一、导言
合约保量广告(Guaranteed Delivery)是一种常见的品牌展示广告采买方式,现有的技术解决方案通常是在人群粒度上对问题进行抽象和建模,这种建模方式一方面忽略了相同人群下用户行为的差异,另一方面无法对用户粒度的约束进行精确的控制。
目前学术界关于合约广告流量分配问题的研究,通常会将这个问题抽象为合约侧-供给侧的二部图匹配问题,但目前的分配策略是停留在人群和标签粒度上,这要求人群和标签的划分必须是正交化的;除此之外,在人群层次上进行合约保量分配也还有不少局限性。
首先,由于只在人群层面进行分配,无法通过精准的用户行为预测将用户的个性化行为匹配至正确的广告,会降低广告主的投资回报率,进一步的降低广告平台的未来收入。其次,广告主通常会提出复杂的投放控制要求,比如在用户粒度的频次控制约束,一个典型的做法是,为了能够提高固定预算下的uv触达,广告主往往会限制单个uv的曝光频次。因此,传统的人群标签粒度分配的低效性使得其很难适用于目前的合约广告投放产品。
在本文中,我们尝试建立一个大规模分布式的合约广告投放分配算法,并在其中引入用户个性化的投放指标,在考虑用户交互行为的基础上,在用户粒度进行合约广告的投放分配工作。我们的算法可以处理复杂的约束,例如广告优先级,广告的展示频控以及广告贴位容量限制等。在这个基础上,我们还开发了实时预算平滑策略,通过预算平滑控制进一步优化广告的投放效果(如单位点击成本CPC)。目前我们的系统在阿里妈妈品牌展示广告实际承载了十亿规模的离线计算任务并在线应用,我们也将在最后给出离线和在线的实验结果来验证方案的的准确性。
二、问题定义

这是一个经典的online assignment的问题,在数据规模较小且全局信息已知的情况下,使用匈牙利算法、网络流算法和混合整数规划方法都可以获得理想的最优解。但是对于互联网广告投放系统而言,数据规模很大,而且由于性能要求,对于一个请求,不可能也没办法确定全局信息。






以上就是对问题的定义和描述,众所周知淘系用户日均DAU的规模是亿级别以上,而广告每天也成百上千的规模,在这样一个大规模求解的背景下,难点在于如何对这个问题进行求解并保持提供高并发、低延迟的广告服务。为此我们在离线阶段对这个问题进行了大规模的分布式求解,而在线阶段为了能够适配流量的变化情况,我们开发了独立的pacing模块来进行流量的平滑控制。
三、系统实现
3.1 系统描述

上图是我们系统的整体架构图和整体的数据流程,主要包括面向广告主订单签订的CRM管理系统,离线算法和在线引擎部分。广告主作为管理平台和广告主之间的桥梁,主要用于订单信息的制定,包括人群圈选,流量询量,在线合约签单,创意信息绑定等。离线的处理框架将会同步这些合约信息,并与获取的离线日志一起,通过基于PS架构的分配优化模型进行离线分布式算法求解,将计算结果导入到Model中并同步至在线系统。最后当实时请求到来时,Merger作为在线的引擎,将请求RTP服务,pacing服务,和分配模型服务,经过离线的分配算法模型,得到最终投放的广告并返回给前端客户端展示。
3.2 离线优化
离线的部分算法分为2个阶段,第一个阶段我们将原问题转化为其对偶形式,通过并行化求解得到问题的对偶变量。第二阶段,由于现实投放优先级的影响,我们通过离线拓扑排序的方式,给出并行加速的方案,从而使得大规模数据集上的求解效率大幅度提升。
3.2.1 阶段一分布式求解

对于我们的问题而言,用户的的量级远远大于合约的数量,所以求解合约侧对偶的的计算代价会远远大于供给侧。我们通过分布式计算的方式进行水平扩展,将供给侧对偶变量的计算分布在ps的worker节点上。而对于供给侧来说,其更新的过程放在server上,woker通过pull的方式获取最新的对偶变量。观察合约侧的对偶变量约束,我们发现其等式求解规模和广告主人群的规模是一致的,这个计算量对于通常的计算而言往往过于巨大,因此我们采用一种近似的方法来计算和更新这个对偶变量。注意到在更新的过程中,这个变量是一个保持单调递增的过程,相邻两轮的迭代满足这样一个不等式:


