
NoSQL从小白到码神
本课程适用于运维、开发相关人员。
课程目录:
- NoSQL背景
- NoSQL简介
- NoSQL和关系型数据库对比
- Redis简介
- Redis下载安装配置(Linux环境)
- Redis优点
- Redis性能
- Redis常见命令
- Redis数据类型
- Redis的功能
- Redis发布/订阅
- Redis事务支持
- Redis主从复制(集群)
- Redis持久化
- Java操作Redis示例
- Redis总结
- MongoDB简介
- MongoDB下载安装(Linux)
- MongoDB基本操作
- 体系结构
- 启动、停止数据库
- 连接数据库
- 增删改查操作
- 高级查询操作
- 数据备份、恢复
- 访问控制
- 索引
- Replica Sets
- 自动分片(Auto-Sharding)
- MongoDB常见命令
- MongoDB工具集
- MongoDB集群搭建
- MongoDB安全验证
- MongoDB应用场景
- Java操作MongoDB示例
- MongoDB总结
NoSQL篇
NoSQL背景
随着互联网Web网站的兴起,传统的关系数据库在应付Web网站,特别是超大规模和高并发的社交网络类型的Web纯动态网站已经显得力不从心,暴露出了很多难以克服的问题。例如:关系数据库为了降低数据冗余,保证数据约束性,在数据查询时不得不使用多个数据表之间的连接操作,这极大地降低了查询效率,不能够满足当前Internet的高实时性的要求。而非关系型数据库对并发的大规模访问有着效率上的优势,因此,非关系数据库是在具体应用背景下得到了迅速的发展。
NoSQL简介
NoSQL指的是非关系型的数据库。其实,NoSQL概念最早出现在1998年,当时的含义是反SQL技术革命运动,但并未引起太多的关注。直到2009年,NoSQL概念被来自Rackspace的EricEvans再次提出,这时的NoSQL已经不是单纯的反SQL运动,指的主要是非关系型的分布式数据库,并且不支持原子性(Atomicity)、一致性(Consistency)、隔离性(Isolation)、持久性(Durability)的数据库设计模式。在亚特兰大举行的有关NoSQL的讨论会上,学者给出了NoSQL较为普遍的解释,即“非关系型的”。并且指出Key-Value存储和文档数据库是NoSQL的主要特点。
原子性:
多个事情组成一个单元,要么同时成功或失败,不能只运行其中一个
一致性:
事务处理要将数据库从一种状态转变为另一种状态。一旦提交了修改数据,那么其它人读取这个数据,也是被修改后的数据
隔离性:
在事务处理提交之前,事务处理的效果不能由系统中其它事务处理。多个用户,不能同时读写同一个数据,应该有先后顺序,在数据库中是一个一 个事件地运行,如果事件的条件不满足,后续事件就回滚
持久性:
事件一旦提交成功,数据就发生了变化
例如:
网上定p系统,扣钱和定p是一个事务,它需要有原子性即不能只运行扣钱不运行定p。符合原子性。
这张p被多人同时在网上定,就会有先来的才定上这个p,后来定p的动作,如果发现p已卖出,(p的状态改变了,其它人通过网站访问这个数据,就会发现p已卖出符合一致性),就会回滚到不扣钱,p订不上的状态。符合隔离性。
p被定了,在数据库里设置标志位,它就一直显示为卖出状态。符合持久性
NoSQL特点
1:key-value存储
2:最终一致性
3:可拓展
NoSQL和关系型数据库对比
关系型数据库
优势:
1.擅长小数据量的处理
2.擅长复杂的SQL操作,可以进行Join等复杂查询
3.可以方便的生成各种数据对象,利用存储的数据建立窗体和报表,可视性好
劣势:
1.很难进行分布式应用和大量数据的写入处理
2.为有数据更新的表做索引和结构变更
3.字段不固定的应用
4.对简单查询需要快速返回结果的处理
NoSQL数据库
优势:
1.擅长大量数据的写入和读取
2.快速的查询响应,灵活的数据模型
3.数据结构变更或更新非常方便,不需要更改已有数据的数据结构
4.击碎了性能瓶颈,可以使执行速度变的更快
劣势:
1.不提供复杂的API接口
2.一般仅提供key索引
3.不适合小数据的处理
4.现有产品的不够成熟,大多数产品都还处于初创期
NoSQL 数据库分类

Redis篇
Redis简介
Redis(REmote DIctionary Server)是一个开源的使用ANSI C语言编写、是一个由Salvatore Sanfilippo写的key-value存储系统,支持网络、可基于内存亦可持久化的日志型、并提供多种语言的API。
Redis是一个key-value存储系统。和Memcached类似,它支持存储的value类型相对更多,包括string(字符串)、list(链表)、set(集合)、zset(sorted set --有序集合)和hash(哈希类型)。与memcached一样,为了保证效率,数据都是缓存在内存中。区别的是redis会周期性的把更新的数据写入磁盘或者把修改操作写入追加的记录文件,并且在此基础上实现了master-slave(主从)同步。
(Memcached 是一个高性能的分布式内存对象缓存系统,用于动态Web应用以减轻数据库负载。它通过在内存中缓存数据和对象来减少读取数据库的次数,从而提高动态、数据库驱动网站的速度。Memcached基于一个存储键/值对的hashmap。)
参考地址:http://www.runoob.com/redis/redis-conf.html
Redis下载安装配置(Linux环境)
下载:
官网:https://redis.io/
下载步骤:
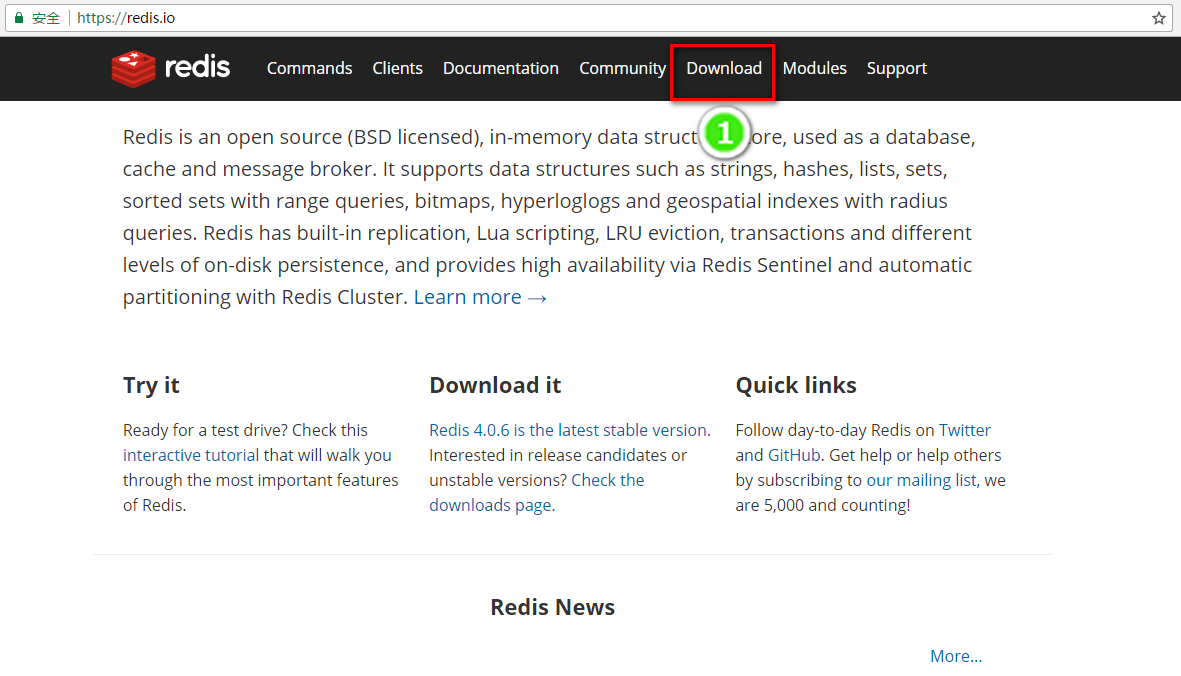
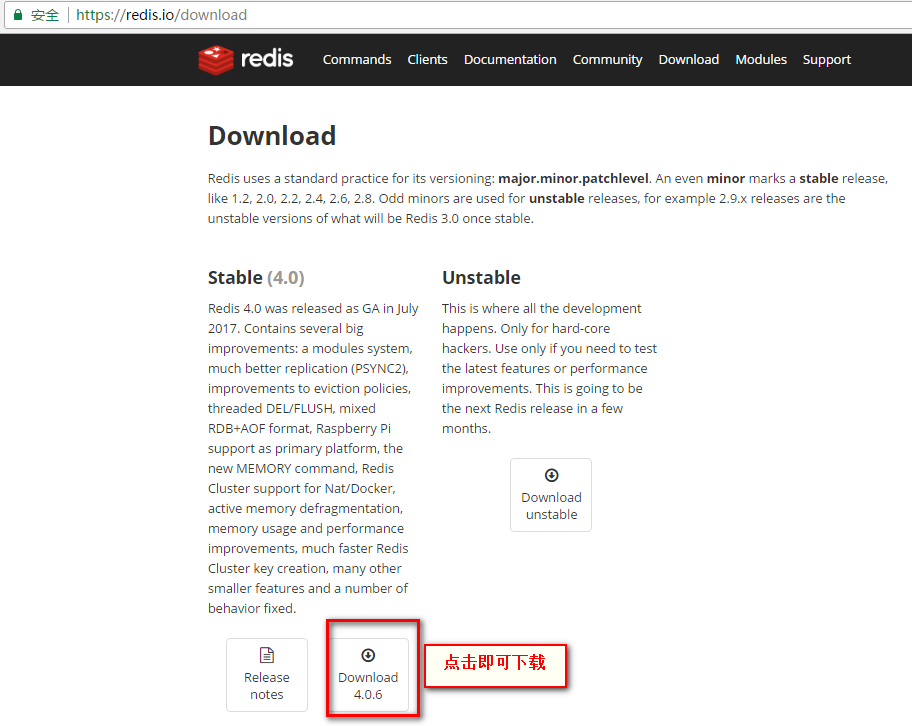
安装(Linux版本下CentOS Linux release 7.3.1611 (Core))
在线安装:
1:查看系统版本:
cat /etc/redhat-release

2:进入到opt目录下、创建redis文件夹:
cd /opt/
mkdir redis
3:进入/opt/redis/目录下,下载redis
wget http://download.redis.io/releases/redis-4.0.6.tar.gz

