
原文链接:http://tecdat.cn/?p=22458
原文出处:拓端数据部落公众号
简介
本文提供了一个经济案例。着重于原油市场的例子。简要地提供了在经济学中使用模型平均和贝叶斯方法的论据,使用了动态模型平均法(DMA),并与ARIMA、TVP等方法进行比较。希望对经济和金融领域的从业人员和研究人员有用。
动机
事实上,DMA将计量经济学建模的几个特点结合在一起。首先,最终预测是通过模型平均化从几个回归模型中产生的。其次,该方法是贝叶斯方法,也就是说,概率是以相信程度的方式解释的。例如,对时间t的DMA预测只基于截至时间t-1的数据。此外,新数据的获得直接导致参数的更新。因此,在DMA中,回归系数和赋予模型的权重都随时间变化。
贝叶斯方法不是现代计量经济学的主流。然而,这些方法最近正获得越来越多的关注。这其中有各种原因。首先,我们可以将其与研究中日益增多的数据量联系起来。由于技术进步,人们通常面临着许多潜在的解释变量的情况。尽管大多数变量可能并不重要,但研究者通常不知道哪些变量应该被剔除。
当然,到某种程度上仍然可以使用常规方法。但由于缺乏足够的信息,通常无法对参数进行精确估计。最简单的例子是当解释变量的数量大于时间序列中的观察值的数量时。例如,即使在线性回归的情况下,标准的普通最小二乘法估计也会出现一个奇异矩阵,导致不可能取其倒数。在贝叶斯框架下,仍然可以得出一个有意义的公式。贝叶斯方法似乎也能更好地处理过度参数化和过度拟合问题。
在最近的预测趋势中可以发现各种方法。以原油价格为例,预测方法通常可以分为时间序列模型、结构模型和其他一些方法,如机器学习、神经网络等。一般来说,时间序列模型的重点是对波动的建模,而不是对现货价格的建模。结构模型顾名思义包括因果关系,但它们通常在某些时期有很好的预测能力,而在其他时期则很差。另外,基于小波分解、神经网络等的其他方法通常忽略了其他因素的影响,只关注单一时间序列。这些使得DMA成为从业者的一个有趣的方法。
