
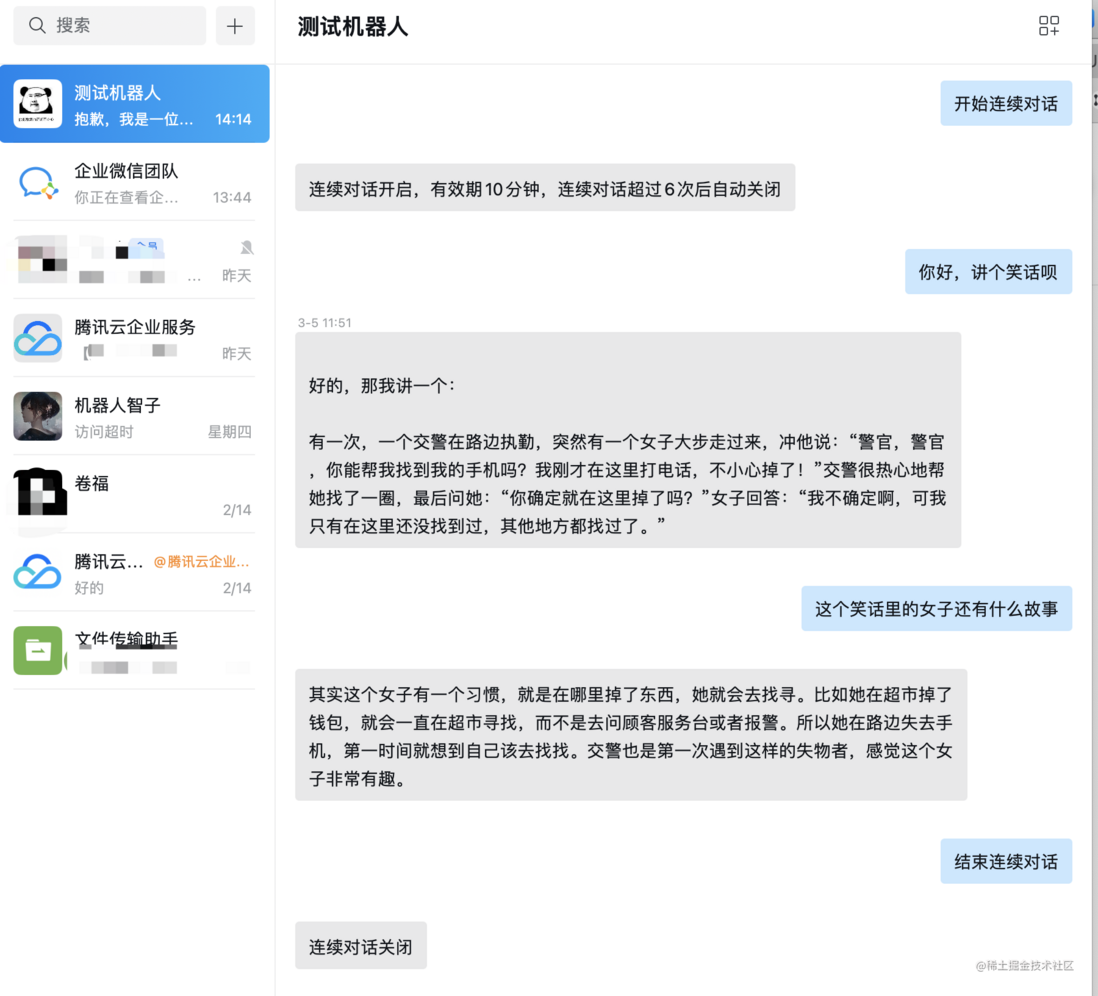
1.连续对话效果
小伙伴们,这周OpenAI放出大招,开放了GPT3.5的API。说简单点,就是提供了和GPT页面对话一样模型的接口。而之前接的GPT接口都是3.0,并不是真正的GPT。废话少说,先来看看效果,这次最大的不同是能连续对话了
2.准备工作
这次更新之后,国内服务器已没法直接访问openai的接口,需要自己买个国外的服务器。
