
此文已由作者温正湖授权网易云社区发布。
欢迎访问网易云社区,了解更多网易技术产品运营经验。
MySQL Group Replication(MGR)框架让MySQL具备了自动主从切换和故障恢复能力,举single primary(单主)模式为例,primary作为主节点对外提供读写服务,是唯一的可写节点,其他节点均为secondary节点,可提供读服务。在传统的master-slave主从复制模式下,如果master发生了crash,MySQL DBA需要手动将slave升级为新master(比如关闭只读开关等),旧的master重启后需执行change master to进行复制关系重建,并执行start slave开启复制。如果是semi-sync半同步复制,还需要进行半同步参数配置。但在MGR模式下MySQL能自动发现primary crash,通过选主产生新的primary节点对外提供读写服务。旧的primary节点重启后,DBA只需要执行start group_replication即可将crash节点重新加入到Group中,在运维便利性和系统健壮性上有极大的提升。
本文分为3个部分,先分析MGR的成员管理机制,讲解crash的节点如何重新加入到Group中,然后再分析该节点加入Group后如何进行故障恢复使其自身状态从Recovery变为ONLINE,最后分析目前存在的不足。
一、成员管理
视图及视图切换
MGR以组视图(Group View,简称视图)为基础来进行成员管理。视图指Group在一段时间内的成员状态,如果在这段时间内没有成员变化,也就是说没有成员加入或退出,则这段连续的时间为一个视图,如果发生了成员加入或退出变化,则视图也就发生了变化,MGR使用视图ID(View ID)来跟踪视图的变化并区分视图的先后时间。在进一步介绍之前,我们先看一个图:
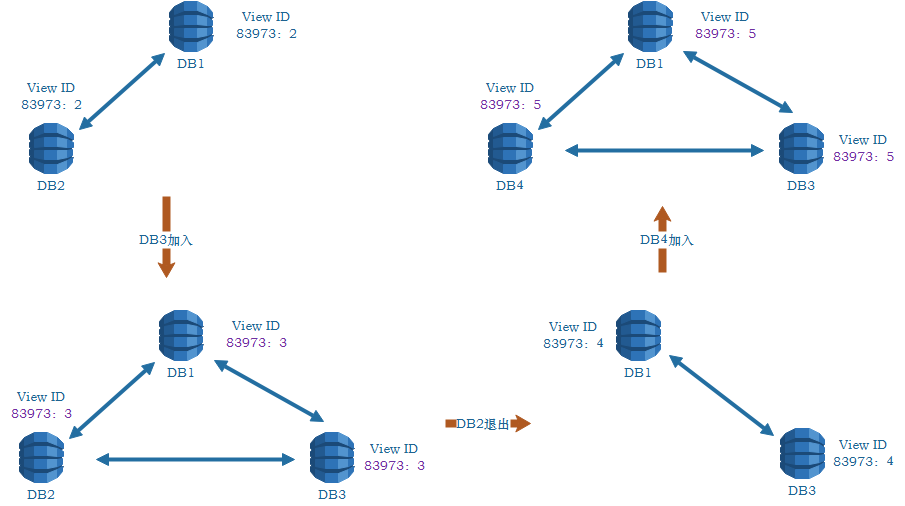
Group当前的视图ViewID为83973:2,该视图中包括2个成员,分别为DB1和DB2;一段时间后DB3节点请求加入Group,成功加入后视图切换为83973:3,包括3个成员,分别为DB1、DB2和DB3;之后DB2节点crash而退出了Group,视图切换为83973:4;之后DB4加入Group,视图切换为83973:5。从上面的图例我们可以发现,ViewID由2部分组成,分别如下。
前缀部分:是在这个Group初始化时产生,为当时的时间戳,Group存活期间该值不会发生变化。所以,该字段可用于区分2个视图是否为同一个Group的不同时间点;
序号部分:Group初始化时,第一个视图的序号从1开始,其成员只有1个,为进行初始化的节点。以后Group出现任何成员的加入或退出序号都需要增一。
上面所述的是同个Group的视图的变化情况,这里再补充说明下Group定义。一个组Group是在节点参数为group_replication_bootstrap_group为on的条件下执行start group_replication产生的,如果要加入现有的Group,节点需要确保group_replication_bootstrap_group为off。一个节点加入Group后,需要连到其他节点使自己的数据uptodate,如果该Group其他成员都已不在线,那么就无法进行uptodate,在这种情况下,就需要设置group_replication_bootstrap_group为on来初始化新的Group。
Group的当前视图可以通过performance_schema系统库下的replication_group_member_stats表中查到,下图表示该Group初始化时间为2018/2/7 14:54:13,已经发生了321次视图切换:
