
1 背景
最近在做需求的时候需要在一张表中增加一个字段。
这张表情况如下:
1、拆分了多个库多张表
2、库表拆分按表中商户编码字段hash之后取模进行拆分
由于库表拆分按照商户编码,有些大商家的单子数量远远要高于其他普通商家,这样就造成了严重的数据倾斜。
在增加字段的时候尝试多种办法,执行多次都添加失败。
虽然通过一些特殊手段还是可以将字段加上的,
但是如果这张表中的数据一直持续下去,导致的结果可能是这张表越来越难以扩展,并且随着数据量的增加还对未来造成一定的隐患。
所以决定对此表再次进行拆分,这时让我想起多年前看的一本书《架构真经》在第二章中介绍分而治之的方法论,其中AKF模型很实用,对我的启发很大。
接下来就简单介绍下。
关于《架构真经》的介绍:本书全面概括了互联网技术架构的理念、设计、实施和监控方面的相关场景、条件和方法,是一本有关设计和构建可扩展性系统的深入且实用的指南。作者马丁·阿伯特和迈克·费舍尔已经为数以百计高速增长公司的上千个不同系统提供了帮助,凭借着多年积累的实战经验,提炼出50条互联网技术架构原则,可以支持几乎任何高速增长公司的扩展。
2 理论模型介绍
关于AKF简介
AKF是以AKF公司的合作伙伴的名字(AKF Partner)命名的,AKF扩展立方体主要围绕系统扩展为主题进行介绍。提出了X、Y、Z三种扩展方向。通过不同方向的扩展来达到接近无限扩展的目的。
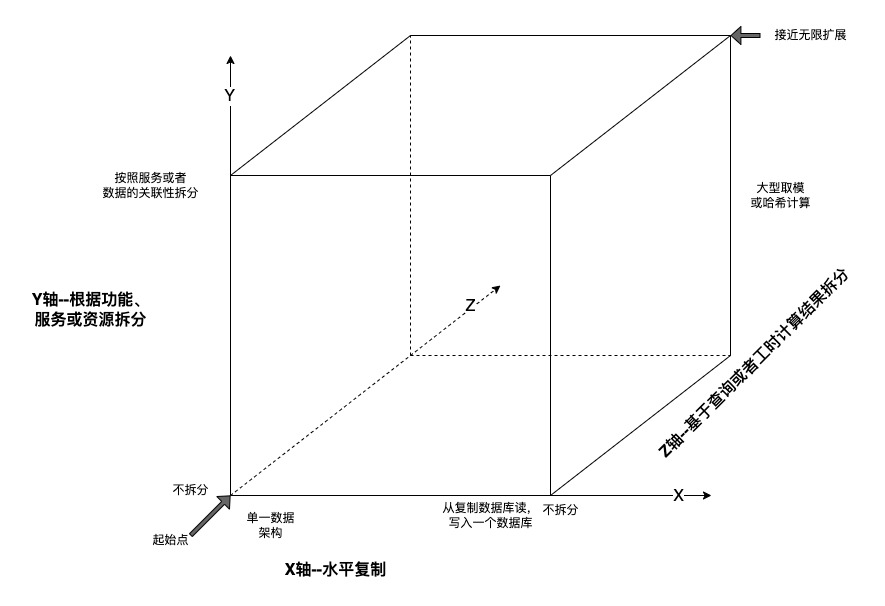
X轴是水平扩展,通俗说就是复制多份数据或服务
Y轴是针对动词(服务)或名词(资源)的拆分,或者说就是业务上的拆分
Z轴是根据实际情况对客户独特属性进行拆分(ID,名称,地理位置等)
X,Y,Z轴分别代表了不同的扩展方向,下面简单解释一下:
X轴代表无差别的克隆服务和数据库。实际场景中我们的应用服务,以及数据库数据的副本理论上是可以无限扩展的。在每个克隆实体间无差别的分配任务,每个克隆实体都可以完成其他克隆实体的任务,无论任务分配给了谁。比如应用服务复制部署了多份,通过负载均衡分发请求,每个应用都可以处理其他应用的请求。
X轴优点:成本低,操作与应用简单
X轴缺点:X轴无差别的处理请求,要求请求之间尽量不要有依赖关系,或者中间状态。数据集过大依然是风险,同时随着系统变大业务变多指令集耦合也会变得很多。
Y轴代表的是按照交易处理的数据类型、交易任务的类型或两者组合分割的工作责任。我们一般用动词或资源进行分离,比如:登录,查询,结算等等。把同样的工作分割成流水线式的工作流或并行的处理流,Y轴代表的更多是对工作的“工业革命”,将耦合紧密的工作进行进行专门处理。Y轴实质代表责任、行动或数据。实施成本一般比X轴扩展代价高。假如有100个人分别造100辆车,每个人负责造一辆,完成造车全部的任务,不如让100个人执行子任务,如发动机的安装、喷漆、四轮定位。这样就会减少前后交互所需要的上下文信息,更专注做某件事情。内聚性更高,耦合性更低。Y轴主要解决指令集的扩展性。
Y轴优点:可以解决指令集与数据集的约束与耦合,充分体现分而治之的思想,代码简单,故障隔离等。
Y轴缺点:成本相对较高,系统庞大,业务复杂
Z轴通常基于请求或客户的信息进行分割。比如我们在拆分客户时会有 “普通会员”和“vip会员“之分,服务“普通会员”与服务“vip会员”可能会有不同。vip会员可能会有更多的服务项目,会有单独的人在处理vip会员的事情。但是他们都是会员。再比如一些客户可能需要专门的账单、付款条件和基于业务量的特别互动。我们可能安排最好的财务代表、甚至特别的经理负责一个或多个客户,以专门处理他们的独特需求。Z轴主要解决数据集的扩展性。
Z轴分割是成本最高的分割方向,Z轴分割有助于提高交易和数据的可扩展性,如果实施得当也有助于扩展指令集和过程
Z轴优点:解决单一数据集过大问题,可以应对数据指数增长。
Z轴缺点:成本最高,很难解决指令集问题。
3 理论实践
通过上面的理论介绍,接下来指导我们对实际业务场景的拆分。
针对文章开头提到的某些大商户单子远远多余其他商户的情况,很显然这是数据集的扩展性导致的问题。
更应该在Z轴上进行扩展拆分,也就是通过商户的特殊性,进行再次拆分来平衡数据。
这里的特殊性可以是表中字段的某一个属性,比如订单编号、创建时间等等。这就需要我们根据实际情况,既要拆分的均匀又要拆分之后能满足未来几年的发展,同时还要满足现有业务的支持。
4 总结
通过对AKF模型的学习我们在工作实践中如果遇到类似的情况可以按照这个模型进行对系统拆分。当然我们也不要过度使用。不同的业务或者场景可能使用其中一个就足够用了,但是又有其他一些场景,已经按照XYZ轴拆分过一次了但是不够满足需求,可以再次在三个轴之一再次进行拆分,已达到满足业务需要的目的。
XYZ三个轴的扩展方向每个都有优缺点,要准确识别场景进行使用,或结合使用互补优缺点。
作者:京东保险 张永刚
来源:京东云开发者社区 转载请注明来源




