
向量表示是机器学习生态系统中的一个关键概念。无论进行什么样的任务,我们总是试图训练找所掌握的数据的意义而机器学中通常使用数字向量来对数据进行描述,发现隐藏的行为,产生有价值的见解。
随着深度学习则是通过更少的假设和更少的工作获得更有意义的数据表示。例如在NLP领域,最早的 TF-IDF(词频-逆文档频率)是自然语言过程中采用的一种技术,用于将原始文本文档的集合转换为数字矩阵。TF-IDF 长期以来一直是NLP的基础,代表了一种编码文本序列的好方法。深度学习的出现首先带来了 Word2Vec 等新技术,然后是transformer编码。它们都是端到端的解决方案,并且在提供文本数据的数字数据表示方面更有效,并且无需(在大多数情况下)理解上下文。
在 NLP 领域采用深度学习嵌入表示是革命性的。通常将术语“嵌入表示”与涉及文本数据的应用程序相关联。这是因为很容易概括文本内容中单词的位置依赖性。
在以前的研究中一个有趣的想法可能是将 NLP 中获得的成就应用在时间序列域。这可能是一个完美的契合,因为时间序列数据也以位置/时间关系为特征。在NLP中的这些技术可以根据潜在的时间依赖性生成有价值的数据向量表示。所以出现了很多为时间序列数据生成嵌入的方法, Time2Vec 作为与模型无关的时间表示,可用于任何深度学习预测应用程序。Corr2Vec,通过研究它们的相互相关性来提取多个时间序列的嵌入表示。
在这篇文章中,我们尝试在时间序列域中应用 Word2Vec。目标是利用无监督方法(如 Word2Vec)的灵活性来学习有意义的时间序列嵌入。生成的嵌入应该能够捕获底层系统行为,以便在其他上下文中也可重用。
数据
我们从UCI 库中收集一些开源数据(在UCI 许可政策内)。Parking Birmingham 数据集包含从 2016/10/04 到 2016/12/19 的每小时 8:00–16:30 范围内的停车占用率。它非常适合我们的目的,因为它记录了来自不同位置的数据,使我们能够在多变量情况下进行切换。
我们拥有原始占用率(即当时停车场内有多少辆汽车)和最大停车容量。
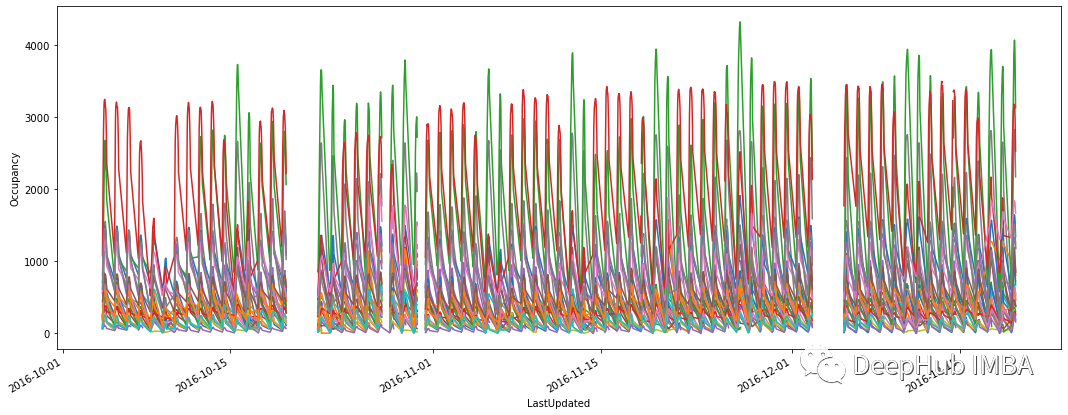
数据中有缺失观测值的存在,也显示了一些常规的季节性模式。观察每天和每周的行为。所有停车区都倾向于在下午达到最大入住率。其中一些在工作日使用最多,而另一些则在周末更忙。
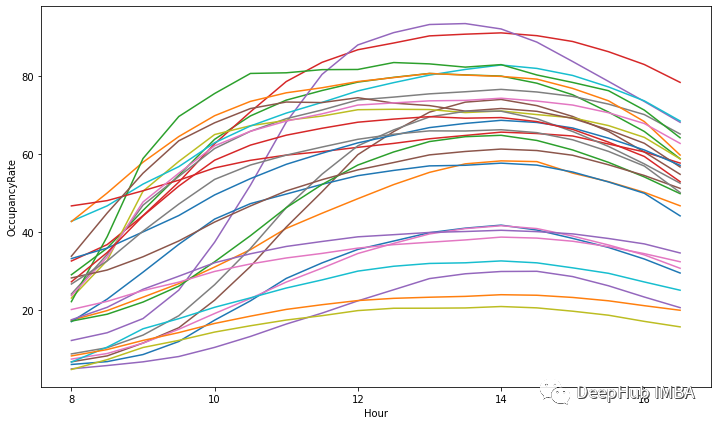
所有停车区的每小时占用率
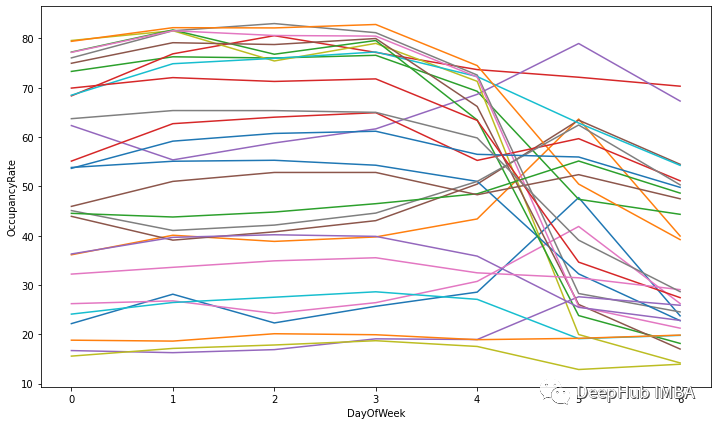
所有停车场的每日入住率
模型
