(一)前言
刚学完二分查找法,虽然该方法很简单,但是还是很有很多坑值得记录一下。
(二)方法介绍
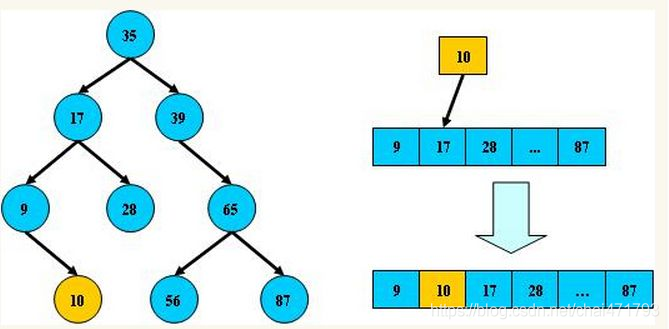
二分查找法的时间复杂度为对数阶,所以他相对于顺序查找法来说效率较高。
(三)代码分析
这里我决定分块阐述,不直接把代码端上来了。应为我们知道,这里可能会有两种情况,一种是我们只查询单个数的索引,它没有重复的数据;另一种则是数组中有重复数据的出现。
(1)单个数据,返回值为int类型的索引
1)main方法准备
这里我们使用了基数排序法(也是对昨天所学的一个复习)对数组排了序,所以最后返回的是排好序的索引结果。
public static void main(String[] args) {
int[] arr = { 1, 2, 5, 4, 3, 15, 22 };
BucketSort(arr);
System.out.println(Arrays.toString(arr));
ArrayList<Integer> result = binarySearch02(arr, 0, 8, 3);
System.out.println(result);
}2)基数排序法
此方法可以见我上一篇文章的详解,这里不再赘述。
/**
* 基数排序法
*
* @param arr
*/
private static void BucketSort(int[] arr) {
int[][] bucket = new int[10][arr.length];
int[] bucketCounts = new int[10];
int max = arr[0];
for (int i = 1; i < arr.length; ++i) {
if (arr[i] > max) {
max = arr[i];
}
}
int maxLength = (max + "").length();
for (int i = 0, n = 1; i < maxLength; ++i, n *= 10) {
for (int j = 0; j < arr.length; ++j) {
int digitofElement = arr[j] / n % 10;
bucket[digitofElement][bucketCounts[digitofElement]] = arr[j];
bucketCounts[digitofElement]++;
}
int index = 0;
for (int k = 0; k < bucket.length; ++k) {
if (bucketCounts[k] != 0) {
for (int l = 0; l < bucketCounts[k]; ++l) {
arr[index] = bucket[k][l];
index++;
}
}
bucketCounts[k] = 0;
}
}
}3)二分查找核心算法
这里采用了递归而没有使用循环,一方面是对自己递归的一个锻炼,另一个方面递归的效率优于循环。
private static int binarySearch(int[] arr, int left, int right, int value) {
if (left > right) {
return -1;
}
int mid = (left + right) / 2;
if (value > arr[mid]) {
return binarySearch(arr, mid + 1, right, value);
} else if (value < arr[mid]) {
return binarySearch(arr, left, mid - 1, value);
} else {
return mid;
}
}- 首先,我们需要给方法传参(arr数组,left为左索引,right为右索引,value为索引值),记住:递归的一个十分十分关键的一点,就是退出条件,如果没有退出条件,他会进入死循环,出现StackOverflowError错误。
- 这里我们判断递归出去的条件是要么找到此数,要么没找到。如果没找到,那么最后跳出条件一定是 left > right。但如果找到那么最后跳出的就是mid参数。
- 如果不再跳出之列,那么最后进入二级判断:是往左找还是往右找的问题,所以有了这几个if-else判断。
注意:这里也是我在敲代码的时候领悟的一点:使用递归时,如果函数有返回值,那么递归递归调用也必须 return!!!这有这样,在最底层return回来的数据才能被return给调用者。
(2)多个数据返回,返回类型为集合
这里的1)、2)跟前面相差不大,主要是对查找算法的改变。
3)二分查找核心算法
private static ArrayList<Integer> binarySearch02(int[] arr, int left, int right, int value) {
if (left > right) {
return new ArrayList<Integer>();
}
int mid = (left + right) / 2;
if (value > arr[mid]) {
return binarySearch02(arr, mid + 1, right, value);
} else if (value < arr[mid]) {
return binarySearch02(arr, left, mid - 1, value);
} else {
ArrayList<Integer> list = new ArrayList<>();
int tmp = mid - 1;
while (true) {
if (tmp < 0 || arr[tmp] != value) {
break;
}
list.add(tmp);
tmp--;
}
list.add(mid);
tmp = mid + 1;
while (true) {
if (tmp > arr.length || arr[tmp] != value) {
break;
}
list.add(tmp);
tmp++;
}
return list;
}
}改变之处:
- 返回值:现在返回一个
ArrayList集合,里面放索引 - 递归结束返回值:空集合
- 最后返回mid位置的数的改进:因为如果找到,那么可能该数左右都有,所以这里用两个while循环将其收入。最后递归返回(本文关键,提高对递归的理解)。