如果wget 未安装, 显示 未找到命令
需要到根目录下
cd /
yum install wget -y
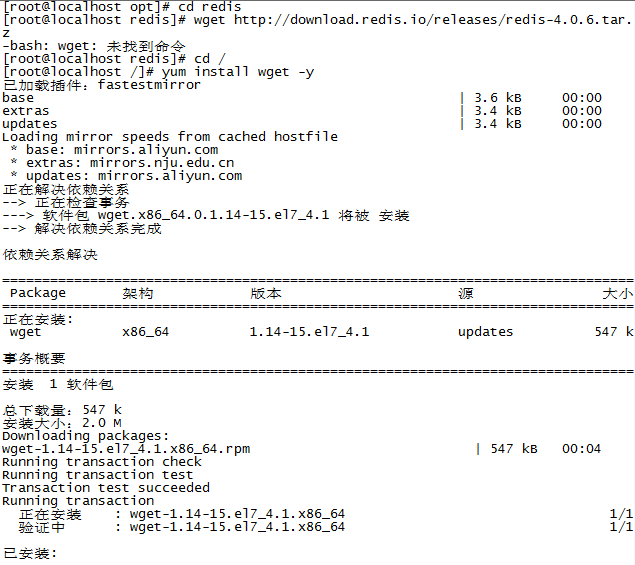
等待安装完成即可重复第3步
4:解压redis-4.0.6.tar.gz
tar -zvxf redis-4.0.6.tar.gz

5:在安装之前需要预装gcc、tcl
没有安装的小伙伴,需要安装,如果已经存在,则略过此步骤
回到根目录 cd/
查看安装gcc信息:
gcc -v
安装命令:
mount /dev/cdrom /mnt
yum install gcc tcl -y
6:执行redis安装
make
或者 make MALLOC=libc
7:切换到目录/usr下新建目录/usr/lksoft/redis
cd /usr
mkdir lksoft
cd lksoft
mkdir redis
8:重新设置PREFIX
切换到目录 cd /opt/redis/redis-4.0.6
make PREFIX=/usr/lksoft/redis/ install
9:查看当前系统中端口使用情况
ss -tanl

10:将redis设置成服务(配置环境变量)
cd ./opt/redis/redis-4.0.6/src
cp redis-sentinel /usr/lksoft/redis/bin/
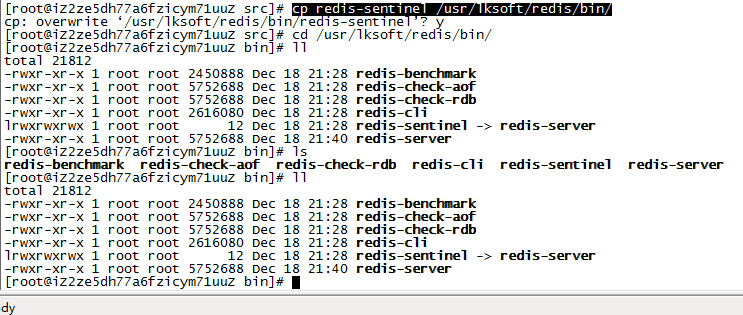
11:设置环境变量bash_profile
切换到根目录 cd /
vim ~/.bash_profile 或者 vi ~/.bash_profile

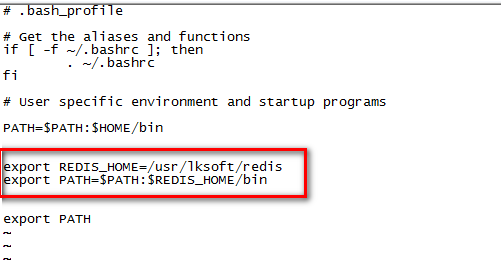
修改内容部分:
export REDIS_HOME=/usr/lksoft/redis
export PATH=$PATH:$REDIS_HOME/bin
使文件生效
source ~/.bash_profile
12:任何地方,都可以启动redis了
为了更说明,切换到根目录下
cd /
可以自动补全redis-server了
13:将redis启动程序做成服务
切换到之前的redis目录:
cd /opt/redis/redis-4.0.6/utils
./install_server.sh
提示是否使用默认的6379端口,点击回车即可,使用默认
Please select the redis port for this instance: [6379]
是否将redis的服务配置文件,放到[/etc/redis/6379.conf]下面,直接回车即可:
Please select the redis config file name [/etc/redis/6379.conf]
是否将redis服务的日志文件,放到[/var/log/redis_6379.log]下面,直接回车即可:
Please select the redis log file name [/var/log/redis_6379.log]
是否将redis的数据,存放到[/var/lib/redis/6379]下面,直接回车即可:
Please select the data directory for this instance [/var/lib/redis/6379]
是否默认redis可执行的文件路径为[/usr/lksoft/redis/bin/redis-server],直接回车即可
Please select the redis executable path [/usr/lksoft/redis/bin/redis-server]
然后显示的是设置的文件信息,直接回车即可。
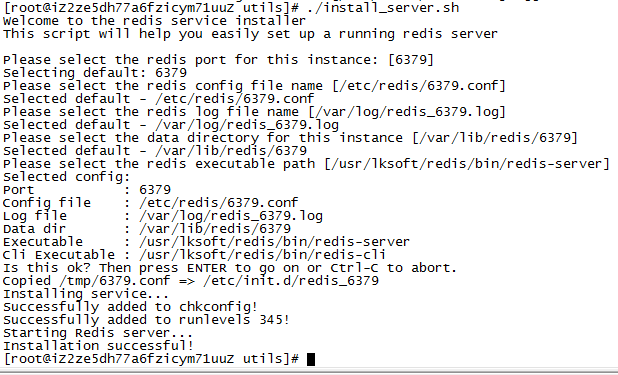
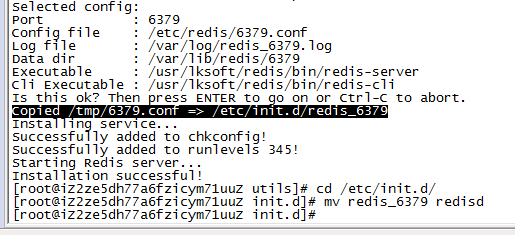
发现:Copied /tmp/6379.conf => /etc/init.d/redis_6379
14:修改启动的名称
cd /etc/init.d/
mv redis_6379 redisd
15:启动redis
service redisd start
发现已经启动
需要停止服务:
service redisd stop
重新启动
service redisd start
查看目前系统使用端口情况:
ss -tanl
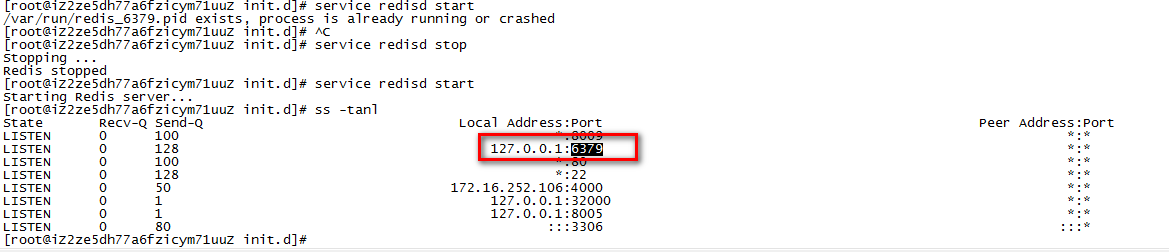
16:测试连接redis
切换到根目录
cd /
查看客户端连接帮助
redis-cli --help
连接0号库
redis-cli
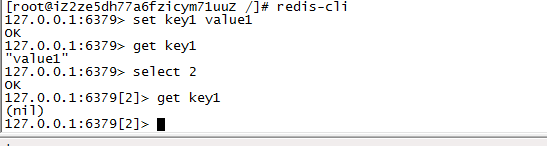
config get * 查看配置信息
Redis优点
- 性能极高 – Redis能读的速度是110000次/s,写的速度是81000次/s 。
- 丰富的数据类型 – Redis支持二进制案例的 Strings, Lists, Hashes, Sets 及 Ordered Sets 数据类型操作。
- 原子 – Redis的所有操作都是原子性的,意思就是要么成功执行要么失败完全不执行。单个操作是原子性的。多个操作也支持事务,即原子性,通过MULTI和EXEC指令包起来。
- 丰富的特性 – Redis还支持 publish/subscribe, 通知, key 过期等等特性。
- Redis支持数据的持久化,可以将内存中的数据保存在磁盘中,重启的时候可以再次加载进行使用。
- Redis支持数据的备份,即master-slave模式的数据备份。
Redis性能
在50个并发的情况下请求10W次,写的速度是11W次/s,读的速度是8.1w次/s
Redis常见命令
官网参考命令地址:https://redis.io/commands
菜鸟教程命令地址:http://www.runoob.com/redis
对value操作的命令
exists(key):确认一个key是否存在
del(key):删除一个key
type(key):返回值的类型
keys(pattern):返回满足给定pattern的所有key
randomkey:随机返回key空间的一个