上述伪代码是我们更新对偶变量的算法描述,而关于供给侧对偶变量的求解,我们很容易注意到一个结论:
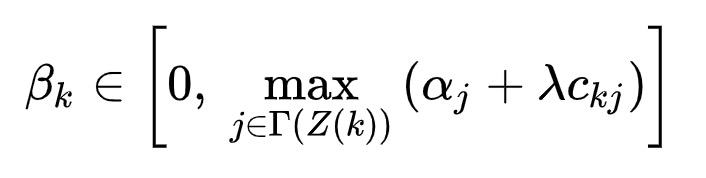 .png")
.png")
而且关于这个方程的目标是单调的,因此可以通过二分求解的方式得到结果,具体过程我们在这里不进一步描述。
3.2.2 阶段二并行优先级加速


注意到原始的计算过程中 是单独顺序计算的,在数据规模较小的情况下,这个计算量尚可接受,但是当合约数量达到一定规模后,比如上万的规模,计算效率明显比较低下。而之前的性质告诉我们,对于任意2个正交的人群,他们的计算过程并没有优先级的重叠,因此是可以并行计算的。举个简单的例子,对于定向北京和上海的2个用户群来说,即便优先级存在不同,但是由于互相没有重叠,一个对偶的占量并不会影响另一个定向的库存,这样2个任务是完全可以并行计算的。
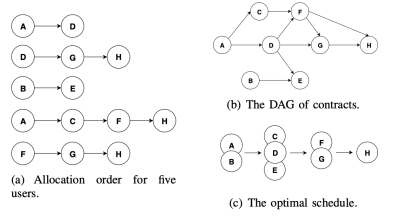
在这个前提下,我们在离线构建二分图的时候,由于保存了每个用户的合约广告挂载情况,从而可以得到每个用户的实际订单的优先顺序,如上图所示,根据原始的订单分配顺序,进一步可以得到所有订单的DAG大图。最后很容易通过拓扑排序的方式得到我们优化后的并行化执行序列。接着拿上图进行举例,原始的更新顺序是[A] → [H], 通过DAG图的构建以及最终拓扑排序的结果,我们最终得到[A, B] → [C, D, E] → [F, G] → [H]这样只有4个需要处理的批次,相比于原先8个批次的执行,效率可以提升近一倍左右,而在实际的实验中,这个优化的效率提升会更加明显。

3.3 在线pacing
之前的大多数展示投放,尤其是合约保量这里,许多系统采用了轮盘赌的方法或者是贪心算法来进行在线投放。由于在投放之前,我们模型的对偶变量已经确定,对于未来的投放概率往往是不可改变的,这样会带来一个问题,投放的结果将严重依赖于流量预估的结果,这会导致线上缺量或者超投的情况发生。为了能够及时的适应流量分布的变化,我们在合约投放之后增加一个pacing的调控模块。我们注意到相比于天级别的流量波动,分钟级别的波动往往比较小,因此我们可以在分钟级这个level上,进行实时的调控。



区别于之前合约保量的HWM算法和SHALE算法,我们改进了线上的投放方式,原有的轮盘赌方式本质上在效果层面随机选择广告,对于展示效果而言会有信息损失。如果直接贪心选择效果最好的投放,在线上由于分配占量的问题,会有投放缺量风险,通过将pacing和XSHALE这两种方式结合在一起,引入实时的pacing调控,使得我们的方法可以更好适应线上流量的变化。
四、实验结果
我们在淘宝的数据集上进行离线的验证,这些数据收集于手淘banner和猜你喜欢的合约广告。在离线阶段我们会验证求解对偶变量的正确性和高效性,同时用实际的线上A/B测试来验证我们离线模型和在线pacing服务的正确性。
4.1 离线实验
我们和GD的经典算法HWM算法和SHALE算法进行比较,除了求解时间外,算法指标方面我们从投放完成率,惩罚项,L2-Norm和平均点击成本这四个指标来评测。四个指标的定义分别如下所示:


离线指标评测如下表和下图所示,在各种情况下与其他方法相比,我们的系统都能将CPC降低近50%。虽然我们在完成率,惩罚项和L2-Norm中有一些收益的损失,但与CPC降低幅度相比,我们可以接受这些损失。时间性能方面,HWM是最快的,因为它仅运行一次迭代。
但是,与SHALE和我们的方法相比,HWM的投放性能相对较差,线上不具备使用的可能。由于我们考虑了多目标的分配, SHALE在完成率方面略胜于我们的方法。但是我们的方法在改进投放指标方面有显著的的提升。如之前所述,广告分配问题的一个瓶颈是求解对偶变量α和β的时间。我们采用了并行化的方案以及基于DAG中拓扑排序的加速调度方式,可以更加快速的计算对偶变量α和β,这种加速比在大数据上的优势会更加的明显。