node1>select * from replication_group_member_stats limit 1\G
*************************** 1. row ***************************
CHANNEL_NAME: group_replication_applier
VIEW_ID: 15179864535059527:321
MEMBER_ID: 2e7b6e78-0bd3-11e8-9ba2-c81f66e48c6e
COUNT_TRANSACTIONS_IN_QUEUE: 0
COUNT_TRANSACTIONS_CHECKED: 382502
COUNT_CONFLICTS_DETECTED: 0
COUNT_TRANSACTIONS_ROWS_VALIDATING: 340084
TRANSACTIONS_COMMITTED_ALL_MEMBERS: aaaaaaaa-aaaa-aaaa-aaaa-aaaaaaaaaaaa:1-117137653:117596712-117597349
LAST_CONFLICT_FREE_TRANSACTION: aaaaaaaa-aaaa-aaaa-aaaa-aaaaaaaaaaaa:117273119
COUNT_TRANSACTIONS_REMOTE_IN_APPLIER_QUEUE: 25586
COUNT_TRANSACTIONS_REMOTE_APPLIED: 356916
COUNT_TRANSACTIONS_LOCAL_PROPOSED: 0
COUNT_TRANSACTIONS_LOCAL_ROLLBACK: 0
1 row in set (0.00 sec)
视图切换实现
上面我们简单一个节点加入Group后,需要连到其他节点使自己数据uptodate,那么基于什么来判断自己的数据uptodate了呢。下面我们详细介绍一个节点如何加入到Group中,用图说话,如下:
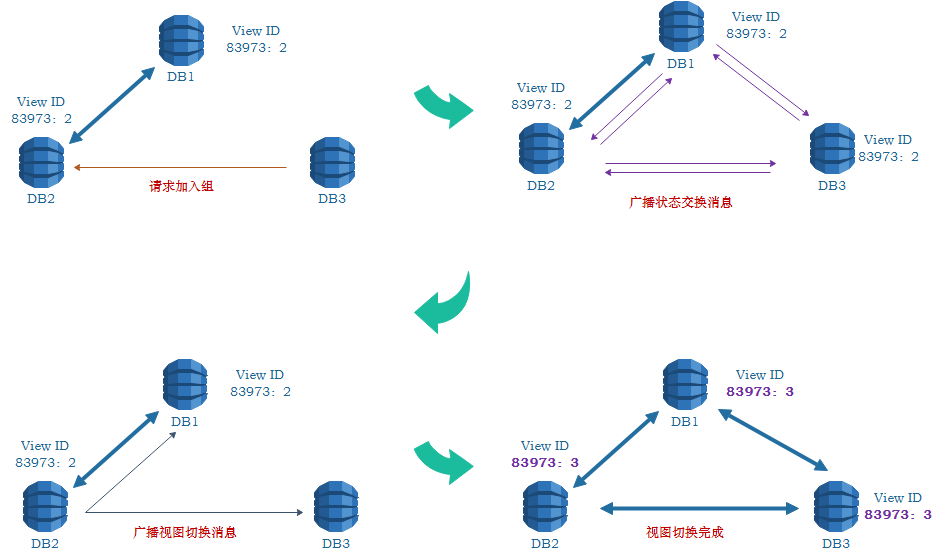
一个节点请求加入Group时,其首先会根据配置的group_replication_group_seeds参数跟Group的种子成员建立TCP连接 (Gcs_xcom_control::do_join())。该种子成员会根据自己的group_replication_ip_whitelist(ip白名单)检查是否允许新节点加入,MGR默认不限制新节点的ip。连接建立后,新节点发送请求申请加入组,如上图左上所示;收到请求后,种子成员广播视图变化的消息给Group中的所有节点,包括申请加入的节点,如右上所示;各节点收到消息后开始做视图切换。每个节点都会广播一个状态交换消息,每个交换消息包含了节点的当前状态和信息,如图左下所示。发送了交换消息后,各个节点开始接收其他节点广播的消息,将其中的节点信息更新到本节点所维护的成员列表中。状态交换消息像事务数据包一样走相同的Paxos(Mencius)协议进行发送,当收到所有成员的状态交换消息时,通信模块将完整的新视图封装为视图数据包(view_change_log_event,即vcle的前身,但没有数据库当前的快照版本信息),Group中的每个节点基于MGR的通信模块将其返回给全局事务认证模块的消息队列(简称认证队列)。至此,视图切换即告结束。视图切换过程中不会影响在线成员对外服务。
视图数据包的作用
完成视图切换只是成员加入Group要做的第一步,只是说明该成员可以接收到Group中通过Paxos协议达成共识的消息,并不意味着可以将成员设置为ONLINE(上线)对外提供服务。原因是新成员还需要进行数据同步,建立起正确的数据版本(recovery_module->start_recovery)。之后才能执行Paxos协议消息,进而上线提供正常的用户访问服务。