keyrename(oldname, newname):重命名key
dbsize:返回当前数据库中key的数目
expire:设定一个key的活动时间(s)
ttl:获得一个key的活动时间
select(index):按索引查询
move(key, dbindex):移动当前数据库中的key到dbindex数据库
flushdb:删除当前选择数据库中的所有key
flushall:删除所有数据库中的所有key
对string操作的命令
set(key, value):给数据库中名称为key的string赋予值value
get(key):返回数据库中名称为key的string的value
getset(key, value):给名称为key的string赋予上一次的value
mget(key1, key2,…, key N):返回库中多个string的value
setnx(key, value):添加string,名称为key,值为value
setex(key, time, value):向库中添加string,设定过期时间time
mset(key N, value N):批量设置多个string的值
msetnx(key N, value N):如果所有名称为key i的string都不存在
incr(key):名称为key的string增1操作
incrby(key, integer):名称为key的string增加integer
decr(key):名称为key的string减1操作
decrby(key, integer):名称为key的string减少integer
append(key, value):名称为key的string的值附加value
substr(key, start, end):返回名称为key的string的value的子串
对List 操作的命令
rpush(key, value):在名称为key的list尾添加一个值为value的元素
lpush(key, value):在名称为key的list头添加一个值为value的 元素
llen(key):返回名称为key的list的长度
lrange(key, start, end):返回名称为key的list中start至end之间的元素
ltrim(key, start, end):截取名称为key的list
lindex(key, index):返回名称为key的list中index位置的元素
lset(key, index, value):给名称为key的list中index位置的元素赋值
lrem(key, count, value):删除count个key的list中值为value的元素
lpop(key):返回并删除名称为key的list中的首元素
rpop(key):返回并删除名称为key的list中的尾元素
blpop(key1, key2,… key N, timeout):lpop命令的block版本。
brpop(key1, key2,… key N, timeout):rpop的block版本。
rpoplpush(srckey, dstkey):返回并删除名称为srckey的list的尾元素,并将该元素添加到名称为dstkey的list的头部
对Set操作的命令
sadd(key, member):向名称为key的set中添加元素member
srem(key, member) :删除名称为key的set中的元素member
spop(key) :随机返回并删除名称为key的set中一个元素
smove(srckey, dstkey, member) :移到集合元素
scard(key) :返回名称为key的set的基数
sismember(key, member) :member是否是名称为key的set的元素
sinter(key1, key2,…key N) :求交集
sinterstore(dstkey, (keys)) :求交集并将交集保存到dstkey的集合
sunion(key1, (keys)) :求并集
sunionstore(dstkey, (keys)) :求并集并将并集保存到dstkey的集合
sdiff(key1, (keys)) :求差集
sdiffstore(dstkey, (keys)) :求差集并将差集保存到dstkey的集合
smembers(key) :返回名称为key的set的所有元素
srandmember(key) :随机返回名称为key的set的一个元素
对Hash操作的命令
hset(key, field, value):向名称为key的hash中添加元素field
hget(key, field):返回名称为key的hash中field对应的value
hmget(key, (fields)):返回名称为key的hash中field i对应的value
hmset(key, (fields)):向名称为key的hash中添加元素field
hincrby(key, field, integer):将名称为key的hash中field的value增加integer
hexists(key, field):名称为key的hash中是否存在键为field的域
hdel(key, field):删除名称为key的hash中键为field的域
hlen(key):返回名称为key的hash中元素个数
hkeys(key):返回名称为key的hash中所有键
hvals(key):返回名称为key的hash中所有键对应的value
hgetall(key):返回名称为key的hash中所有的键(field)及其对应的value
Redis数据类型
string(字符串)
- string是redis最基本的类型,而且string类型是二进制安全的。意思是redis的string可以包含任何数据。比如jpg图片或者序列化的对象
- 从内部实现来看其实string可以看作byte数组,最大上限是1G字节
- string类型的值也可视为integer,从而可以让“incr”命令族操作,这种情况下,该integer的值限制在64位有符号数
- 在list、set和zset中包含的独立的元素类型都是string类型
应用场景:String是最常用的一种数据类型,普通的key/value存储.