进一步分析发现,通过DAG中拓扑排序的加速调度方式,可以大幅度的提升求解性能。我们在真实的7天日常任务上进行测试,用OriginBatch来表示不经DAG加速的迭代轮数,用Reduce Batch来描述加速后的迭代轮数,可以很明显的看到,相比串行的方式,使用DAG的任务可以有效地将计算速度提高14倍左右。

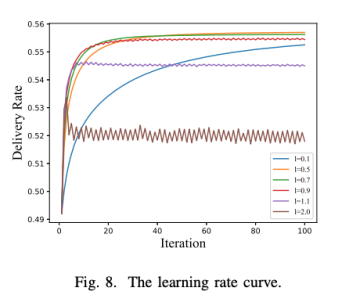
我们给出了超参learning rate的调参比较,可以很明显的看到,在learning rate取值较小时,其收敛速度是较慢的,当取值逐渐增大,其收敛速度会显著上升,而当learning rate过大时会在最优解周围出现震荡,极端情况l=2.0时,和最优解的距离相差非常之大,就我们的系统而言,我们通常将learning rate设置在0.5到0.7之间。
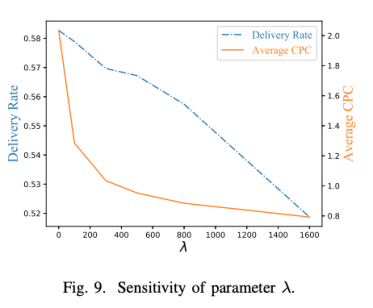
最后我们测试了超参λ对投放完成率和平均每次点击费用的影响。 可以看到平均CPC随λ的增加而单调下降,也就是说如果想获得更大的平台收益,增大λ似乎是一个不错的选择,但是当λ特别大时,不仅造成了完成率的下降,点击成本也并不会进一步的下降,这样会导致缺量的发生,因此我们一般会控制完成率的损失在一定的范围内,如在1%-3%之间。
4.2 在线实验
我们在手淘场景中对我们的方案进行了真实的线上测试,我们用线上的真实点击率来评估我们的投放指标。实际在线A/B实验中,采用预算分桶的测试机制来保障各个实验是在相同的预算下进行的。我们和基于贪心投放的基准算法以及传统SHALE算法进行了对比。而为了能够验证平滑pacing的作用,我们增加了SHALE-CLICK算法,即考虑点击效果,但不考虑pacing,采用轮盘赌方式进行投放。
从图a的曲线上看,使用我们的策略得到的投放曲线最为平滑,基于贪心的基准算法在开始就花费了一半以上的预算。接下来表现不错的是SHALE算法和SHALE-CLICK算法,通过轮盘赌的方式一定程度上进行了平滑的控制,但是由于线上流量分布的变化与离线并不完全一致,导致效果并不是最优的结果。

图b给出了不同算法分桶下的实时累计平均点击率,可以看到考虑点击建模的SHALE-Click算法的表现优于贪心基准算法和SHALE算法。贪心算法由于投放过快,导致其流量优选的空间受到了限制,其表现最差。在pacing算法的平滑下,我们的算法表现最佳,在刚开始投放的过程中就显示出比较明显的优势。如图c所示,实验结果显示我们的方法在点击率方面相比baseline提升22.7%,相比SHALE提升21.2%,相比SHALE-CLICK提升10.6%。实验充分表明了我们算法的有效性。
五、总结
通过将用户的和广告的交互指标纳入到分配的目标中去,通过设计离线分布式算法和在线的实时调控算法,可以大幅度的提高合约保量广告的投放效率和合约完成情况。在线的分桶实验进一步表明我们的算法可以在为合约广告平台提供更多收益的同时提升广告主的品牌营销效果。以上工作被 ICDM'19 以长文录用,请参见《Large-Scale Personalized Delivery for Guaranteed Display Advertising with Real-Time Pacing》
本文作者:檸,铮
本文来自阿里云合作伙伴“阿里技术”,如需转载请联系原作者。