DMA的下一个方面是,它允许回归系数是随时间变化的。事实上,在经济出现缓慢和快速(结构性中断)变化的情况下,计量经济学模型的这种属性是非常可取的。当然,这样的方法也存在于传统的方法论中,例如,递归或滚动窗口回归。
理论框架
我们将简短地描述fDMA的理论框架。特别是,动态模型平均化(DMA)、动态模型选择(DMS)、中位概率模型。
动态模型平均(DMA)
DMA在[1]的原始论文中得到了非常详细的介绍。然而,下面是一个简短的论述,对于理解fDMA中每个函数的作用是必要的。
假设yt是预测的时间序列(因变量),让x(k)t是第k个回归模型中独立变量的列向量。例如,有10个潜在的原油价格驱动因素。如果它们中的每一个都由一个合适的时间序列来表示,那么就可以构建2^10个可能的线性回归模型。每个变量都可以包括或不包括在一个模型中。因此,每个变量有两种选择,构成了2^10种可能性。这包括一个只有常数的模型。因此,一般来说,有潜在的有用的m个独立变量,最多可以构建K=2^m个模型。换句话说,状态空间模型是由以下几个部分组成的
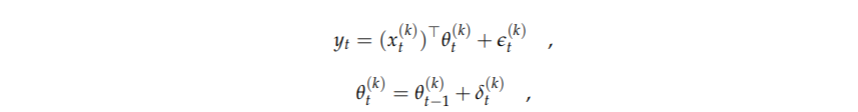
其中k = 1, ... . ,K,θt是回归系数的列向量。假设误差遵循正态分布,即e(k)t∼N(0,V(k)t)和δ(k)t∼N(0,W(k)t)。
在此请注意,有m个潜在的解释变量,2m是构建模型的上限。然而,本文描述的所有方法(如果没有特别说明的话)都适用于这些2m模型的任何子集,即K≤2m。
动态模型选择(DMS)
动态模型选择(DMS)是基于相同的理念,与DMA的理念相同。唯一的区别是,在DMA中进行的是模型平均化,而在DMS中是模型选择。换句话说,对于每个时期t,选择具有最高后验概率的模型。这意味着,只需将公式修改为
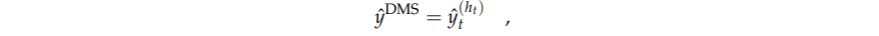
其中HT表示k模型。
一个例子:原油市场
我们举一个原油市场的例子。据此可以说,在哪些时间序列可以作为预测现货原油价格的有用解释变量方面,存在着不确定性。
xts对象crudeoil包含来自原油市场的选定数据,即。
