
导读
咪咕是中国移动旗下的视频科技公司,门户系统是其核心业务之一。 为满足用户的多样化需求,咪咕计划对其数据库进行升级。 经过对中国主流国产数据库的测试评估后,咪咕选择了 TiDB,并成功将其落地于门户系统云化项目。 TiDB 为咪咕在业务增长、高可用性、性能提升、数据整合等方面带来了显著价值。 未来,咪咕计划拓展 TiDB 在更多业务场景中的应用,助力其业务创新和降本增效 。

咪咕简介
咪咕视讯科技有限公司(简称:咪咕)是中国移动旗下咪咕文化科技有限公司的全资子公司,是中国移动在视频领域的唯一运营实体,主要产品包括咪咕视频、咪咕影院、咪咕直播等。截止 2023 年 6 月,咪咕视频全场景有效月活用户数超 3.6 亿,数字内容涵盖 4818 万条视频、10000+ 部精彩大片、院线票务覆盖 12000 家影院、1200+ 路 音视频直播等。咪咕在 2023 年打造了杭州亚运会、男篮世界杯、女足世界杯、成都大运会等多个口碑视听体验 。
分布式数据库选型的能力要求
门户系统是咪咕视讯的核心业务系统之一,提供的业务功能包括大屏挂件、直播中台、应用管理平台、策略平台、大屏展现、直播展现、任务调度、车载服务等。这些功能直接关系到组织内外信息的高效传递和流动。门户系统的服务范围广泛,旨在满足用户多样化、灵活性、高并发和高可用需求。因此门户系统底层依赖的数据库需要具备高性能、高可用、灵活弹性的特点,同时还需要具备方便业务开发的用户使用体验,满足门户系统云化微服务改造的要求。
随着业务的快速发展,特别是在 世界杯、热门赛事、热播电视剧等超级流量爆发下 ,门户系统经历了多次改版、扩容,仍然不能满足飞速增长的日活用户及用户个性化体验的要求, 在灵活性、插件化、微服务、云化部署、数据库服务等方面有待升级 。咪咕计划通过数据库的原生分布式改造,全面提升数据库的服务能力,选型的要求包括:
● 原生分布式架构
满足业务快速变化的需求,不对业务产生过多的侵入,数据库须采用原生分布式架构,计算和存储可按需扩展,具有原生分布式的高可用机制,非中间件分库分表架构,适配云原生和微服务环境。
● 后端引擎能力
支持本地和分布式事务,满足 ACID 属性要求,具有分布式一致性共识机制,达到常规的事务隔离级别,并能正确高效地处理事务异常,具有全局索引能力。
● 前端开发兼容性
数据库须兼容和延续现有的应用架构和代码,具有相应的开发兼容性、字符集、客户端的前端支持要求。
● 恢复和备份能力
支持物理备份、逻辑备份、全量和增量备份,支持将集群恢复到任意时间点和闪回,提供金融级的灾备能力。
此外,安全能力、可视化运维、技术生态、售后服务体系的支撑能力也成为数据库选型的考察重点。咪咕技术团队对中国主流的国产数据库做了 9 类、34 科、共 244 个项目的测试评估,TiDB 以最高分入选。
TiDB 在咪咕云原生场景的落地
咪咕技术团队从技术论证、前期准备、分批割接、并行运行、完全割接等环节出发,制定了稳妥的实施方案,保障了 TiDB 在门户系统云化项目的落地。 咪咕在 3 个独立的资源池分别部署 3 套 TiDB 集群,集群间使用 TiCDC 组件完成数据同步,业务连接到主集群进行读写,并可实现快速的容灾切换。通过访问控制策略,使得备集群在作为应急备援切换目标的同时,也保持着多中心多活只读服务的承担,充分发挥资源能力。
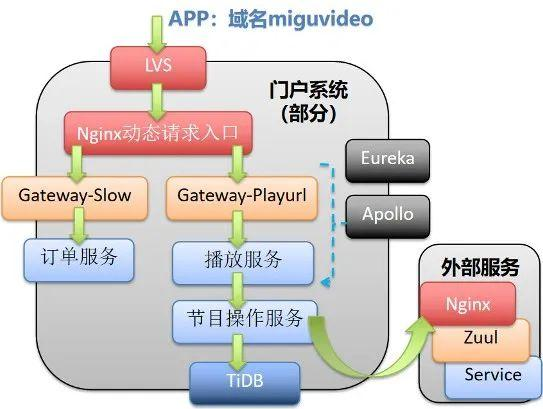
微服务架构示意图
咪咕门户系统从 2023 年 7 月切割到 TiDB 后,已经稳定运行超过 100 天 ,期间经历了女足世界杯、成都大运会、男篮世界杯、杭州亚运会四个重大赛事业务高峰的压力。在重大赛事期间 TiDB 运行非常平稳, 业务峰值流量 QPS 大于 20K,TPS 大于 8K,且平均响应延时低于 100ms 。
TiDB 在落地过程中得到了咪咕门户改造项目负责人的高度评价:
TiDB 总体上能够较好适配咪咕当前的技术架构和运行系统,满足开发和运维关注的长期发展的重点,包括微服务框架、开发兼容、运维质量和效率提升等,所遇到的问题都能较快地解决。
应用价值
● 匹配业务增长,轻松应对瞬间高峰
TiDB 原生分布式架构具备灵活的弹性伸缩能力,可匹配业务的特点分别扩展计算与存储能力,提供强劲的性能支持。如在大促活动前进行快速的扩容,活动中短时高峰实现应急在线扩容,整个过程对业务透明,无需人工干预。
● 高可用架构,提升更好的业务连续性
实现数据库和应用系统多中心提供对等服务,充分发挥集群所有节点的工作能力,并且互为冗余,既提高利用率又降低风险。TiDB 在集群内部各个组件均采用冗余设计,避免了任何单点的故障,通过 TiCDC 同步数据到异地灾备集群,为实现跨机房的高可用性提供了保障。
● 具有更好的性能,承载更多业务
通过实际运行对比,TiDB 集群在整体硬件资源少于原 MySQL 集群的情况下,达到原有 MySQL 集群性能的 1.88 倍,即在原有硬件资源的基础上提升了约 90% 的业务承载能力。
● 为数据整合、挖掘数据价值提供基础
原有架构的几十套 MySQL 数据库相互独立,烟囱式发展,无法将各分散的业务进行关联分析,从而挖掘数据价值。TiDB 将原来十几套 MySQL 数据库归集到一个集群中,实现多个业务系统数据的实时汇聚、实时反馈、实时洞察和实时变现,带来极致的用户体验。
未来展望
随着 TiDB 7.x 版本的发布,TiDB 引入了资源管控(多租户)、DDL 并行执行框架等新特性。咪咕视讯将积极探索这些新功能,逐步拓展 TiDB 在更多业务场景中的应用,并将 TiDB 最佳实践推广至其他子公司,助力业务创新和降本增效。