list(双向链表)
- redis的list类型其实就是一个每个子元素都是string类型的双向链表,所以[lr]push和[lr]pop命令的算法时间复杂度都是O(1),另外list会记录链表的长度,所以llen操作也是O(1).
- 可以通过push,pop操作从链表的头部或者尾部添加删除元素。这使得list既可以用作栈,也可以用作队列
- list的最大长度是2^32-1个元素
应用场景:Redis list应用场景非常多,也是Redis最重要的数据结构之一,比如twitter的关注列表,粉丝列表等都可以用Redis的list结构来实现.
set(无序集合)
- set就是redis string的无序集合,不允许有重复元素
- set的最大元素数是2^32-1
- 对set的操作还有交集、并集、差集等
应用场景:Set对外提供的功能与list类似,当你需要存储一个列表数据,又不希望出现重复数据时,set 是一个很好的选择,并且set提供了判断某个成员是否在一个set集合内的接口,这个也是list所不能提供的
Sorted set(有序集合)-- zset
- zset是set的一个升级版本,在set的基础上增加了一个顺序属性,这一属性在添加修改元素时可以指定,每次指定后zset会自动安装指定值重新调整顺序。可以理解为一张表,一列存value,一列存顺序。操作中的key理解为zset的名字。
- zset的最大元素数是2^32-1。
- 对于已经有序的zset,仍然可以使用sort命令,通过指定asc|desc参数对其进行排序。
应用场景:Sorted set的使用场景与set类似,区别是set不是自动有序的,而sorted set可以通过用户额外提供一个优先级(score)的参数来为成员排序,并且是插入有序的,即自动排序.当你需要一个有序的并且不重复的集合列表,那么可以选择sorted set数据结构
hash(hash表)
- redis Hash类型对数据域和值提供了映射,这一结构很方便表示对象
- 在Hash中可以只保存有限的几个“域”,而不是将所有的“域”作为key,这可以节省内存
应用场景:比如,我们存储供应商酒店价格的时候可以采取此结构,用酒店编码作为Key, 价格信息作为Value
Redis的功能
Redis发布/订阅
Redis的发布/订阅(Publish/Subscribe)功能类似于传统的消息路由功能,发布者发布消息,订阅者接收消息,沟通发布者和订阅者之间的桥梁是订阅的Channel或者Pattern.订阅者和发布者之间的关系是松耦合的,发布者不指定哪个订阅者才能接收消息,订阅者不只接收特定发布者的消息.
Redis事务支持
Redis目前对事务支持还比较简单,也即支持一些简单的组合型的命令,只能保证一个client发起的事务中的命令可以连续的执行,而中间不会插入其他client的命令. 由于Redis是单线程来处理所有client的请求的所以做到这点是很容易的.事务的执行过程中,如果redis意外的挂了,这时候事务可能只被执行了一半,可以用redis-check-aof 工具进行修复
Redis主从复制(集群)
Master/Slave配置: Master IP:175.41.209.118 Master Redis Server Port:6379 Slave配置很简单,只需要在slave服务器的redis.conf加入: slaveof 175.41.209.118 6379 启动master和slave,然后写入数据到master,读取slave,可以看到数据被复制到slave了. 用途:读写分离,数据备份,灾难恢复等Redis主从复制过程:
配置好slave后,slave与master建立连接,然后发送sync命令. 无论是第一次连接还是重新连接,master都会启动一个后台进程,将数据库快照保存到文件中,同时master主进程会开始收集新的写命令并缓存. 后台进程完成写文件后,master就发送文件给slave,slave将文件保存到硬盘上,再加载到内存中。 接着master就会把缓存的命令转发给slave,后续master将收到的写命令发送给slave. 如果master同时收到多个slave发来的同步连接命令,master只会启动一个进程来写数据库镜像, 然后发送给所有的slaveRedis主从复制特点:
1. master可以拥有多个slave. 2. 多个slave可以连接同一个master外,还可以连接到其他slave. 3. 主从复制不会阻塞master,在同步数据时,master可以继续处理client请求. 4. 可以在master禁用数据持久化,注释掉master配置文件中的所有save配置,只需在slave上配置数据持久化. 5. 提高系统的伸缩性Redis主从复制速度:
官方提供了一个数据, 㻿lave在21秒即完成了对Amazon网站 10G key set的复制.Redis持久化
由于Redis是内存数据库,它将自己的数据库状态存储在内存里面,所以如果不想办法将储存在内存中的数据库状态保存到磁盘里面,那么一旦服务器退出,服务器中的数据库状态也会消失不见。为了解决这个问题,Redis提供了RDB、AOF持久化方式,将内存中的数据保存到磁盘中,避免数据意外丢失
(1)RDB是 Snapshotting(快照)也是默认方式: 快照是默认的持久化方式。这种方式将内存中数据以快照的方式写入到二进制文件中,默认的文件名为dump.rdb。可以配置自动做快照持久 化的方式。我们可以配置redis在n秒内如果超过m个key被修改就自动做快照
RDB持久化通过将服务器某个时间点上的数据库状态(非空数据库以及相关键值对)保存到一个RDB文件中,Redis服务器可以用它来还原数据库状态。 SAVE命令会阻塞Redis服务器进程。而BGSAVE会派生出一个子进程,然后由子进程负责创建RDB文件,服务器父进程继续处理命令请求。还可以SAVE命令设置自动间隔保存, 例如SAVE 60 10000 服务器在60秒之内,对数据库进行了至少10000次修改,自动执行BGSAVE命令。RDB文件是一个经过压缩的二进制文件。
(2)AOF(Append-only file): AOF持久化通过保存Redis服务器所执行的写命令来记录数据库状态的。被写入AOF文件的所有命令都是以Redis的命令请求协议格式保存的,Redis的命令请求协议保存为纯文本格式。AOF持久化功能的实现分为命令追加、文件写入、文件同步三个步骤:当AOF持久化处于打开状态时,服务器在执行完一个写命令后,会以协议格式将被执行的写命令(如SET、SADD、RPUSH)追加到服务器状态的aofbuf缓冲区的末尾。服务器在每次结束一个事件循环之前,它都会调用flushAppendOnlyFile函数,考虑是否需要将aof_buf缓冲区中的内容写入和保存到AOF文件里面。flushAppendOnlyFile函数的行为由服务器配置的appendfsync选项的值( always 、 everysec(默认) 、 no )来决定
