Kotlin 高级函数的特性不仅让代码可读性更强,更加简洁,而且还提高了生产效率,但是简洁的背后是有代价的,隐藏着不能被忽视的成本,特别是在低端机上,这种成本会被放大,因此我们需要去研究 kotlin 语法糖背后的魔法,选择合适的语法糖,尽量避免这些坑。
Lambda 表达式
Lambda 表达式语法简洁,避免了冗长的函数声明,代码如下。
fun requestData(type: Int, call: (code: Int, type: Int) -> Unit) {
call(200, type)
}Lambda 表达式语法虽然简洁,但是隐藏着两个性能问题。
- 每次调用 Lambda 表达式,都会创建一个对象
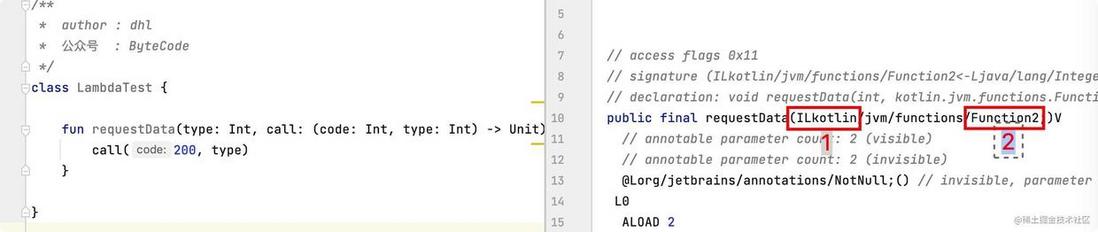
图中标记 1 所示的地方,涉及一个字节码类型的知识点。
| 标识符 | 含义 |
|---|---|
| I | 基本类型 int |
| L | 对象类型,以分号结尾,如 Lkotlin/jvm/functions/Function2; |
Lambda 表达式 call: (code: Int, type: Int) -> Unit 作为函数参数,传递到函数中,Lambda 表达式会继承 kotlin/jvm/functions/Function2 , 每次调用都会创建一个 Function2 对象,如图中标记 2 所示的地方。
- Lambda 表达式隐含自动装箱和拆箱过程

正如你所见 lambda 表达式存在装箱和拆箱的开销,会将 int 转成 Integer,之后进行一系列操作,最后会将 Integer 转成 int。
如果想要避免 Lambda 表达式函数对象的创建及装箱拆箱开销,可以使用 inline 内联函数,直接执行 lambda 表达式函数体。
Inline 修饰符
Inline 内联函数的作用:提升运行效率,调用被 inline 修饰符标记的函数,会把函数内的代码放到调用的地方。
如果阅读过 Koin 源码的朋友,应该会发现 inline 都是和 lambda 表达式和 reified 修饰符配套在一起使用的,如果只使用 inline 修饰符标记普通函数,Android Studio 也会给一个大大大的警告。

编译器建议我们在含有 lambda 表达式作为形参的函数中使用内联,既然 Inline 修饰符可以提升运行效率,为什么编译器会给我们一个警告? 这是为了防止 inline 操作符滥用而带来的性能损失。
inline 修饰符适用于以下情况
- inline 修饰符适用于把函数作为另一个函数的参数,例如高阶函数 filter、map、joinToString 或者一些独立的函数 repeat
- inline 操作符适合和 reified 操作符结合在一起使用
- 如果函数体很短,使用 inline 操作符可以提高效率
Kotlin 遍历数组
这一小节主要介绍 Kotlin 数组,一起来看一下遍历数组都有几种方式。
- 通过
forEach遍历数组 - 通过区间表达式遍历数组(
..、downTo、until) - 通过
indices遍历数组 - 通过
withIndex遍历数组
通过 forEach 遍历数组
先来看看通过 forEach 遍历数组,和其他的遍历数组的方式,有什么不同。
array.forEach { value ->
}
反编译后:
Integer[] var5 = array;
int var6 = array.length;
for(int var7 = 0; var7 < var6; ++var7) {
Object element$iv = var5[var7];
int value = ((Number)element$iv).intValue();
boolean var10 = false;
}正如你所见通过 forEach 遍历数组的方式,会创建额外的对象,并且存在装箱/拆箱开销,会占用更多的内存。
通过区间表达式遍历数组
在 Kotlin 中区间表达式有三种 .. 、 downTo 、 until
- 用
..关键字,表示左闭右闭区间 - 用
downTo关键字,实现降序循环 - 用
until关键字,表示左闭右开区间
.. 、downTo 、until
for (value in 0..size - 1) {
// case 1
}
for (value in size downTo 0) {
// case 2
}
for (value in 0 until size) {