- 一台海外服务器(服务器上安装Java8,操作系统选Ubuntu,如果用windows,要自己研究)
- 注册好的企业微信
- 有额度的OpenAI账号,并创建了账号的API key
- 我的项目代码,代码下载:号众公
小白技术圈,发关键词L008获取
3.企业微信
3.1添加机器人
注册不多说了,自己搞定。添加自建应用操作如下:
PC端登录地址:https://work.weixin.qq.com/wework_admin/frame#apps
先登录创建好的企业微信账号
然后添加自建应用
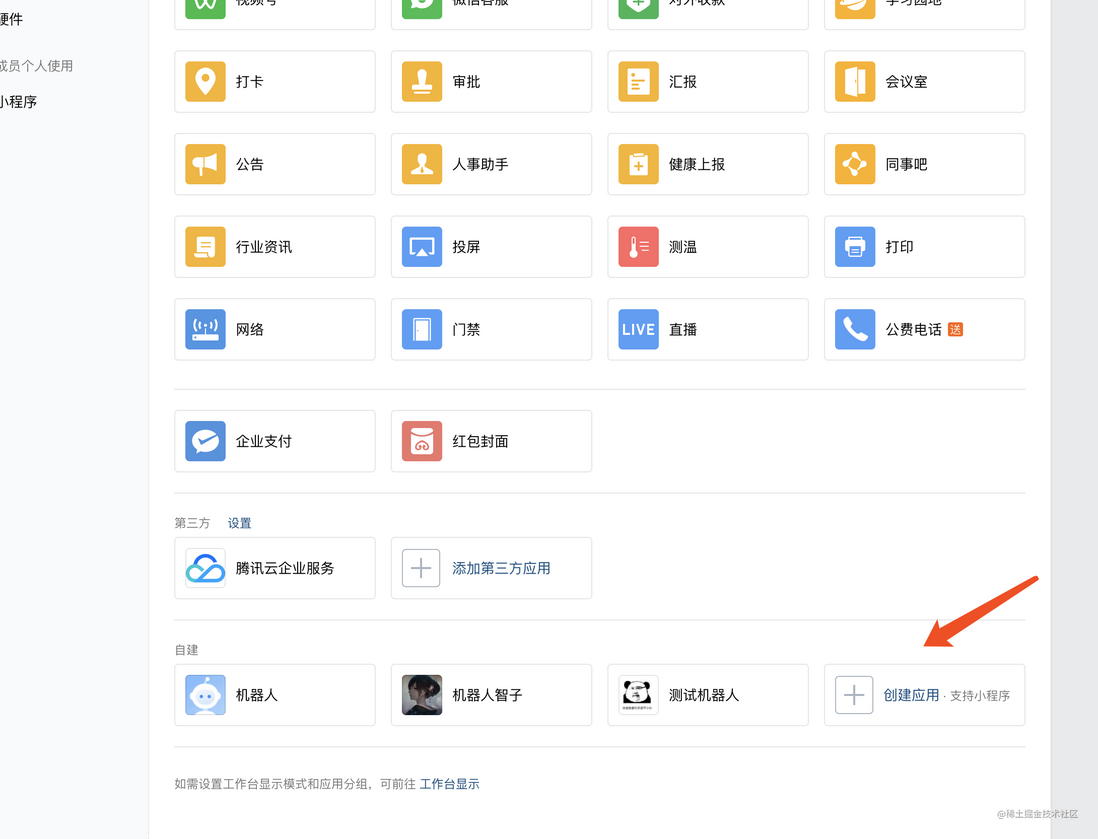
填写名称、上传logo图片,创建应用。
3.2设置API接收
这一步比较复杂,操作讲细点
3.2.1 获取token、EncodingAESKey、企业ID、应用配置
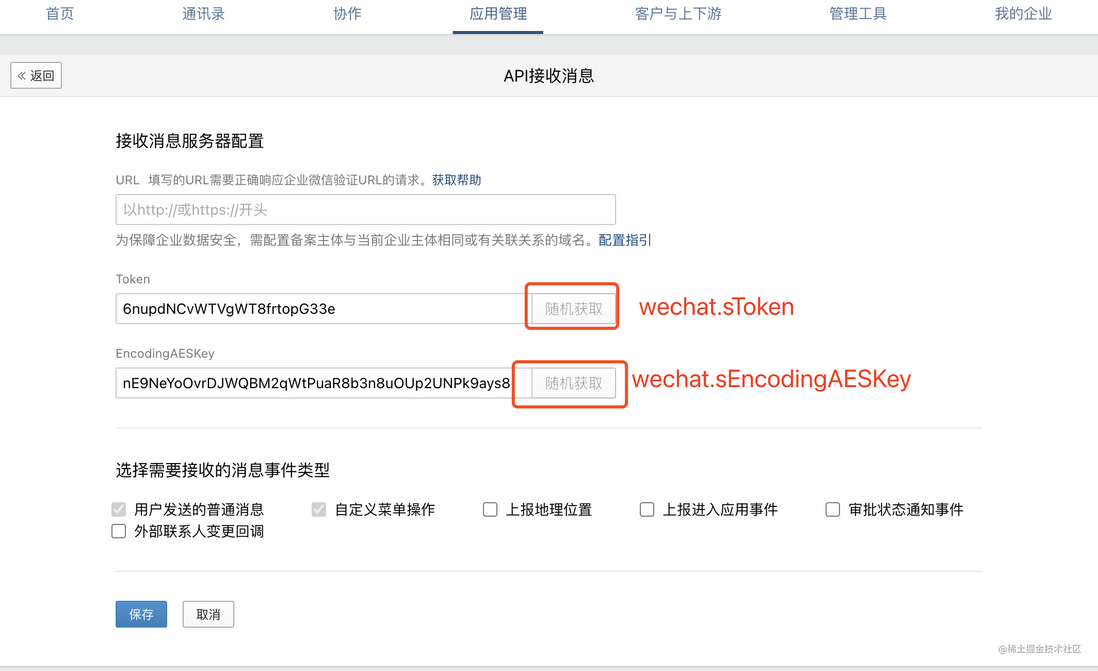
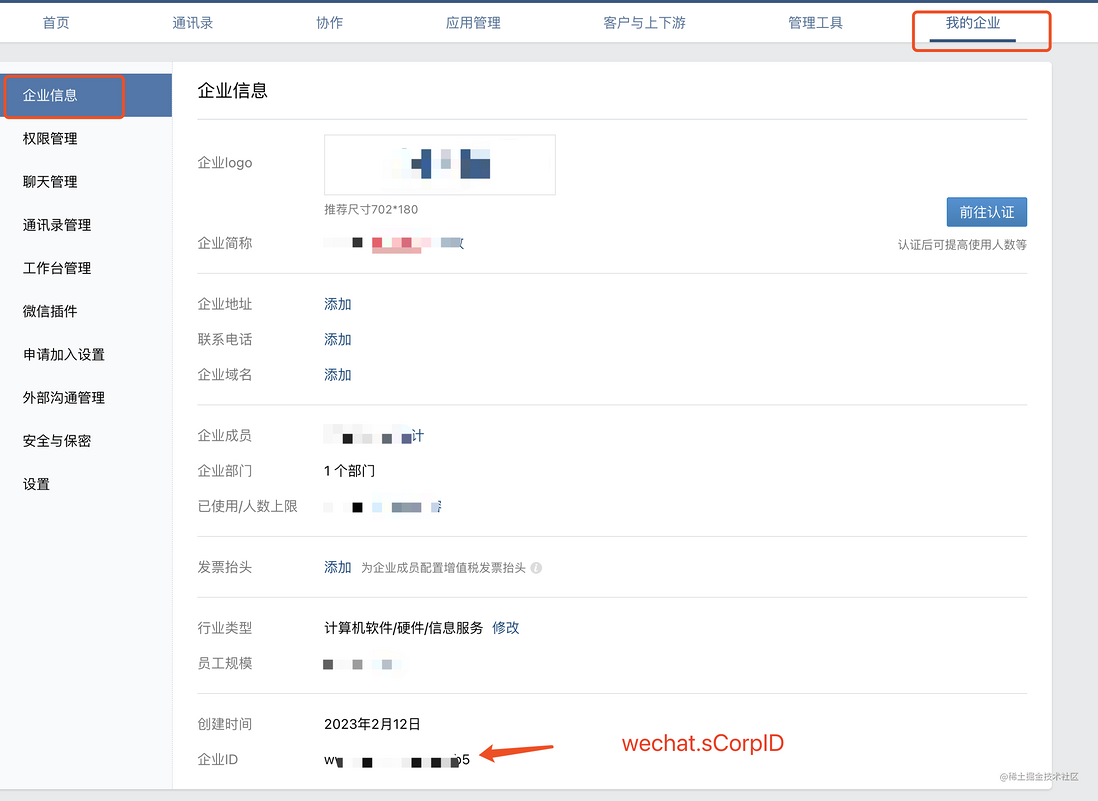
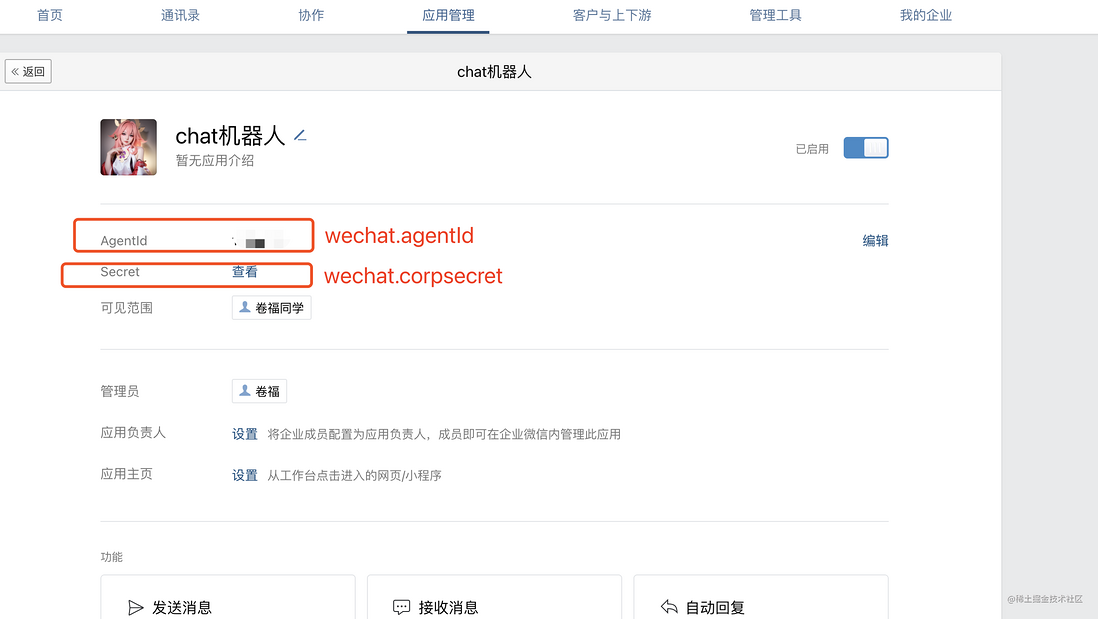