RDB与AOF比较
RDB
优点:RDB 是一个非常紧凑的文件,它保存了 Redis 在某个时间点上的数据集。这种文件非常适合用于进行备份。缺点:如果你需要尽量避免在服务器故障时丢失数据,那么 RDB 不适合你。 虽然 Redis 允许你设置不同的保存点(save point)来控制保存 RDB 文件的频率, 但是, 因为RDB 文件需要保存整个数据集的状态,所以它并不是一个轻松的操作。因此你可能会至少 5 分钟才保存一次 RDB 文件。 在这种情况下, 一旦发生故障停机, 你就可能会丢失好几分钟的数据。
AOF
优点:使用 AOF 持久化会让 Redis 变得非常耐久:你可以设置不同的 fsync 策略,比如无 fsync ,每秒钟一次 fsync ,或者每次执行写入命令时 fsync 。 AOF 的默认策略为每秒钟 fsync 一次,在这种配置下,Redis 仍然可以保持良好的性能,并且就算发生故障停机,也最多只会丢失一秒钟的数据( fsync 会在后台线程执行,所以主线程可以继续努力地处理命令请求)。缺点:对于相同的数据集来说,AOF 文件的体积通常要大于 RDB 文件的体积。根据所使用的 fsync 策略,AOF 的速度可能会慢于 RDB 。
Java操作Redis示例
所需jar包:
<!-- https://mvnrepository.com/artifact/redis.clients/jedis -->
<dependency>
<groupId>redis.clients</groupId>
<artifactId>jedis</artifactId>
<version>2.9.0</version>
</dependency>
java操作:
import java.util.Iterator;
import java.util.List;
import java.util.Set;
import redis.clients.jedis.Jedis;
public class RedisTest {
public static void main(String[] args) {
//获取redis的连接
//代表使用端口号为6379,默认,如果端口号非默认的,则需要new Jedis("192.168.168.226",8888);
Jedis jd = new Jedis("39.106.131.203");
System.out.println("连接redis成功");
//需要设置redis服务器(虚拟机中的6379.conf文件,将bind修改为:0.0.0.0)
// System.out.println("服务正在运行" + jd.ping());
/**
* 操作string类型
*/
// jd.set("key2", "java1212");
// System.out.println("redis中存储的值为:"+jd.get("key2"));
/**
* 操作list类型
*/
// jd.lpush("list", "listvalue1");
// jd.lpush("list", "listvalue2");
// jd.lpush("list", "listvalue3");
//
// List<String> list = jd.lrange("list", 0, 2);
// for (int i = 0; i < list.size(); i++) {
// System.out.println("list的结果是:" + list.get(i));
// }
/**
* 操作set类型
*/
jd.sadd("setKey1", "setvalue1");
jd.sadd("setKey1", "setvalue2");
jd.sadd("setKey1", "setvalue3");
Set<String> keys = jd.keys("*");
// Set<String> keys = jd.smembers("setKey1");
Iterator<String> it = keys.iterator();
while(it.hasNext()){
String key = it.next();
System.out.println(key);
}
}
}
Redis总结
Redis使用最佳方式是全部数据in-memory。
Redis更多场景是作为Memcached的替代者来使用。
当需要除key/value之外的更多数据类型支持时,使用Redis更合适。
当存储的数据不能被剔除时,使用Redis更合适。(持久化)
MongoDB篇
MongoDB简介
- MongoDB是一个跨平台,面向文档的数据库,提供高性能,高可用性和易于扩展。MongoDB是工作在集合和文档上一种概念
- MongoDB 是一个基于分布式文件存储的数据库。由C++语言编写。旨在为WEB应用提供可扩展的高性能数据存储解决方案
- MongoDB 是一个介于关系数据库和非关系数据库之间的产品,是非关系数据库当中功能最丰富,最像关系数据库的。他支持的数据结构非常松散,是类似json的bson格式,因此可以存储比较复杂的数据类型。Mongo最大的特点是他支持的查询语言非常强大,其语法有点类似于面向对象的查询语言,几乎可以实现类似关系数据库单表查询的绝大部分功能,而且还支持对数据建立索引
MongoDB特点
- 面向集合存储,易于存储对象类型的数据
- 模式自由
- 支持动态查询
- 支持完全索引,包含内部对象
- 支持查询
- 支持复制和故障恢复
- 使用高效的二进制数据存储,包括大型对象(如视频等)
- 自动处理碎片,以支持云计算层次的扩展性
- 支持 Python,PHP,Ruby,Java,C,C#,Javascript,Perl 及 C++语言的驱动程序
- 文件存储格式为 BSON(一种 JSON 的扩展),文档型
- 可通过网络访问
面向集合(Collenction-Orented)
- 意思是数据被分组存储在数据集中,被称为一个集合(Collenction)。每个集合在数据库中都有一个唯一的标识名,并且可以包含无限数目的文档。集合的概念类似关系型数据库(RDBMS)里的表(table),不同的是它不需要定义任何模式(schema)
模式自由(schema-free)
意味着对于存储在 MongoDB 数据库中的文件,我们不需要知道它的任何结构定义。提了这么多次"无模式"或"模式自由",它到是个什么概念呢? 例如,下面两个记录可以存在于同一个集合里面:
{"welcome" : "Beijing"}
{"age" : 25}
文档型:
- 意思是我们存储的数据是键-值对的集合,键是字符串,值可以是数据类型集合里的任意类型,包括数组和文档. 我们把这个数据格式称作 “BSON” 即 “Binary Serialized dOcument Notation.”
