
前言
mysql数据库是现在应用最广泛的数据库系统。与数据库打交道是每个Java程序员日常工作之一,索引优化是必备的技能之一。
为什么要了解索引
真实案例
案例一:大学有段时间学习爬虫,爬取了知乎300w用户答题数据,存储到mysql数据中。那时不了解索引,一条简单的“根据用户名搜索全部回答的sql“需要执行半分钟左右,完全满足不了正常的使用。
案例二:最近线上应用的数据库频频出现多条慢sql风险提示,而工作以来,对数据库优化方面所知甚少。例如一个用户数据页面需要执行很多次数据库查询,性能很慢,通过增加超时时间勉强可以访问,但是性能上需要优化。
索引的优点
合适的索引,可以大大减小mysql服务器扫描的数据量,避免内存排序和临时表,提高应用程序的查询性能。
索引的类型
mysql数据中有多种索引类型,primary key,unique,normal,但底层存储的数据结构都是BTREE;有些存储引擎还提供hash索引,全文索引。
BTREE是最常见的优化要面对的索引结构,都是基于BTREE的讨论。
B-TREE
查询数据最简单暴力的方式是遍历所有记录;如果数据不重复,就可以通过组织成一颗排序二叉树,通过二分查找算法来查询,大大提高查询性能。而BTREE是一种更强大的排序树,支持多个分支,高度更低,数据的插入、删除、更新更快。
现代数据库的索引文件和文件系统的文件块都被组织成BTREE。
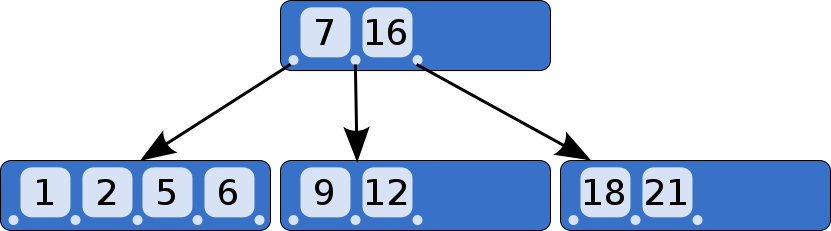
btree的每个节点都包含有key,data和只想子节点指针。
btree有度的概念d>=1。假设btree的度为d,则每个内部节点可以有n=[d+1,2d+1)个key,n+1个子节点指针。树的最大高度为h=Logb[(N+1)/2]。
索引和文件系统中,B-TREE的节点常设计成接近一个内存页大小(也是磁盘扇区大小),且树的度非常大。这样磁盘I/O的次数,就等于树的高度h。假设b=100,一百万个节点的树,h将只有3层。即,只有3次磁盘I/O就可以查找完毕,性能非常高。
索引查询
建立索引后,合适的查询语句才能最大发挥索引的优势。
另外,由于查询优化器可以解析客户端的sql语句,会调整sql的查询语句的条件顺序去匹配最合适的索引。

-- 表创建语句
CREATE TABLE people (
last_name VARCHAR(20) NOT NULL,
first_name VARCHAR(20) NOT NULL,
gender CHAR(1) NOT NULL, birth date NOT NULL,
KEY last_first_name_gender_key(last_name, first_name, gener)
);

一,全值匹配
查询语句where条件和索引中的所有列进行匹配。
1 SELECT * FROM people WHERE last_name='zhang' AND first_name='yin' AND gender='m';
二,最左前缀匹配
查询条件可以匹配索引的最左若干列。注意关键词”最左前缀“。
-- 可以使用部分索引"last_name"
SELECT * FROM people WHERE last_name='zhang' AND gender='m';
-- 无法使用索引
SELECT * FROM people WHERE first_name='zhang' AND gender='m';
三,列前缀匹配
查询中的like条件,在有些场景下也可以使用索引。如 last_name like 'zh%'可以使用索引,而last_name like '%ing'则无法使用索引。
-- 可以使用索引,因为BTREE的节点比较key值时是从key值得最左侧开始匹配
SELECT * FROM people WHERE last_name like 'zhang%' AND gender='m' ;
四,范围查询
索引的列也支持范围查询。
SELECT * FROM people WHERE last_name > 'zhang' AND last_name <'wang'
五,排序
ORDER BY语句在特定情况下也支持用索引来排序来提高性能。
EXPLAIN SELECT * FROM people WHERE last_name = 'zhang' ORDER BY first_name ASC
六,限制
1,查询列不能参与表达式运算,否则无法使用索引。

--表设计中没有age列,以示参考
--假设age是索引中一部分,这样的查询将无法使用到索引
SELECT * FROM people WHERE last_name='zhang' AND age+3>28;
--这样写就可以使用索引
SELECT * FROM people WHERE last_name='zhang' AND age>25;

2,如果不是从索引的最左列开始,则无法使用索引。如,根据first_name、gender或者查找的查询无法使用索引。
-- 不是从last_name开始匹配,所以无法使用索引
SELECT * FROM people WHERE first_name='zhang' AND gender='m'
3,不能跳过索引中的列。
-- 不能跳过first_name查询,否则只有last_name列用到了索引
SELECT * FROM people WHERE last_name='zhang' AND gender='m'
4,如果查询中某个列是范围查询(like,between,>,<等),则其右边所有的列都无法使用索引。
-- 由于first_name用了like查询,所以gender列无法使用索引了
SELECT * FROM people WHERE last_name='zhang' AND first_name LIKE '%in' AND gender='m';
高效索引策略
前面讲到了各种可以使用索引的查询情况,下面讲如何建立高效的索引。
1,建立多列索引
建立多列的索引,而不是每一列都建立单独的。因为在mysql服务器在查询分析后,最终只能根据查询匹配到一个索引(或者没有)并使用。所以,假设多列上分别都建立了单独索引,即使组合查询用到了多列,最终也只有一列用到了索引。
所以,假设你最常见的查询是根据last_name、first_name和gender来查询,应该建立包含三列的索引。
ALTER TABLE people ADD INDEX idx_name_gender(last_name, first_name , gender);
2,索引列的顺序
在多列B-TREE索引中,意味着索引是按照最左列开始,从左往右进行排序的。一个设计经验法则,将”选择性高“的列放在索引最左列。这样有助于索引经过最少的比较找到目标元组。
索引列选择性:不重复的索引值与表的全部记录总数的比值,0<T<=1。唯一索引列的选择性是1。索引的选择性越高则查询效率越高,可以”更早地”过滤掉不匹配地记录。
假设要建立 last_name, first_name , gender 三列的索引。
T(last_name)= select count(distinct last_name) / count(*) ;
T(first_name)= select count(distinct first_name) / count(*) ;
T(gender)= select count(distinct gender) / count(*) ;
很显然,last_name和first_name应该放到索引的前面(以实际情况为主)
结尾
了解到了常见的索引策略和查询技巧,但是怎么在实际项目中应用并排查现存数据库中sql的性能缺陷?下一篇将介绍mysql数据库的explain关键字,总结和分析慢sql常见技巧。













