
分布式锁应用场景
很多应用场景是需要系统保证幂等性的(如api服务或消息消费者),并发情况下或消息重复很容易造成系统重入,那么分布式锁是保障幂等的一个重要手段。
另一方面,很多抢单场景或者叫交易撮合场景,如dd司机抢单或唯一商品抢拍等都需要用一把“全局锁”来解决并发造成的问题。在防止并发情况下造成库存超卖的场景,也常用分布式锁来解决。
实现分布式锁方案
这里介绍常见两种:redis锁、zookeeper锁
1.Redis实现方案
1.1实现原理
redis分布式锁基本都知道setnx命令(if not exists),其实现原理即:如果进入redis添加某个键不存在可以设置成功,如果已存在则会设置失败。
说明:setnx命令已过时,这里推荐使用 set +nx 参数来实现。
set命令:set key value ex seconds nx
- ex 表示过期时间,精确到秒 (对应另一个参数px过期时间精确到毫秒)
- nx 表示if not exists,只有键不存在才能设置成功(对应另一个参数xx只有键存在才能设置成功)
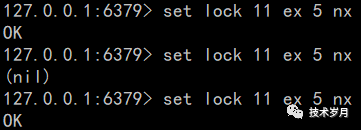
设置过期时间的作用,如果某个并行任务(进程/线程/协程)持有锁,但不能正常释放,将导致所有任务都无法获取锁,获取执行权限。而引入了过期时间解决此问题的同时,也会引入新的问题,具体后面分析。
1.2代码实现
import "github.com/go-redis/redis" //redis package
//connect redis
var client = redis.NewClient(&redis.Options{
Addr: "localhost:6379",
Password: "",
DB: 0,
})
//lock
func lock(myfunc func()) {
var lockKey = "mylockr"
//lock
lockSuccess, err := client.SetNX(lockKey, 1, time.Second*5).Result()
if err != nil || !lockSuccess {
fmt.Println("get lock fail")
return
} else {
fmt.Println("get lock")
}
//run func
myfunc()
//unlock
_, err := client.Del(lockKey).Result()
if err != nil {
fmt.Println("unlock fail")
} else {
fmt.Println("unlock")
}
}
//do action
var counter int64
func incr() {
counter++
fmt.Printf("after incr is %d\n", counter)
}
//5 goroutine compete lock
var wg sync.WaitGroup