MongoDB应用场景
适合场景:
1.网站数据,实时的插入,更新与查询。
2.由于性能很高,可做持久化缓存层。
3.存储大尺寸,低价值的数据。
4.高伸缩性的集群场景。
5.BSON格式非常适合文档化数据的存储及查询。
不适合场景:
1.高度事务性的系统,例如银行或会计系统。
2.传统的商业智能应用,针对特定问题的BI数据库会对产生高度优化的查询方式。对于此类应用,数据仓库可能是更合适的选择。
MongoDB下载安装(Linux)
教程系统版本:(Linux版本下CentOS Linux release 7.3.1611 (Core))
下载:
1:在线下载
wget https://fastdl.mongodb.org/linux/mongodb-linux-x86_64-3.2.9.tgz
2:官网下载
https://www.mongodb.com/download-center?ct=atlasheader#atlas
安装(在线安装):
1:进入/opt目录下
cd /opt
2:创建文件夹
mkdir mongodb
3:进入mongodb目录下,在线下载mongodb资源安装包
cd mongodb/
wget https://fastdl.mongodb.org/linux/mongodb-linux-x86_64-3.2.9.tgz
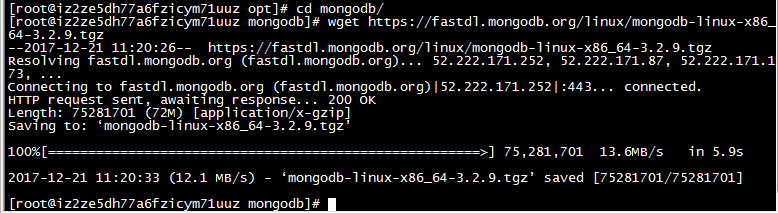
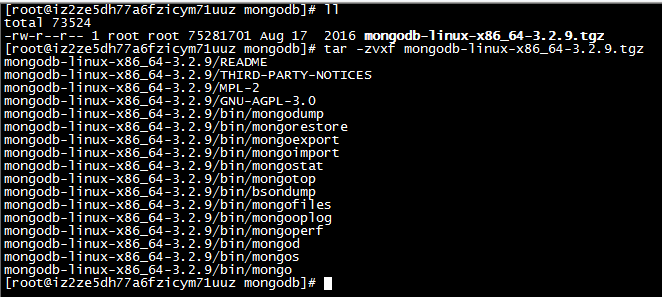
4:解压mongodb资源包到当前路径下
tar -zvxf mongodb-linux-x86_64-3.2.9.tgz
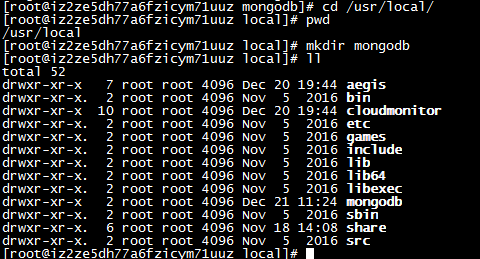
5:进入目录/usr/local/下,并创建文件夹mongodb
cd /usr/local
mkdir mongodb
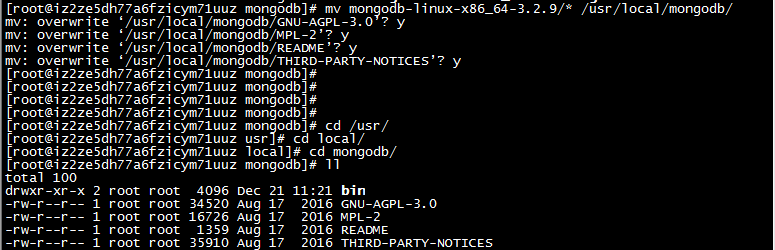
6:将mongodb-linux-x86_64-3.2.9文件夹内的内容 移动到 /usr/local/mongodb下
mv /opt/mongodb/mongodb-linux-x86_64-3.2.9/* /usr/local/mongodb
7:在mongodb目录下,新建1个文件夹和1个文件
mkdir data
touch logs
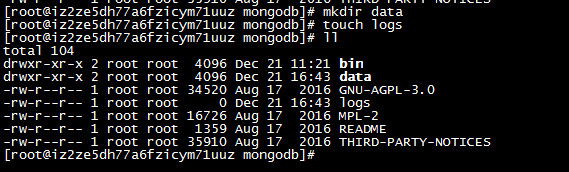
8:在系统执行文件~/.bash_profile中添加mongodb的执行命令
vim ~/.bash_profile
内容为:
PATH=$PATH:$HOME/bin:/usr/local/mongodb/bin
source ~/.bash_profie
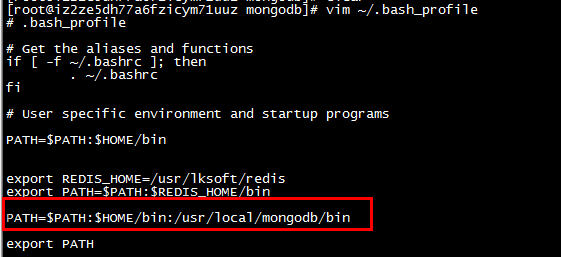
注意:
export MONGODB_HOME=/usr/local/mongodb //配置刚才的路径
PATH=$PATH:$HOME/bin:/usr/local/mongodb/bin
# User specific environment and startup programs
PATH=$PATH:$HOME/bin
export REDIS_HOME=/usr/lksoft/redis
export MONGODB_HOME=/usr/local/mongodb
PATH=$PATH:$HOME/bin:/usr/local/mongodb/bin
export PATH
Mongodb启动方式
mongodb有三种启动方式:
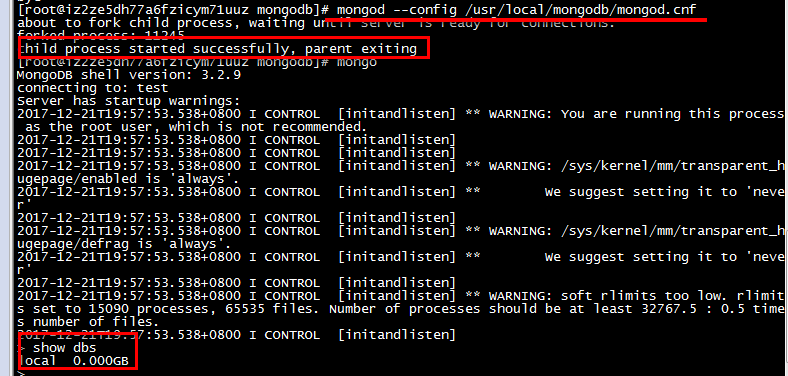
启动1:进入/bin目录下,输入mongod --dbpath=/usr/local/mongodb/data --fork --logpath=/usr/local/mongodb/logs
启动之后,输入mongo就可以进入mongodb客户端连接
然后输入show dbs;如果显示数据库,则启动搭建成功

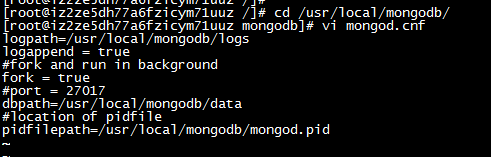
启动2:配置启动文件启动mongodb.conf(推荐)
mongodb.conf内容:
logpath=/usr/local/mongodb/logs
logappend = true
#fork and run in background
fork = true
#port = 27017
dbpath=/usr/local/mongodb/data
#location of pidfile
pidfilepath=/usr/local/mongodb/mongod.pid
之前打开数据库了,所以先关库:
可以使用db.shutdownServer()命令,或者ps -ef|grep mongod查看进程号,使用kill -9 进程号即可
mongod --config /usr/local/mongodb/mongodb.conf 启动
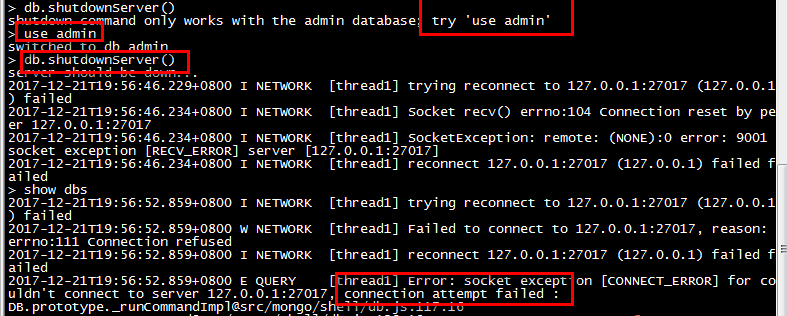

启动3:配置service服务启动(推荐)
MongoDB基本操作
- 体系结构
MongoDB 是一个可移植的数据库,它在流行的每一个平台上都可以使用,即所谓的跨平台 特性。在不同的操作系统上虽然略有差别,但是从整体构架上来看,MongoDB 在不同的平 台上是一样的,如数据逻辑结构和数据的存储等等。
一个运行着的 MongoDB 数据库就可以看成是一个 MongoDB Server,该 Server 由实例和数据库组成,在一般的情况下一个 MongoDB Server 机器上包含一个实例和多个与之对应的数据库,但是在特殊情况下,如硬件投入成本有限或特殊的应用需求,也允许一个 Server 机器上可以有多个实例和多个数据库。
MongoDB 中一系列物理文件(数据文件,日志文件等)的集合或与之对应的逻辑结构(集 合,文档等)被称为数据库,简单的说,就是数据库是由一系列与磁盘有关系的物理文件的 组成。
- 数据逻辑结构
MongoDB 的逻辑结构是一种层次结构。主要由:文档(document)、集合(collection)、数据库(database)这三部分组成的。逻辑结构是面向用户的,用户使用 MongoDB 开发应用程序使用的就是逻辑结构。
1: MongoDB 的文档(document),相当于关系数据库中的一行记录
2:多个文档组成一个集合(collection),相当于关系数据库的表
3:多个集合(collection),逻辑上组织在一起,就是数据库(database)
4:一个 MongoDB 实例支持多个数据库(database)
- 数据存储结构
MongoDB 的默认数据目录是/data/db,它负责存储所有的 MongoDB 的数据文件。在 MongoDB内部,每个数据库都包含一个.ns 文件和一些数据文件,而且这些数据文件会随着数据量的增加而变得越来越多
对比:

启动、停止数据库
参考上面启动方式连接数据库
参考上面连接命令
mongod参数说明
mongod 的主要参数有: dbpath: 数据文件存放路径,每个数据库会在其中创建一个子目录,用于防止同一个实例多次运行的 mongod.lock 也保存在此目录中。 logpath 错误日志文件 logappend 错误日志采用追加模式(默认是覆写模式) bind_ip 对外服务的绑定 ip,一般设置为空,及绑定在本机所有可用 ip 上,如有需要可以单独指定 port 对外服务端口。Web 管理端口在这个 port 的基础上+1000 fork 以后台 Daemon 形式运行服务 journal 开启日志功能,通过保存操作日志来降低单机故障的恢复时间,在 1.8 版本后正式加入,取代在 1.7.5 版本中的 dur 参数。 syncdelay 系统同步刷新磁盘的时间,单位为秒,默认是 60 秒。 directoryperdb 每个 db 存放在单独的目录中,建议设置该参数。与 MySQL 的独立表空间类似maxConns最大连接数 repairpath 执行 repair 时的临时目录。在如果没有开启 journal,异常 down 机后重启,必须执行 repair 操作