-WTI代表WTI(西德克萨斯中质油)现货价格,以每桶计。
- MSCI代表MSCI世界指数。
- TB3MS代表3个月国库券二级市场利率(%)。
- CSP代表粗钢产量,单位是千吨(可以作为衡量全球经济活动的一种方式)。
- TWEXM代表贸易加权的指数(1973年3月=100)。
- PROD代表原油产品供应量,单位为千桶。
- CONS代表经合组织的原油产品总消费量。
- VXO代表标准普尔100指数的隐含波动率(即股票市场波动率)。
这些数据的频率为每月一次。它们涵盖了1990年1月至2016年12月的时期。
xts对象的趋势包含来自谷歌的关于选定搜索词的互联网数量的数据。
- stock_markets代表Google Trends的 "股票市场"。
- interest_rate代表Google Trends的 "利率"。
- economic_activity表示 "经济活动 "的Google趋势。
- exchange_rate代表 "汇率 "的谷歌趋势。
- oil_production表示 "石油生产 "的Google趋势。
- oil_consumption代表 "石油消费 "的谷歌趋势。
- market_stress代表Google Trends的 "市场压力"。
这些数据也是以月度为频率的。它们涵盖了2004年1月至2016年12月这段时间,因为谷歌趋势没有涵盖更早的时期。从经济角度来看,考虑这些时间序列的对数差分是合理的
R> drivers <- (lag(crudeoil[ , -1], k = 1))[-1, ]
R> l.wti <- (diff(log(wti)))[-1, ]
R> l.drivers <- (diff(log(driv )))[-1, ]
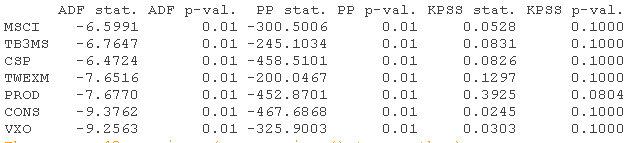
R> archtest(ld.wti)
R> descstat((ld))