func main() {
for i := 0; i < 5; i++ {
wg.Add(1)
go func() {
lock(incr)
}()
}
wg.Wait()
fmt.Printf("final counter is %d \n", counter)
}以上代码截取关键部分,完整代码参见:链接
代码执行结果:
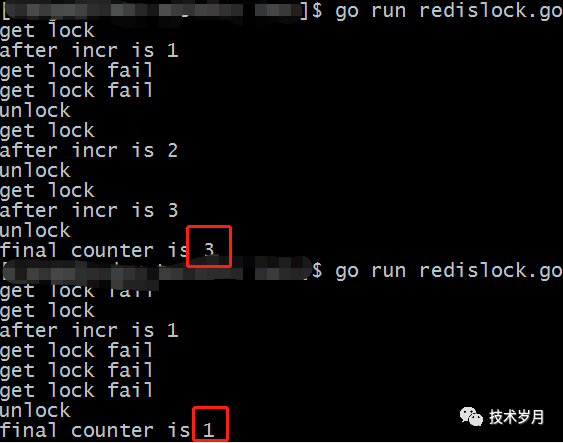
根据执行结果可以看到,每次执行最后的计数不一样,多个协程间互相抢锁,只有拿到锁才会计数加1,抢锁失败则不执行。
这里说明下:由于routine执行时间太短,执行完把锁释放了所以才有其他routine可以拿到锁。如果incr代码中增加sleep时间,那么结果都是1了。
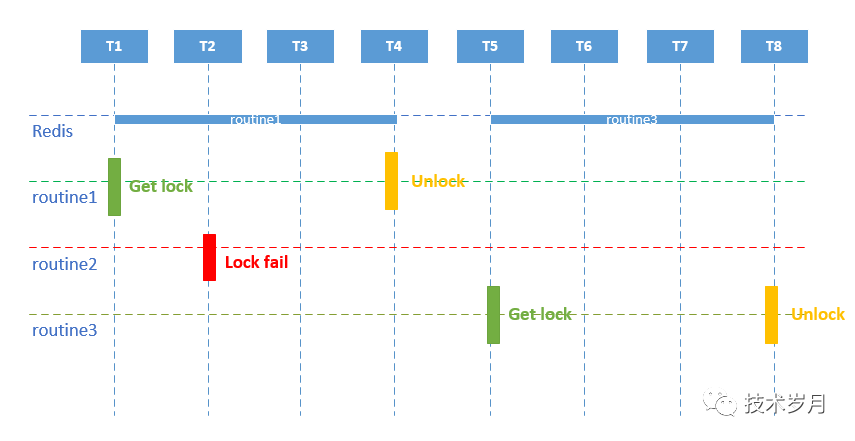
用一张图来更直观解释具体执行情况:
1.3方案缺陷
刚才提到使用了过期时间,虽然解决了“死锁”问题,但会引来新的问题,具体问题分析如下:
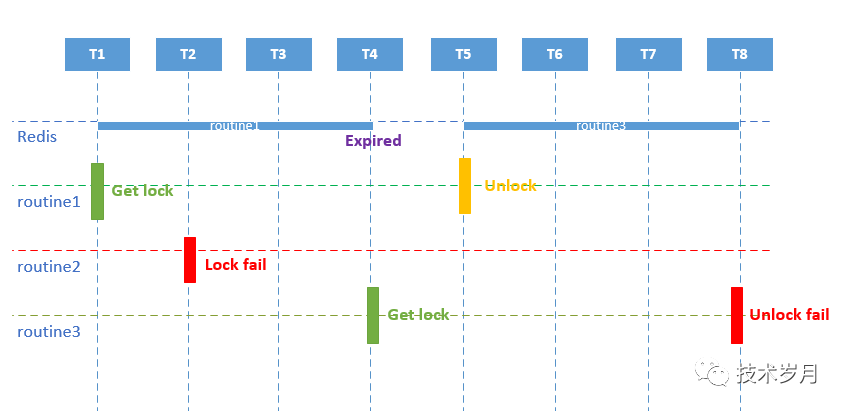
可以看到routine1拿到锁,但由于执行时间过长(比锁失效时间长),导致锁提前失效释放,routine3可以正常拿到锁,而之后routine1进行锁释放,当routine3进行锁释放时就会失败,如果此时有其他并发来的时候锁也会有问题。
1.4方案优化
那么有什么有效解决方案呢?
简单来说就是利用lock的value,还记得之前代码设置lock的时候随便使用了一个值1就打发了。
resp := client.SetNX(lockKey, 1, time.Second\*5)这里的1可以改为能识别该routine的唯一值(如uid,orderid等),也可以使用uuid随机生成一个。
func lock(myfunc func()) {
//lock
uuid := getUuid()
lockSuccess, err := client.SetNX(lockKey, uuid, time.Second*5).Result()
if err != nil || !lockSuccess {
fmt.Println("get lock fail")
return
} else {
fmt.Println("get lock")
}
//run func
myfunc()
//unlock
value, _ := client.Get(lockKey).Result()
if value == uuid { //compare value,if equal then del
_, err := client.Del(lockKey).Result()
if err != nil {
fmt.Println("unlock fail")
} else {
fmt.Println("unlock")
}
}
}这里增加了value的比较,确认了是当前routine,才会进行删除。至此问题解决了吗?