在这过程中,视图数据包发挥了关键性的作用。如上所述,视图数据包通过Paxos放入消息队列,那么各节点依次处理消息队列中的数据包时就能够发现视图数据包(Plugin_gcs_events_handler::on_view_changed),将视图数据包封装为view_change_log_event后写入Relay log文件中,group_replication_applier通道的并行复制线程读取Relay log中的vcle并将其写入到Binlog文件中。这样,Binlog文件中的事务就被vcle划分为多个区间,每个区间都代表一个视图。vcle中包括了ViewID和用于进行全局事务认证模块进行事务认证的冲突检测数据库。基于vcle,我们可以把节点上线前的过程划分为2个阶段,分为前一个视图数据恢复和本视图缓存事务执行。第一个阶段又可以细分为本地恢复和全局恢复。下面分析这三个子过程的具体实现。
二、故障恢复实现
在开始介绍前,需简单介绍下MGR所涉及的数据复制及其通道(channel),MGR正常运行时,即Group中各节点均在线,节点间通过Paxos协议传输数据,异地事务经过认证后写入group_replication_applier Relay log中,由group_replication_applier通道的复制线程负责回放。当有节点加入Group时,需要用到另一个复制通道group_replication_recovery,它是一个传统的Master-Slave异步复制通道。
MGR故障恢复代码位于MGR代码目录(rapid\plugin\group_replication\src)的Recovery.cc文件下,节点的故障恢复交由单独的恢复线程(launch_handler_thread -> recovery_thread_handle)执行。
本地恢复阶段
第一步:进行故障恢复初始化,包括故障恢复线程初始化,Group成员信息初始化等。
第二步:启动group_replication_applier复制通道。对于故障恢复场景,待加入的成员不是新节点,也就是说其曾经加入过该节点,其group_replication_applier通道的Relay log可能还有一些Binlog未回放。所以需要先将这部分Relay log回放掉。由于有后面所述对的第三步,非Group初始化场景下,其实可以跳过回放本地恢复的环节,直接从其他节点复制所需的数据,但引入本地恢复的好处在于可提高恢复性能,无需在拉取这部分Binlog,提高恢复过程健壮性,减小所需Binlog被purge的风险。
确认对应通道的复制线程空闲后,阻塞(suspend)认证队列的处理线程,即允许新的Paxos消息入队但不进行处理。这样,本视图的Paxos消息会在认证队列中堆积起来。
若该节点是Group的第一个节点,即Group初始化场景,则故障恢复结束,可将此节点置为在线状态。
全局恢复阶段
第三步:完成本地Relay log回放后,进入故障恢复第三步,即State transfer是通过group_replication_recovery复制通道从Group其他在线节点拉取本节点欠缺的非本视图的数据。与传统的Master-Slave复制配置不同,MGR中仅需为其配置账号和密码即可,配置方式形如:CHANGE MASTER TO MASTER_USER='rpl_user', MASTER_PASSWORD='rpl_pass' FOR CHANNEL 'group_replication_recovery'。显然,该通道是基于GTID以MASTER_AUTO_POSITION的方式进行。恢复线程随机选择一个在线节点(donor),调用rpl_slave.cc中的request_dump函数建立与donor的复制关系,该函数携带了恢复节点的gtid_executed信息。donor端会逆序遍历其Binlog文件,通过判断Binlog文件起始的Previous-GTIDs来找到第一个不属于gtid_executed的事务,从该事务开始进行数据复制。