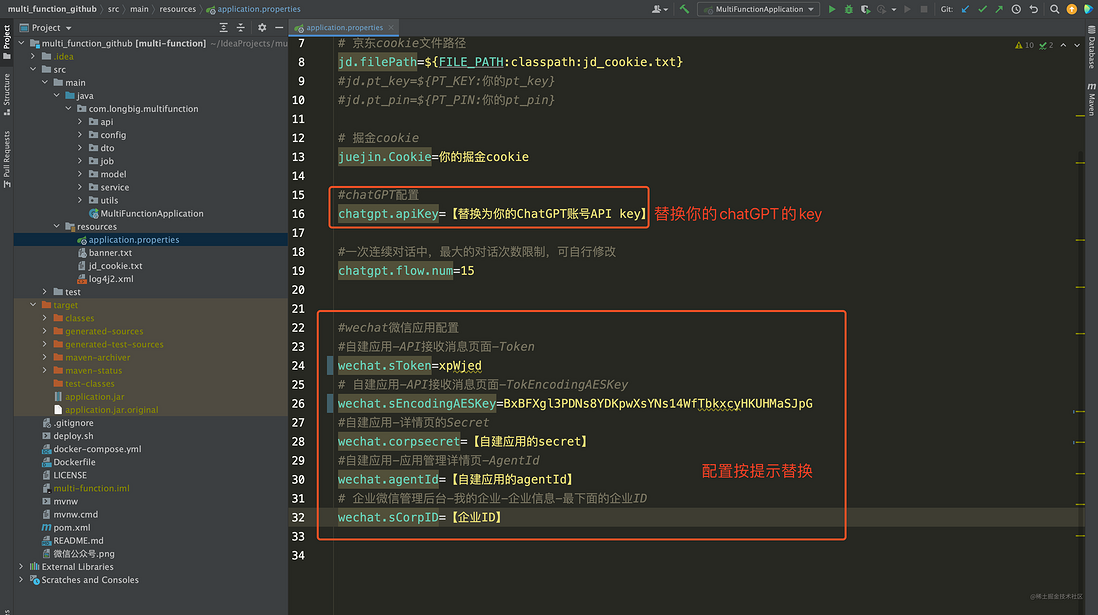
这一步我随机生成这两个字段的值,只作为文章里演示啊,图上标注了项目代码里需要改的配置名称。拿到上面5个信息后,替换代码里的对应的5个字段
chatGPT的账号API key自行创建,不会的可以搜索找找
3.2.3 发布应用到海外服务器
配置修改完后,可通过IDEA右上角的maven功能打包,或是在项目目录下运行mvn package命令打包,打包完成后,会在项目的target目录下得到一个application.jar文件