常见命令
show dbs:显示数据库列表
show collections:显示当前数据库中的集合(类似关系数据库中的表)
show users:显示用户
use <db name>:切换当前数据库,这和MS-SQL里面的意思一样
db.help():显示数据库操作命令,里面有很多的命令
db.foo.help():显示集合操作命令,同样有很多的命令,foo指的是当前数据库下,一个叫foo的集合,并非真正意义上的命令
db.foo.find():对于当前数据库中的foo集合进行数据查找(由于没有条件,会列出所有数据)
db.foo.find( { a : 1 } ):对于当前数据库中的foo集合进行查找,条件是数据中有一个属性叫a,且a的值为1
MongoDB没有创建数据库的命令,但有类似的命令。
修复当前数据库 db.repairDatabase();
查看当前使用的数据库
db.getName();
db; db和getName方法是一样的效果,都可以查询当前使用的数据库
显示当前db状态 db.stats();
当前db版本 db.version();
查看当前db的链接机器地址 db.getMongo();
基本操作
添加文档:
db.users.insert({ “_id”:ObjectId("52c3c518498a9646a48133a2"), “name”:“likang”, “email”:“likang@qq.com” }); db.users.save({ “_id”:ObjectId("52c3c518498a9646a48133a2"), “name”:“likang2”, “email”:“likang2@qq.com” }); insert 当_id存在时报错 save 当_id存在时覆盖更新删除文档:
//删除全部 db.user.remove(); //删除指定记录 db.user.remove({“name”:“likang”}); //删除user集合 db.user.drop();
更新文档:
原⽂档:
{
“_id”:ObjectId("52c3c518498a9646a48133a2"),
“name”:“likang”,
“email”:“likang@qq.com”
}
!
修改后的⽂档:
{
“_id”:ObjectId("52c3c518498a9646a48133a2"),
“name”:“likang”,
“email”:[
“likang@qq.com”,
“likang2@qq.com”
]
}
var doc = db.users.findOne({"name" : “likang”});
doc.email =[
“likang@qq.com”,
“likang2@qq.com”
];
db.users.update({ "name" : "likang" }, doc);
// 更新:指定第三个参数为true可以开启upsert模式
//根据条件查找不到数据则创建⼀条新的
db.users.update({ "name" : "likang" }, doc, true);
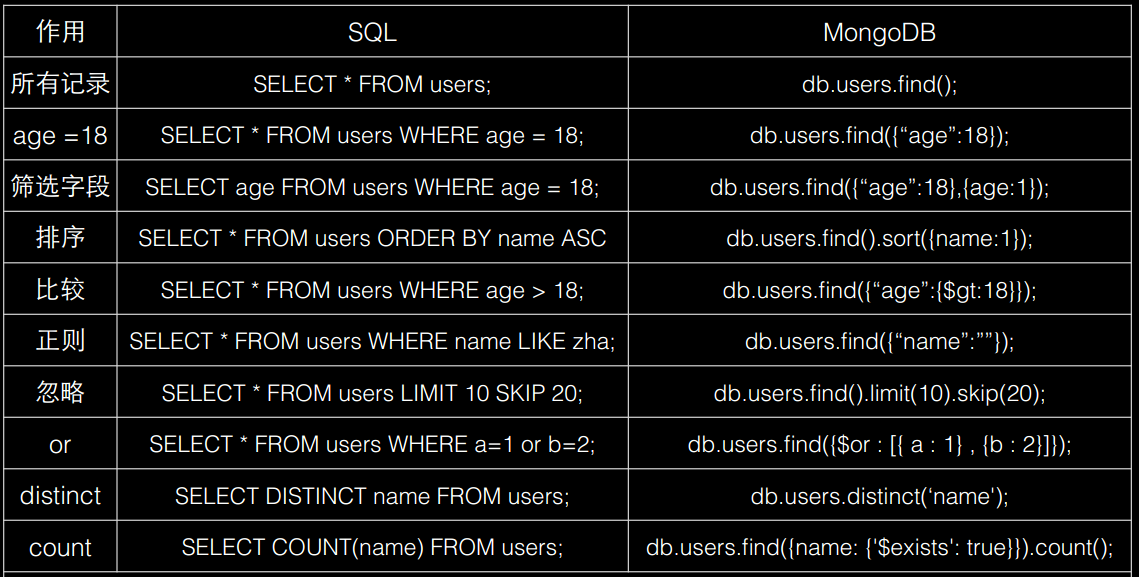
- 查询文档:
常用工具集
MongoDB 在 bin 目录下提供了一系列有用的工具,这些工具提供了 MongoDB 在运维管理上的方便。
- bsondump: 将 bson 格式的文件转储为 json 格式的数据
- mongo: 客户端命令行工具,其实也是一个 js 解释器,支持 js 语法
- mongod: 数据库服务端,每个实例启动一个进程,可以 fork 为后台运行
- mongodump/ mongorestore: 数据库备份和恢复工具
- mongoexport/ mongoimport: 数据导出和导入工具
- mongofiles: GridFS 管理工具,可实现二制文件的存取 -mongos: 分片路由,如果使用了 sharding 功能,则应用程序连接的是 mongos 而不是 mongod
- mongosniff: 这一工具的作用类似于 tcpdump,不同的是他只监控 MongoDB 相关的包请求,并且是以指定的可读性的形式输出
- mongostat: 实时性能监控工具
Java操作MongoDB示例
- 新建maven project工程
配置所需jar包
<dependency> <groupId>org.mongodb</groupId> <artifactId>mongo-java-driver</artifactId> <version>3.3.0</version> </dependency>增加连接mongodb的工具类
/** * mongodb工具类 * @author likang * @date 2017-4-23 下午8:19:53 */ public class MongoDbUtil { private static MongoCollection<Document> collection; /** * 链接数据库 * * @param databaseName 数据库名称 * @param collectionName 集合名称 * @param hostName 主机名 * @param port 端口号 */ public static void connect(String databaseName, String collectionName,String hostName, int port) { @SuppressWarnings("resource") MongoClient client = new MongoClient(hostName, port); MongoDatabase db = client.getDatabase(databaseName); collection = db.getCollection(collectionName); System.out.println(collection); } /** * 插入一个文档 * * @param document 文档 */ public static void insert(Document document) { collection.insertOne(document); } /** * 查询所有文档 * * @return 所有文档集合 */ public static List<Document> findAll() { List<Document> results = new ArrayList<Document>(); FindIterable<Document> iterables = collection.find(); MongoCursor<Document> cursor = iterables.iterator(); while (cursor.hasNext()) { results.add(cursor.next()); } return results; } /** * 根据条件查询 * * @param filter * 查询条件 //注意Bson的几个实现类,BasicDBObject, BsonDocument, * BsonDocumentWrapper, CommandResult, Document, RawBsonDocument * @return 返回集合列表 */ public static List<Document> findBy(Bson filter) { List<Document> results = new ArrayList<Document>(); FindIterable<Document> iterables = collection.find(filter); MongoCursor<Document> cursor = iterables.iterator(); while (cursor.hasNext()) { results.add(cursor.next()); } return