MGR实现了全局恢复阶段的容错能力,能够处理异步复制过程中出现的绝大部分情况:
recovery_aborted:表示主动退出故障恢复过程。
on_failover:表示donor节点离开了Group,故障恢复线程选择另一个在线节点作为donor,连上后继续进行异步复制。该场景下,从退出的donor节点复制而来未回放的Relay log不会purge,而是完成回放后再继续从当前donor进行复制。
donor_channel_applier_error:表示本节点回放从donor节点复制过来的事务时出错,故障恢复线程也会选择另一个节点作为donor继续进行数据复制,但与on_failover不同的是,该场景下,未回放的Relay log被purge,从出错事务位置开始从新donor节点重新拉取Binlog进行尝试。
donor_transfer_finished:这是正常的情况,表示全局恢复已经完成了所需数据复制。可进入到缓存事务执行阶段。那么如何获知已经复制完所需数据呢,这就用到了我们前述的vcle,复制vcle后,会判断其携带的ViewID,如果其与节点当前的ViewID同等,就表示异步复制可以停止了。在开始下一步处理前,还故障恢复线程还会基于vcle初始化认证所需的冲突检查数据库。
除了上述情况外,还可能出现所选的donor无法连接(比如配置了IP白名单)或所需的Binlog已经被purge的情况。对于该情况,故障恢复线程会选择其他donor进行重试,可通过参数group_replication_recovery_reconnect_interval和group_replication_recovery_retry_count对重试行为进行控制,第一个参数表示重试的间隔时间,默认为1分钟,第二个参数为重试的次数, 默认为10次。
缓存事务执行
第四步:先唤醒在第二步被阻塞的认证队列处理线程,让本节点逐步跟上Group中的其他节点,进而将其设置为在线(ONLINE)。那么,应该在什么时候允许节点上线呢,MGR引入参数group_replication_recovery_complete_at进行控制,可选TRANSACTIONS_CERTIFIED或TRANSACTIONS_APPLIED。分别表示认证队列为空或回放完所有已认证的事务时。虽然判断条件很明确,但实际场景下代码实现却较为困难,因为负载可能是持续的,状态是动态变化,不会存在静态的事务均已认证或均已回放的状态。
对于单主模式,在开始处理认证队列之前,需要先将冲突检测标志位开启,这样在缓存的队列请求时就会将事务携带的快照版本跟冲突检测数据库版本进行对比,决定事务是回滚还是提交。此时开启冲突检测的原因是缓存的事务有部分是在primary节点回放之前视图产生的Relay log过程时执行的,也就是说,事务执行的时候,其基于的数据并不是最新的数据,所以可能会被回滚,如果未开启冲突检测就会导致数据不一致。这里需要说明一点,就是无论是否开启冲突检测,经过Paxos发送的消息都会进入认证队列,然后依次进行处理。代码实现上,冲突检测只是认证的一个环节,除此之外,还需要为事务确定gtid,并确保相同的事务在各个节点产生的gtid是相同的。
成员上线与出错处理
第五步:在达到了group_replication_recovery_complete_at所确定的条件后,发送Recovery_message::RECOVERY_END_MESSAGE消息,通知Group中的各个节点,将该节点设置为在线状态。