除了PROD的一些问题,所有的时间序列都可以在5%的显著性水平上被认为是平稳的。对于WTI差分也存在ARCH效应。因此,在DMA中考虑指数加权移动平均(EWMA)估计方差似乎是合理的。此外,还可以测试一些遗忘因子。根据建议,对月度时间序列采取κ=0.97。所有的方差都小于1。因此,似乎没有必要对时间序列进行重新标准化。在DMA的估计中,采取initvar=1似乎也足够了。
DMA(y = lwti, x = ldrivers,
+ alpha = ra, lambda = rl,
meth = "ewma" )
根据最小化RMSE,最佳DMA模型是α=0.99和λ=0.97的模型。因此,对这个模型稍作研究。
plot(x$y, type="l", ylim=c(min(x$y,x$y.hat),max(x$y,x$y.hat)), xlab="", ylab="", main="实际值和预测值", axes = F)
比较图1和图2可以看出,在市场的动荡时期,DMA迅速适应,对有更多变量的模型赋予更高的权重。事实上,这与图3一致。在这一时期,所有解释变量的相对变量重要性都在上升。我们还可以看到,自2007年以来,发达的股票市场的作用有所增加。然而,在2013年之后,这种作用变得越来越小;而其他变量的作用开始增加。这一点非常明显,特别是对于汇率。
图3应与图4可以看出。虽然,相对变量的重要性可能很高,但这个变量的回归系数的预期值可能在0左右。事实上,高的相对变量重要性同时观察到MSCI、CSP和TWEXM的预期回归系数不为零。所以,这个分析现在证实了这三个因素在2007年和2013年之间对原油价格起到了重要的预测作用。自2013年以来,股票市场的作用减少了,被汇率所取代。在2013年前后,最重要的作用是由发达股票市场发挥的。
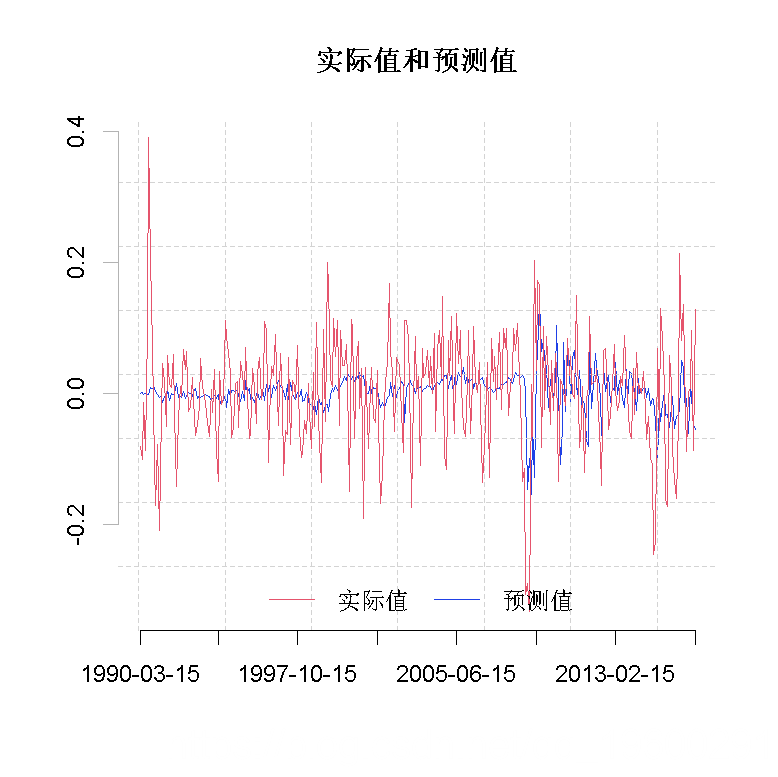
图1
for (i in 1:7)
{
inc[i+1] <- floor(i * nrow( post.incl)/7)
}