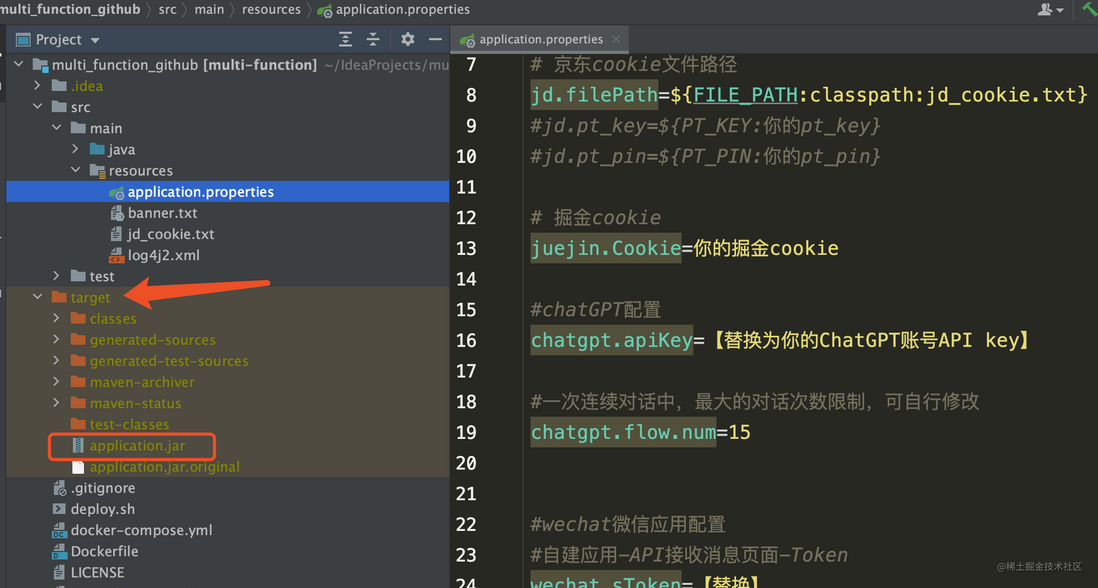
通过ssh命令登录你的海外服务器,有不会的可自行百度或是看阿里云上面服务器的登录方式文档远程连接Linux服务器
接着服务器上运行rz命令(如没有,按系统提示安装即可),上传application.jar文件。
最后通过nohup java -jar application.jar >log.txt &运行程序,效果如下