results; } /** * 更新查询到的第一个 * @param filter 查询条件 * @param update 更新文档 * @return 更新结果 */ public static UpdateResult updateOne(Bson filter, Bson update) { UpdateResult result = collection.updateOne(filter, update); return result; } /** * 更新查询到的所有的文档 * * @param filter 查询条件 * @param update 更新文档 * @return 更新结果 */ public static UpdateResult updateMany(Bson filter, Bson update) { UpdateResult result = collection.updateMany(filter, update); return result; } /** * 更新一个文档, 结果是replacement是新文档,老文档完全被替换 * * @param filter 查询条件 * @param replacement 跟新文档 */ public static void replace(Bson filter, Document replacement) { collection.replaceOne(filter, replacement); } /** * 根据条件删除一个文档 * @param filter 查询条件 */ public static void deleteOne(Bson filter) { collection.deleteOne(filter); } /** * 根据条件删除多个文档 * @param filter 查询条件 */ public static void deleteMany(Bson filter) { collection.deleteMany(filter); } }编写mongodb操作测试类
public class MongoTest { public static void main(String[] args) { MongoDbUtil.connect("test", "jihe1", "*.*.*.*", 27017); // 参数为 数据库,集合,ip,端口 》 // testInsert(); // testFindAll(); // Mongo mg = new Mongo("39.106.131.203",27017); // DB db = mg.getDB("jihe1"); // for(String s:db.getCollectionNames()){ // System.out.println("内容如下:"); // System.out.println(s); // } // } public static void testInsert() { Document document = new Document(); document.append("name", "likang").append("phone", "18912341234"); MongoDbUtil.insert(document); } public static void testFindAll() { List<Document> results = MongoDbUtil.findAll(); for (Document doc : results) { System.out.println(doc.toJson()); } } public static void testFindBy() { Document filter = new Document(); filter.append("name", "li si"); List<Document> results = MongoDbUtil.findBy(filter); for (Document doc : results) { System.out.println(doc.toJson()); } } public static void testUpdateOne() { Document filter = new Document(); filter.append("phone", "18912341235"); // 注意update文档里要包含"$set"字段 Document update = new Document(); update.append("$set", new Document("phone", "123123123")); UpdateResult result = MongoDbUtil.updateOne(filter, update); System.out.println("matched count = " + result.getMatchedCount()); } public static void testUpdateMany() { Document filter = new Document(); filter.append("phone", "18912341235"); // 注意update文档里要包含"$set"字段 Document update = new Document(); update.append("$set", new Document("phone", "123123123")); UpdateResult result = MongoDbUtil.updateMany(filter, update); System.out.println("matched count = " + result.getMatchedCount()); } public static void testReplace() { Document filter = new Document(); filter.append("name", "likang"); // 注意:更新文档时,不需要使用"$set" Document replacement = new Document(); replacement.append("value", 123); MongoDbUtil.replace(filter, replacement); } public static void testDeleteOne() { Document filter = new Document(); filter.append("name", "wang"); MongoDbUtil.deleteOne(filter); } public static void testDeleteMany() { Document filter = new Document(); filter.append("phone", "18778907890"); MongoDbUtil.deleteMany(filter); } }
MongoDB总结
Mongodb主要解决的是海量数据的访问效率问题,根据官方的文档,当数据量达到50GB以上的时候,Mongo的数据库访问速度是MySQL的10倍以上。Mongo的并发读写效率不是特别出色,根据官方提供的性能测试表明,大约每秒可以处理0.5万-1.5次读写请求。因为Mongo主要是支持海量数据存储的,所以Mongo还自带了一个出色的分布式文件系统GridFS,可以支持海量的数据存储,最后由于Mongo可以支持复杂的数据结构,而且带有强大的数据查询功能和类似于sql的索引。
Mongodb的高性能在于模式自由,使用高效的二进制数据存储,包括大型对象(如视频等)自动处理碎片,以支持云计算层次的扩展性。在存储海量数据的同时,还有良好的查询性能。当然了mongodb支持多种语言,支持RUBY,PYTHON,JAVA,C++,PHP,C#等多种语言
Redis、Memcache、MongoDB特点、区别以及应用场景
更多