如何将 Word2Vec 应用于时间序列数据?将 Word2Vec 应用于文本时,首先将每个单词映射到一个整数。这些数字代表了整个文本语料库中单词的唯一标识符,这些标识符关联独特的可训练嵌入。对于时间序列,也应该这样做。整数标识符是通过将连续时间序列分箱为间隔来创建的。在每个间隔中关联一个唯一标识符,该标识符指的是可学习的嵌入。
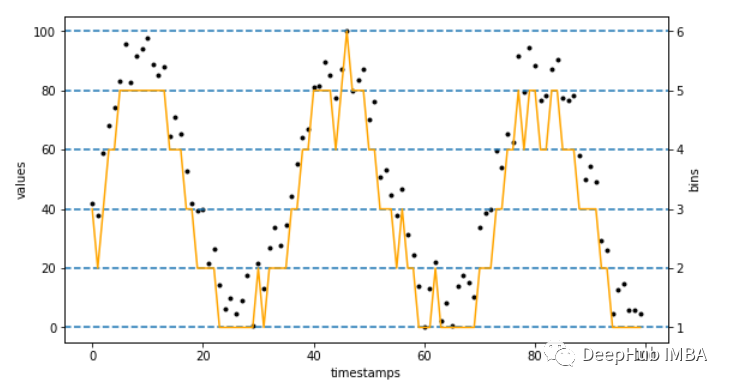
在离散化可以使用的时间序列之前,应该考虑对它们进行缩放。在多变量环境中工作时,这一点尤为重要。所以需要以统一的方式应用离散化来获得唯一的整数映射。考虑到我们这里使用的是停车数据,所以使用占用率序列(在 0-100 范围内归一化)可以避免误导性学习行为。
Word2Vec 架构与 NLP 应用程序中的架构相同。有不同的即用型解决方案。本文选择手工制作的 Tensorflow 实现:
input_target = Input((1,))
input_context = Input((1,))
embedding = Embedding(n_bins+1, 32)
dot = Dot(axes=1, normalize=True)([
Flatten()(embedding(input_target)),
Flatten()(embedding(input_context))
])
model = Model([input_target, input_context], dot)
model.compile(
optimizer=Adam(learning_rate=1e-5),
loss=BinaryCrossentropy(from_logits=True)
)训练数据和相关标签是使用 skip-gram 生成的。它根据用户定义的窗口大小生成一对整数。同一窗口中的整数对的标签等于 1。随机生成的对被标记为 0。
通过检查学习的嵌入,可以看到网络可以自动识别我们数据的周期性。
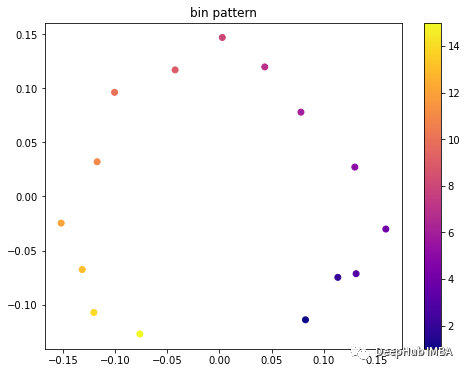
每个分箱时间序列的二维嵌入可视化
通过扩展所有时间序列的嵌入表示,我们注意到小时观测和每日观测之间存在明显的分离。
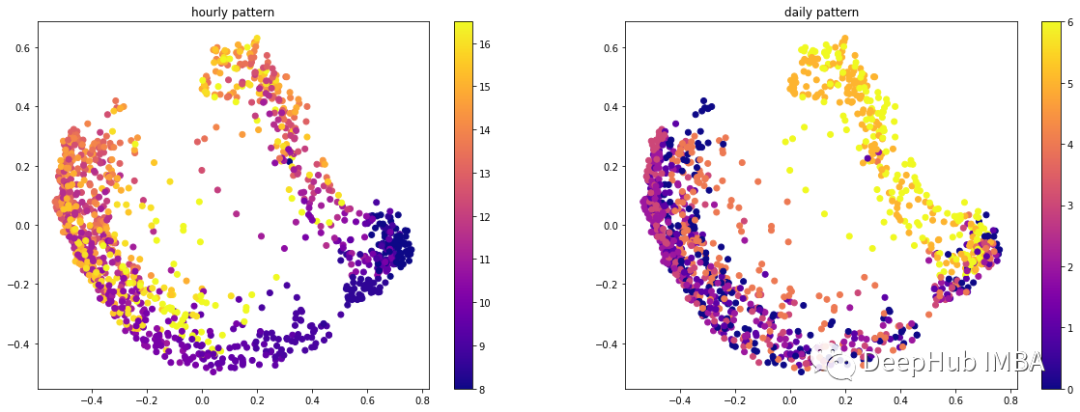
每个时间序列中所有观测数据的二维嵌入可视化
这些可视化证明了本文方法的优点。在较少的假设和较少的参数设置下,我们可以生成有意义的时间序列嵌入。
总结
在这篇文章中,介绍了众所周知的 Word2Vec 算法的推广,用于学习有价值的向量表示。我们在时间序列上下文中应用 Word2Vec,并展示了这种技术在非标准 NLP 应用程序中的有效性。整个过程可以很容易地集成到任何地方,并且很容易用于迁移学习任务。
本文代码:
https://avoid.overfit.cn/post/cf3cffbebcbc43a1856566c62b69d289
作者:Marco Cerliani