plot( exp.var, type="l" ylim=c(0,ncol(x$models)) main="变量数量期望值 ", axes = F)
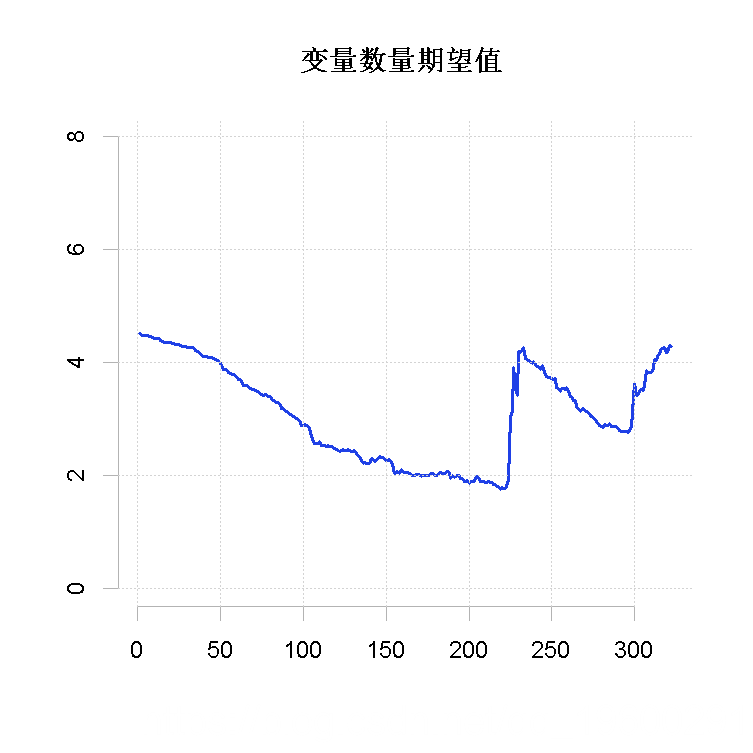
图2
for (i in 1:(ncol( post.incl)-1))
plot( post.incl[,i+1], type="l", col=col[i+1], ylim=c(0,1), xlab="", ylab="", main="后包含概率", axes = F)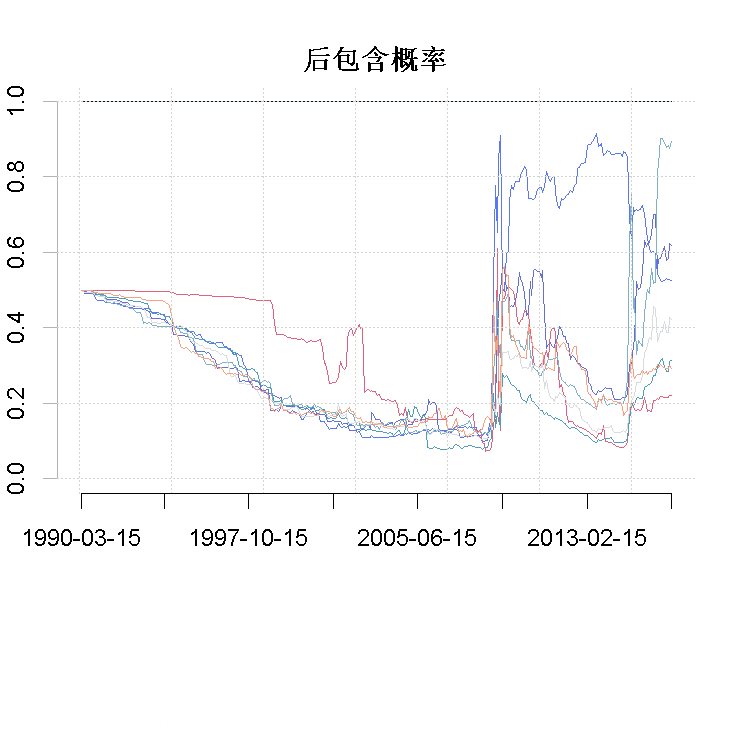
图3
for (i in 1:(ncol( exp.coef.)))
{
plot( exp.coef.[,i], type="l", col=col[i] )
}
plot(index( exp.coef.[,i]), rep(0,length(x$exp.coef.[,i])
xaxt='n', xlab="", ylab="", main="系数"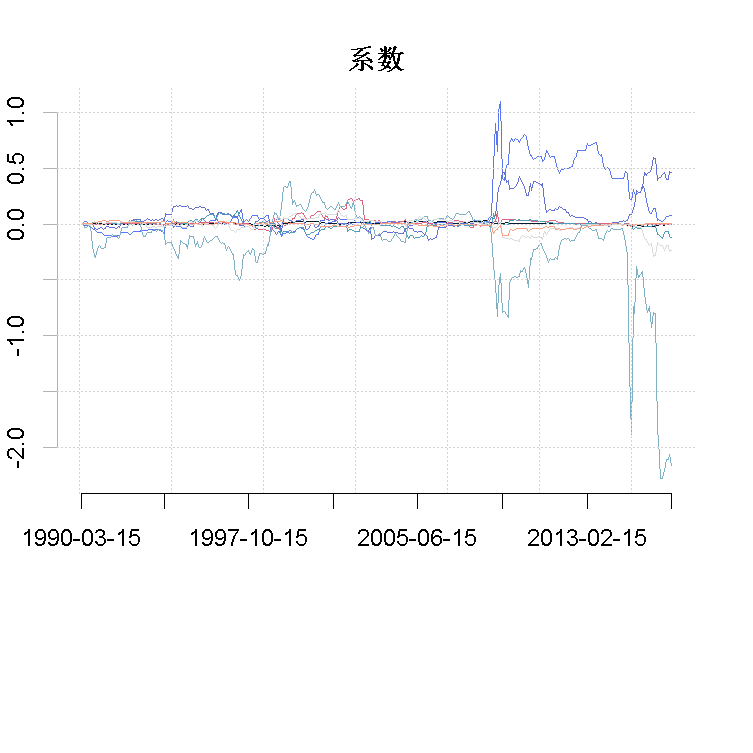
图4
最后,可以怀疑有一些模型在某种意义上优于其他模型。换句话说,模型的选择会比模型的平均数更有优势。这可以通过分析DMS和中位概率模型来检查。然而,从图5可以看出,没有一个模型的后验概率超过0.5。其次,2007年之后和2013年之后,没有一个模型似乎更有优势。
也可以质疑所应用的方法对不同的参数设置是否稳健。例如,如果其他遗忘因子α和λ会导致不同的结论。图6展示了来自对象g的所有模型的所有解释变量的相对变量重要性,即α={1, 0.99, 0.98, 0.97, 0.96, 0.95}和λ={1, 0.99, 0.98, 0.97, 0.96, 0.95}的所有组合。确切的数值不同,但图形在时间上遵循的路径或多或少是相同的。这意味着给定解释变量的作用递增,对遗忘因素设置不同的值是稳健的。
for (i in 1:(ncol(x$post.mod)-1))