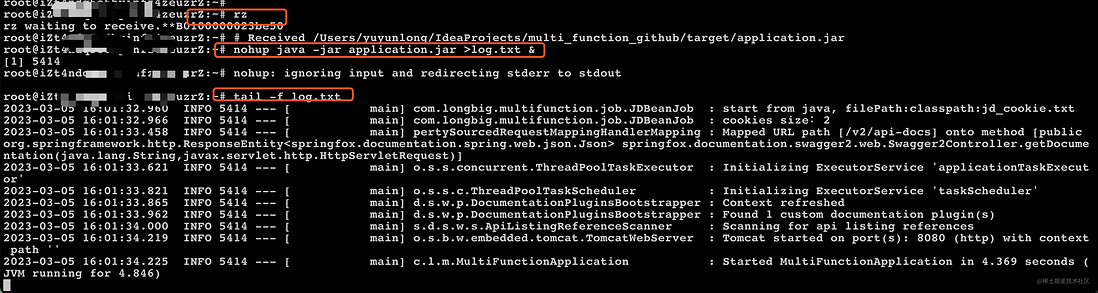
注意系统的运行端口是8080,服务器要配置防火墙白名单。
然后浏览器访问http://[你的服务器IP]:8080/receiveMsgFromWechat 出现Whitelabel Error Page字样的提示就说明启动成功了
3.2.4 启用API接收
我们找到配置API接收的页面,把上一步的让你在浏览器打开的URL填进去,然后点击保存,就完成配置了