value, \_ := client.Get(lockKey).Result() 和 value==uuid这个操作本身不具有“原子性”,可能当获取到value并且对比一致了,但此时lock过期失效了,而同时另一个routine拿到了结果,那么这里又会把别人的锁误删除了。
1.5方案再优化
那么有没有办法保障操作的原子性呢,这里可以使用lua彻底解决,lua是嵌入式语言,redis本身支持。使用golang操作redis运行lua命令,保障问题解决。上代码如下:
func lock(myfunc func()) {
//...code
//unlock
var luaScript = redis.NewScript(`
if redis.call("get", KEYS[1]) == ARGV[1]
then
return redis.call("del", KEYS[1])
else
return 0
end
`)
rs, _ := luaScript.Run(client, []string{lockKey}, uuid).Result()
if rs == 0 {
fmt.Println("unlock fail")
} else {
fmt.Println("unlock")
}
}lua脚本中KEYS[1]代表lock的key,ARGV[1]代表lock的value,也就是生成的uuid。通过执行lua来保障这里删除锁的操作是原子的。
完整代码参见:链接
1.6redis锁适用场景
由redis设置的锁,多个并发任务进行争抢占用,因此非常适合高并发情况下,用来进行抢锁。
2.zookeeper锁
2.1实现原理
使用zk的临时节点插入值,如果插入成功后watch会通知所有监听节点,此时其他并行任务不可再进行插入。具体图示如下:
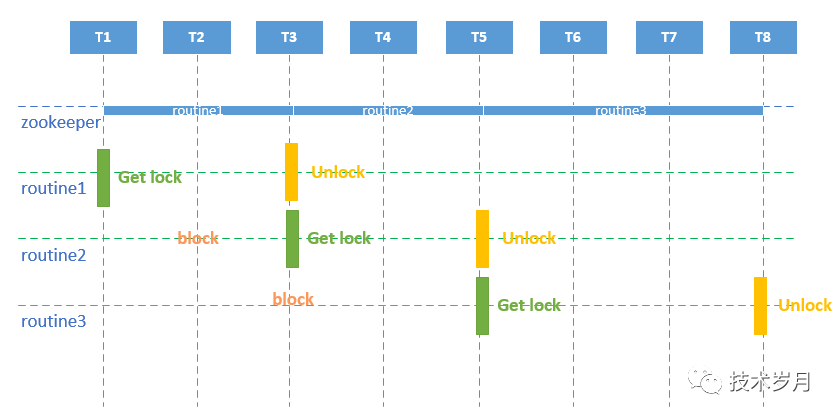
2.2代码实现
import "github.com/samuel/go-zookeeper/zk" //package
//connect zk
conn, _, err := zk.Connect([]string{"localhost:2181"}, time.Second)
//zklock
func zklock(conn *zk.Conn, myfunc func()) {
lock := zk.NewLock(conn, "/mylock", zk.WorldACL(zk.PermAll))
err := lock.Lock()
if err != nil {
panic(err)
}
fmt.Println("get lock")
myfunc()
lock.Unlock()
fmt.Println("unlock")
}
//goroutine run
for i := 0; i < 5; i++ {
go zklock(conn, incr)
}完整代码参见:链接
执行结果如下:
每次执行,执行结果都是5。
2.3zookeeper锁适用场景
相比于redis抢锁导致其他routine抢锁失败退出,使用zk实现的锁会让其他routine处于“等锁”状态。
3.方案对比选择
redis锁 | zookeeper锁 | |
描述 | 使用set nx实现 | 使用临时节点+watch实现 |
依赖 | redis | zookeeper |
适用场景 | 并发抢锁 | 锁占用时间长其他任务可等待。如消息幂等消费。 |
高可用性 | redis发生故障主从切换等可能导致锁失效 | 利用paxos协议能保证分布式一致性,数据更可靠 |
如果不是对锁有特别高的要求,一般情况下使用redis锁就够了。除提到的这两种外使用etcd也可以完成锁需求,具体可以参考下方资料。
更多参考资料
etcd实现锁:
https://github.com/zieckey/etcdsync
文章相关实现代码:
https://github.com/skyhackvip/lock
推荐阅读
本文转自 https://mp.weixin.qq.com/s/lrSQBK-Kihkj6994kQFpUQ,如有侵权,请联系删除。