{
plot(x$post.mod[,i], type="l"
}
plot(x$post.mod[,i+1], type="l" ylab="", main="后验模型概率", axes = F)
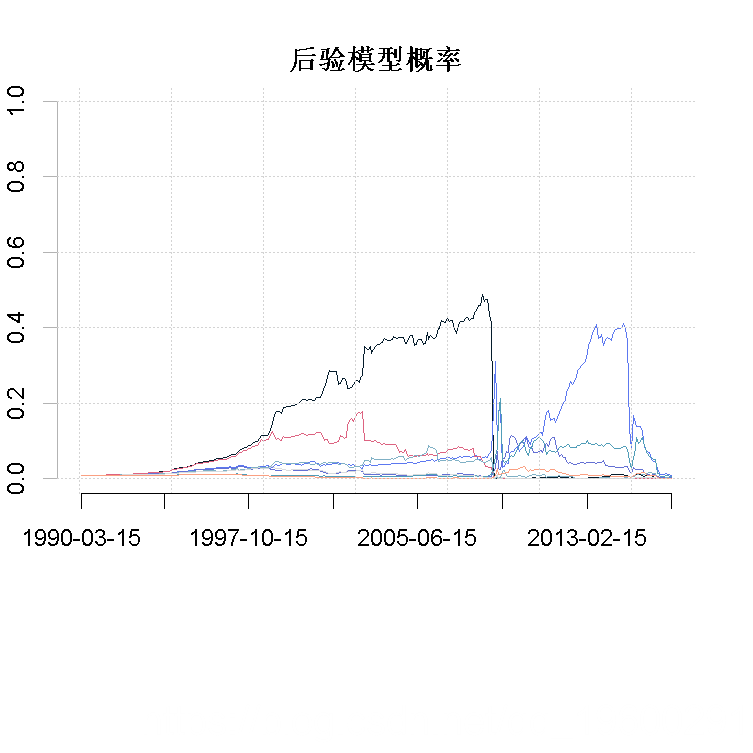
图5
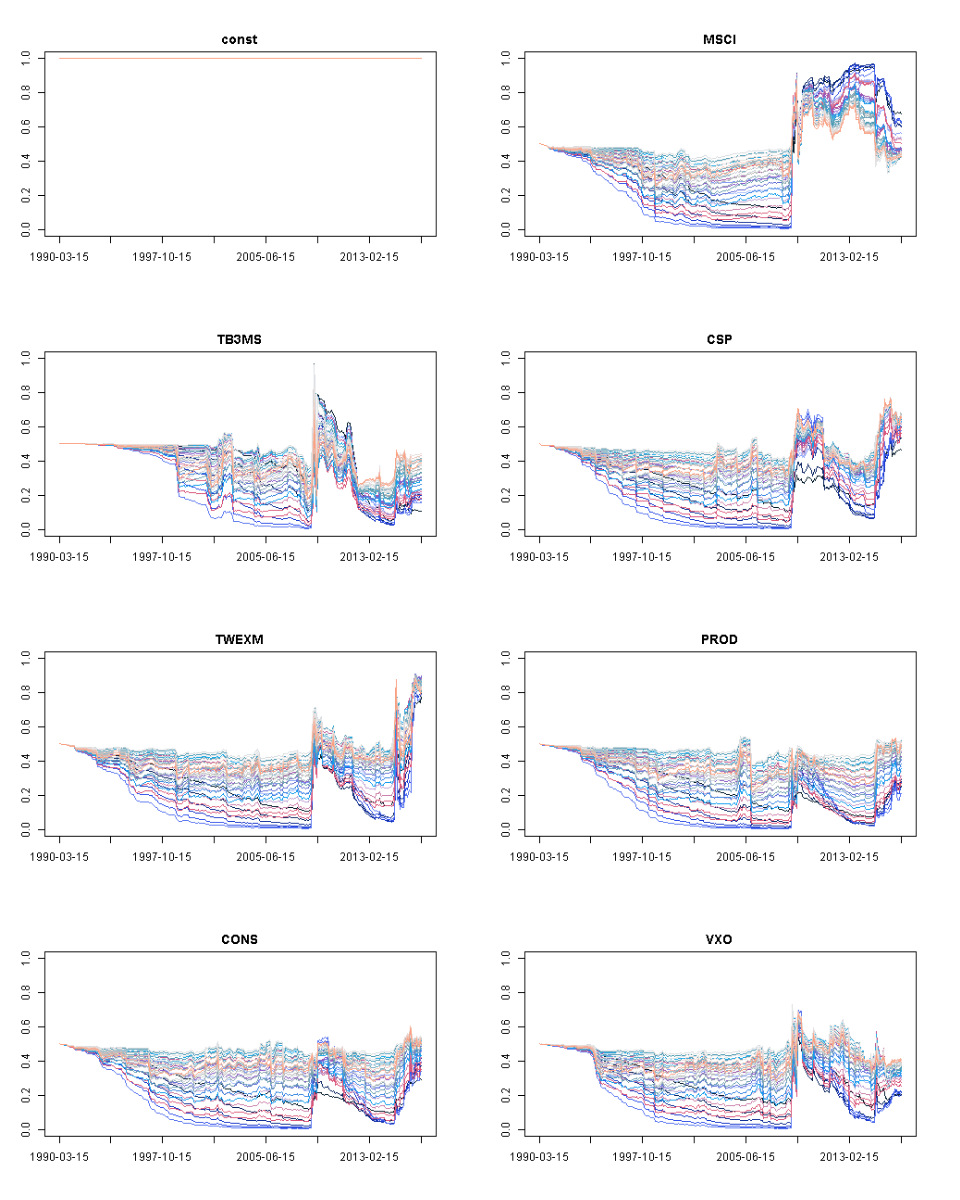
图6
最后,可以将选定的模型与一些替代预测进行比较。
R> altm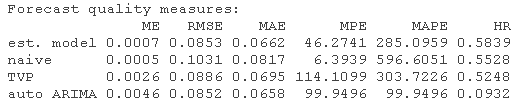
所选的DMA模型的RMSE比两个基准预测要小,但与Auto ARIMA相当。MAE的情况也类似。然而,Auto ARIMA的MAE比选定的DMA模型小。另一方面,选定的DMA模型在所有竞争性预测中具有最高的命中率。更精确的比较可以通过Diebold-Mariano检验来进行。
DieMtest(y = (lwti))
假设5%的显著性水平,可以拒绝简单预测的原假设,也就是预测的准确性低于所选的DMA模型。换句话说,所选模型在某种意义上超过了简单预测。
参考文献
1. Raftery, A.; Kárný, M.; Ettler, P. Online Prediction under Model Uncertainty via Dynamic Model Averaging: Application to a Cold Rolling Mill. Technometrics 2010, 52, 52–66. [CrossRef] [PubMed]
2. Barbieri, M.; Berger, J. Optimal Predictive Model Selection. Ann. Stat. 2004, 32, 870–897. [CrossRef]

最受欢迎的见解
1.在python中使用lstm和pytorch进行时间序列预测
2.python中利用长短期记忆模型lstm进行时间序列预测分析









