网上各位朋友对此的一致态度:尚待商榷。但是可以确定的是,SPFA 算法在随机图中的平均性能是优于 Bellman_Ford 算法的。
SPFA 的最佳时间复杂度为 $O(n)$。比如上图 B,每个点只入队一次。
接着再看下 SPFA 的最差时间复杂度,它发生在一个完全图中,如下图(为突出重点,其余边未画出),
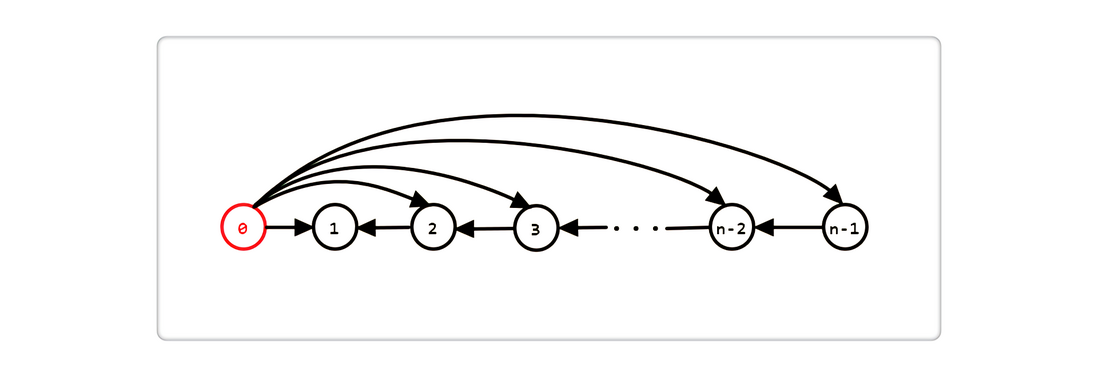
我们约定,0 点为源点,每次更新完 k 点出队后,k+1 点都可以再次对 k 点进行更新并入队,其中。1≤ k≤ n-2 那么我们得出:
0 点,入队 1 次;
1 点,入队 n-1 次;
2 点,入队 n-2 次;
3 点,入队 n-3 次;
.
n-2 点,入队 2 次;
n-1 点,入队 1 次;
因为是完全图,所以每个点的出度为 n-1,因此总的时间复杂度为:
$$ (n-1)⋅[1+1+2+3+...+(n-2)+(n-1)]=O(n^3) $$
由于是完全图,也可以表达成 $O(nm)$。很容易看出,SPFA 算法的时间复杂度很不稳定。