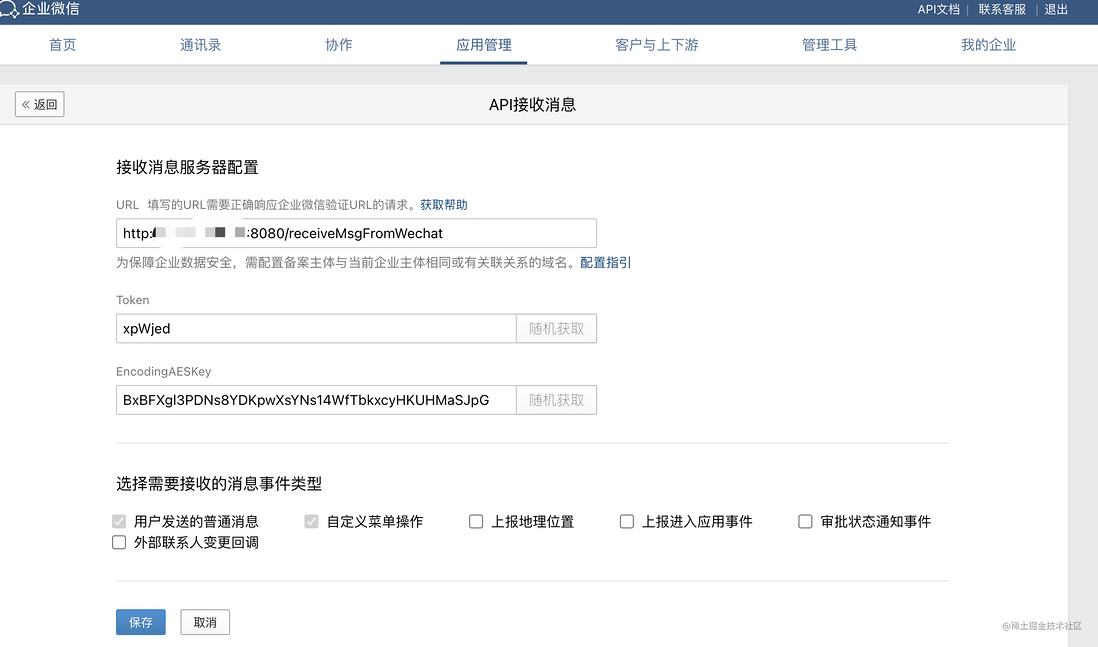
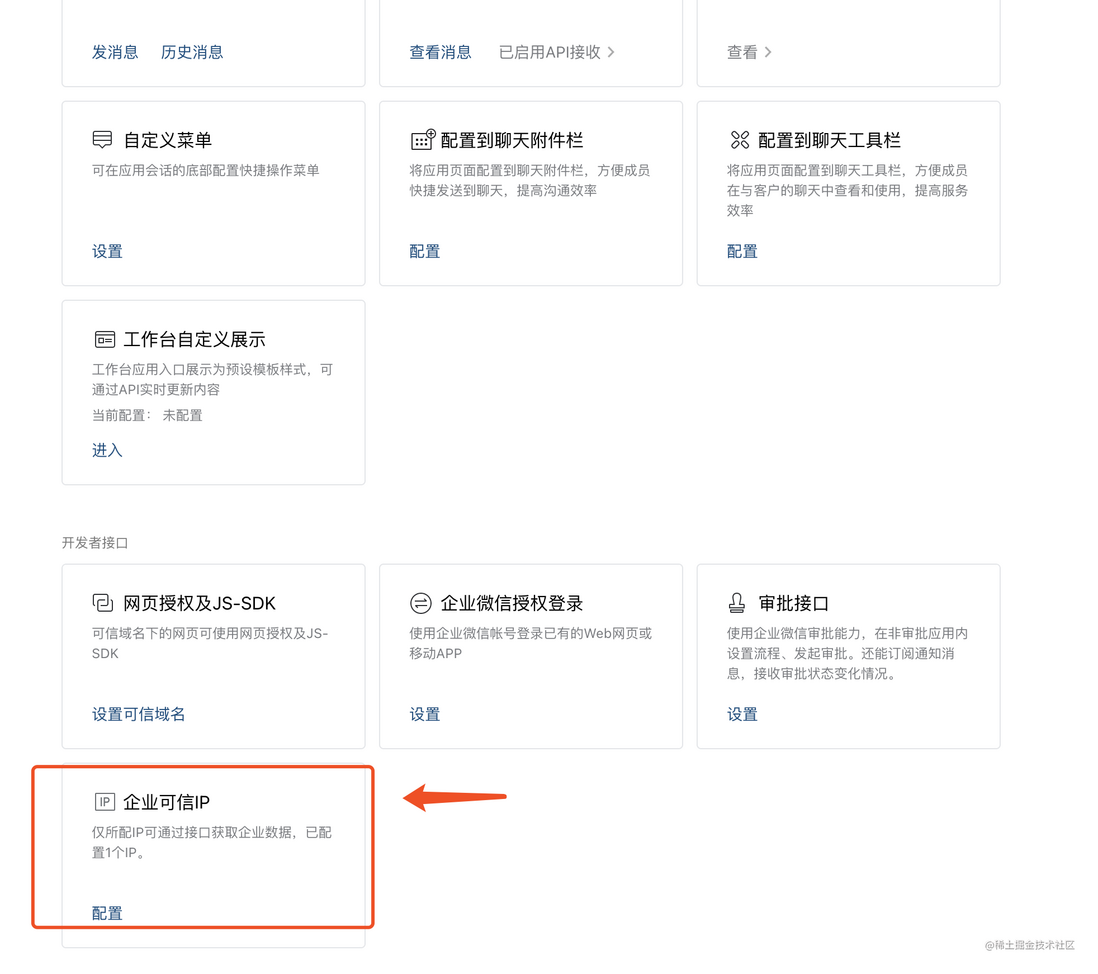
3.2.5 设置可信IP
最后把自己的IP加到可信IP里就大功告成了
4. 测试效果
发送开始连续对话即可进入连续对话模式,发送结束连续对话退出连续对话模式,连续对话次数限制可自行修改

目前这种方式适合小规模使用,如果需要大规模多人使用,整体的架构要重新设计哦~不过看到这篇文章并且想自己动手做的人,应该都是小规模用。