第六步:在故障恢复全过程中,若遇到了无法继续的情况或错误,比如recovery_aborted被置位或恢复所需的数据在其他节点均已被Purge或等待上线时回放出错等,则先将该节点置为ERROR状态,确认该节点复制相关线程退出了,节点向Group发送leave信息退出Group,而不是置为ERROR状态候仍留在Group中。这是跟MongoDB Replica Set等其他多节点数据库系统不一样的地方。
第七步:不管是否出错,均需要重置故障恢复相关的参数,并销毁故障恢复线程。
三、MGR故障恢复实现的不足
1、随机选择donor节点:早期的MGR版本按照节点设置group_replication_group_seeds参数中的种子节点顺序来选择donor节点,若各节点的参数配置一致,则存在同一个节点被反复选择为donor节点,会导致该节点负载过大而出现复制延迟等问题,不利Group中各节点负载的均衡。当前的MGR版本已将其调整为随机选择donor,有了很大进步,但仍可以进一步优化,就是存在多个可选的节点情况下,单主模式先排除primary节点,多主模式下排除本地负载压力最大的节点;
2、本视图事务缓存机制:MGR在节点进行全局恢复时,将本视图产生的消息缓存在认证队列中,若节点落后较多,需较长时间完成全局恢复,若Group的负载较高,会在认证队列中堆积大量的消息,这些消息位于内存中,容易出现因为内存不足而OOM。可考虑的优化方案是基于一定的策略将缓存的消息临时写到系统表中,将压力转移到磁盘上。
3、Binlog被purge处理:相比Percona基于Galera封装的Percona XtraDB Cluster(PXC),MongoDB Replica Set(ReplSet)方案,MGR目前还未提供节点全量恢复方案。即可往Group中加入一个全新的节点,由MGR来负责从其他节点拷贝全量数据(State Snapshot Transfer,SST),并通过增量复制(Incremental State transfers,IST)直至将节点置为上线状态。PXC是个解决方案套件,采用xtrabackup来实现SST,ReplSet是进程,采用逻辑拷贝的方式实现Initial Sync。MGR可参考ReplSet来实现。
4、成员类型单一:MGR目前仅提供Primary和Secondary两种成员类型,不支持Arbiter,Hidden等类型,也不支持像MongoDB和X-Cluster等其他数据库系统设置丰富的成员属性。
参考资料:
1、 http://mysqlhighavailability.com/distributed-recovery-behind-the-scenes/
2、https://mysqlhighavailability.com/improvements-and-changes-to-group-replication-recovery/
3、MySQL 5.7.20、MySQL 8.0.4源码
4、MySQL运维内参 27章MySQL Group Replication
5、https://www.percona.com/blog/2015/08/05/pxc-incremental-state-transfers-in-detail/
6、https://www.percona.com/doc/percona-xtradb-cluster/5.5/manual/state_snapshot_transfer.html
7、https://docs.mongodb.com/manual/core/replica-set-sync/#initial-sync
网易云免费体验馆,0成本体验20+款云产品!
更多网易技术、产品、运营经验分享请点击。
相关文章:
【推荐】 为什么有些验证码看起来很容易但是没人做自动识别的?
【推荐】 关于内容审核,你需要了解的东西,这里都有!











