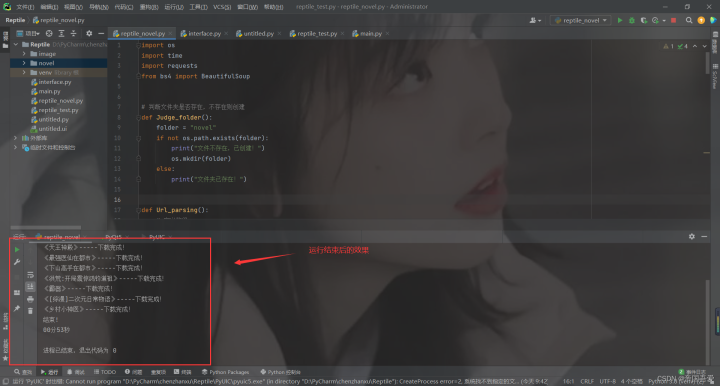
一、创建文件夹
(1)、创建指定文件夹
# 判断文件夹是否存在,不存在则创建
def Judge_folder():
folder = "novel"
if not os.path.exists(folder):
print("文件不存在,已创建!")
os.mkdir(folder)
else:
print("文件夹已存在!")
二、获取小说网址,解析需要信息
思路:进入小说书库的网址----->获取每本小说的网址----->获取每本小说下载的网址
(1)、进入小说书库的网址,解析网页,获取对应的数据信息
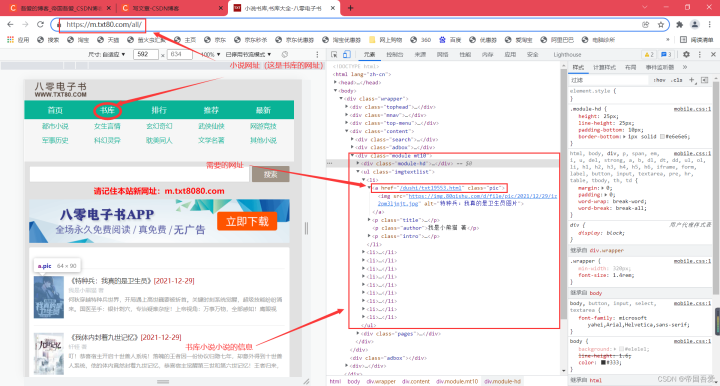
def Url_parsing():
# 定义数组
int_href = []
# 页数
for i in range(1):
str_value = str(i+1)
# url-网址https://m.txt80.com/all/index_3.html
if i + 1 > 1:
url = "https://m.txt80.com/all/index_" + str_value + ".html"
else:
url = "https://m.txt80.com/all/index.html"
# 浏览器类型-搜狗
Search_engine = {"User-Agent": "Mozilla/5.0 (compatible; Googlebot/2.1; +http://www.google.com/bot.html)"}
# 发送请求,获取网址HTML,转为text
Type_conversion = requests.get(url=url, headers=Search_engine, timeout=None).text.encode('iso-8859-1').decode(
'utf-8')
# 定义BeautifulSoup,解析网址HTML
bs = BeautifulSoup(Type_conversion, 'html.parser')
# 获取指定div
scope_div = bs.find('ul', attrs={'class': 'imgtextlist'})
if scope_div is not None:
# print(scope_div)
# 获取class为pic的a标签
scope_div_a = scope_div.findAll("a", attrs={'class': 'pic'})
# print(scope_div_a)
# 循环打印a标签
for int_i in scope_div_a:
# 获取a标签对应的数据,拼接添加到数组中
int_href.append("https://m.txt80.com/" + int_i.get("href"))
# 返回获取到小说网址的信息
return int_href
(2)、进入每本小说的页面中,解析对应的数据信息
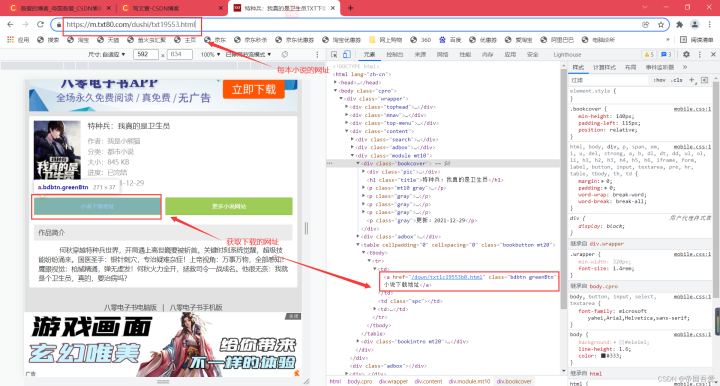
def Url_parsing1():
# https://www.txt80.com/
int_href1 = []
# 循环获取Url_parsing的值(返回每本小说的网址)
for city in Url_parsing():
url = city
# 浏览器类型-搜狗
Search_engine1 = {"User-Agent": "Mozilla/5.0 (compatible; Googlebot/2.1; +http://www.google.com/bot.html)"}
# 发送请求,获取网址HTML,转为text
Type_conversion = requests.get(url=url, headers=Search_engine1, timeout=None).text.encode('iso-8859-1').decode(
'utf-8')
# 定义BeautifulSoup,解析网址HTML
bs = BeautifulSoup(Type_conversion, 'html.parser')
# 获取指定div
scope_div = bs.find('a', attrs={'class': 'bdbtn greenBtn'})
# print(scope_div.get("href"))
# 获取指定div中的所有a标签
int_href1.append("https://m.txt80.com/" + scope_div.get("href"))
# 返回int_href1数组
return int_href1
(3)、进入每本小说的下载页面,解析对应的数据信息
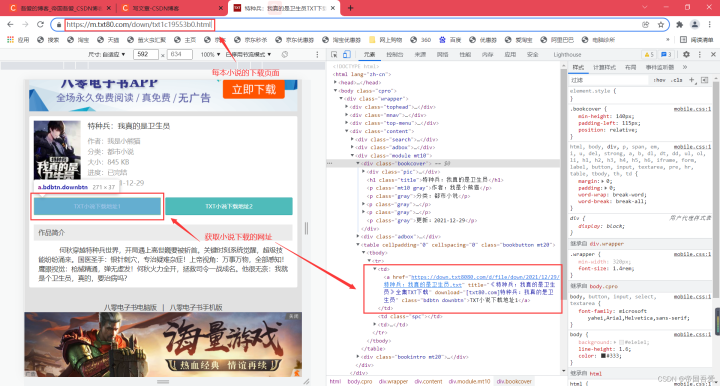
def Url_parsing2():
for city in Url_parsing1():
url = city
# 浏览器类型-搜狗
Search_engine = {"User-Agent": "Mozilla/5.0 (compatible; Googlebot/2.1; +http://www.google.com/bot.html)"}
# 发送请求,获取网址HTML,转为text
Type_conversion = requests.get(url=url, headers=Search_engine, timeout=None).text.encode("utf-8").decode("utf-8")
# 定义BeautifulSoup,解析网址HTML
bs = BeautifulSoup(Type_conversion, 'html.parser')
# 获取指定div
scope_div = bs.find('a', attrs={'class': 'bdbtn downbtn'})
# print(scope_div)
requests_href = scope_div.get("href")
requests_title = scope_div.get("title")[0:-7]
# print(requests_href, requests_title)
三、下载小说
(1)、循环下载小说
# 定义要下载的内容
download = requests.get(requests_href)
# 循环打开文件创建jpg
with open("novel/" + requests_title + ".txt", mode="wb") as f:
f.write(download.content)
print(requests_title + "-----下载完成!")
四、附上完整代码
import os
import time
import requests
from bs4 import BeautifulSoup
# 判断文件夹是否存在,不存在则创建
def Judge_folder():
folder = "novel"
if not os.path.exists(folder):
print("文件不存在,已创建!")
os.mkdir(folder)
else:
print("文件夹已存在!")
def Url_parsing():
# 定义数组
int_href = []
# 页数
for i in range(1):
str_value = str(i+1)
# url-网址https://m.txt80.com/all/index_3.html
if i + 1 > 1:
url = "https://m.txt80.com/all/index_" + str_value + ".html"
else:
url = "https://m.txt80.com/all/index.html"
# 浏览器类型-搜狗
Search_engine = {"User-Agent": "Mozilla/5.0 (compatible; Googlebot/2.1; +http://www.google.com/bot.html)"}
# 发送请求,获取网址HTML,转为text
Type_conversion = requests.get(url=url, headers=Search_engine, timeout=None).text.encode('iso-8859-1').decode(
'utf-8')
# 定义BeautifulSoup,解析网址HTML
bs = BeautifulSoup(Type_conversion, 'html.parser')
# 获取指定div
scope_div = bs.find('ul', attrs={'class': 'imgtextlist'})
if scope_div is not None:
# print(scope_div)
# 获取class为pic的a标签
scope_div_a = scope_div.findAll("a", attrs={'class': 'pic'})
# print(scope_div_a)
# 循环打印a标签
for int_i in scope_div_a:
# 获取a标签对应的数据,拼接添加到数组中
int_href.append("https://m.txt80.com/" + int_i.get("href"))
# 返回获取到小说网址的信息
return int_href
def Url_parsing1():
# https://www.txt80.com/
int_href1 = []
# 循环获取Url_parsing的值(返回每本小说的网址)
for city in Url_parsing():
url = city
# 浏览器类型-搜狗
Search_engine1 = {"User-Agent": "Mozilla/5.0 (compatible; Googlebot/2.1; +http://www.google.com/bot.html)"}
# 发送请求,获取网址HTML,转为text
Type_conversion = requests.get(url=url, headers=Search_engine1, timeout=None).text.encode('iso-8859-1').decode(
'utf-8')
# 定义BeautifulSoup,解析网址HTML
bs = BeautifulSoup(Type_conversion, 'html.parser')
# 获取指定div
scope_div = bs.find('a', attrs={'class': 'bdbtn greenBtn'})
# print(scope_div.get("href"))
# 获取指定div中的所有a标签
int_href1.append("https://m.txt80.com/" + scope_div.get("href"))
# 返回int_href1数组
return int_href1
def Url_parsing2():
for city in Url_parsing1():
url = city
# 浏览器类型-搜狗
Search_engine = {"User-Agent": "Mozilla/5.0 (compatible; Googlebot/2.1; +http://www.google.com/bot.html)"}
# 发送请求,获取网址HTML,转为text
Type_conversion = requests.get(url=url, headers=Search_engine, timeout=None).text.encode("utf-8").decode("utf-8")
# 定义BeautifulSoup,解析网址HTML
bs = BeautifulSoup(Type_conversion, 'html.parser')
# 获取指定div
scope_div = bs.find('a', attrs={'class': 'bdbtn downbtn'})
# print(scope_div)
requests_href = scope_div.get("href")
requests_title = scope_div.get("title")[0:-7]
# print(requests_href, requests_title)
# 定义要下载的内容
download = requests.get(requests_href)
# 循环打开文件创建jpg
with open("novel/" + requests_title + ".txt", mode="wb") as f:
f.write(download.content)
print(requests_title + "-----下载完成!")
def Exception_error():
Judge_folder()
try:
Url_parsing2()
except KeyboardInterrupt:
print('\n程序已终止. . . . .')
print('结束!')
def Time():
# 记录程序开始运行时间
start_time = time.time()
s = 0
Exception_error()
# 记录程序结束运行时间
end_time = time.time()
ts = end_time - start_time
dt = time.strftime("%M分%S秒", time.localtime(ts))
print(dt)
return s
def Start():
Time()
if __name__ == '__main__':
Start()