// case 3
}
反编译后
// case 1
if (value <= var4) {
while(value != var4) {
++value;
}
}
// case 2
for(boolean var5 = false; value >= 0; --value) {
}
// case 3
for(var4 = size; value < var4; ++value) {
}如上所示 区间表达式 ( .. 、 downTo 、 until) 除了创建一些临时变量之外,不会创建额外的对象,但是区间表达式 和 step 关键字结合起来一起使用,就会存在内存问题。
区间表达式 和 step 关键字
带 step 操作的 .. 、 downTo 、 until, 编译之后如下所示。
for (value in 0..size - 1 step 2) {
// case 1
}
for (value in 0 downTo size step 2) {
// case 2
}
反编译后:
// case 1
var10000 = RangesKt.step((IntProgression)(new IntRange(var6, size - 1)), 2);
while(value != var4) {
value += var5;
}
// case 2
var10000 = RangesKt.step(RangesKt.downTo(0, size), 2);
while(value != var4) {
value += var5;
}带 step 操作的 .. 、 downTo 、 until 除了创建一些临时变量之外,还会创建 IntRange 、 IntProgression 对象,会占用更多的内存。
通过 indices 遍历数组
indices 通过索引的方式遍历数组,每次遍历的时候通过索引获取数组里面的元素,如下所示。
for (index in array.indices) {
}
反编译后:
for(int var4 = array.length; var3 < var4; ++var3) {
}通过 indices 遍历数组, 编译之后的代码 ,除了创建了一些临时变量,并没有创建额外的对象。
通过 withIndex 遍历数组
withIndex 和 indices 遍历数组的方式相似,通过 withIndex 遍历数组,不仅可以获取的数组索引,同时还可以获取到每一个元素。
for ((index, value) in array.withIndex()) {
}
反编译后:
Integer[] var5 = array;
int var6 = array.length;
for(int var3 = 0; var3 < var6; ++var3) {
int value = var5[var3];
}正如你所看到的,通过 withIndex 方式遍历数组,虽然不会创建额外的对象,但是存在装箱/拆箱的开销
总结:
- 通过
forEach遍历数组的方式,会创建额外的对象,占用内存,并且存在装箱 / 拆箱开销 - 通过
indices和区间表达式 (..、downTo、until) 都不会创建额外的对象 - 区间表达式 和
step关键字结合一起使用, 会有创建额外的对象的开销,占用更多的内存 - 通过
withIndex方式遍历数组,不会创建额外的对象,但是存在装箱/拆箱的开销
尽量少使用 toLowerCase 和 toUpperCase 方法
这一小节内容,在我之前的文章中分享过,但是这也是很多小伙伴,遇到最多的问题,所以单独拿出来在分析一次
当我们比较两个字符串,需要忽略大小写的时候,通常的写法是调用 toLowerCase() 方法或者 toUpperCase() 方法转换成大写或者小写,然后在进行比较,但是这样的话有一个不好的地方,每次调用 toLowerCase() 方法或者 toUpperCase() 方法会创建一个新的字符串,然后在进行比较。
调用 toLowerCase() 方法
fun main(args: Array<String>) {
// use toLowerCase()
val oldName = "Hi dHL"
val newName = "hi Dhl"
val result = oldName.toLowerCase() == newName.toLowerCase()
// or use toUpperCase()
// val result = oldName.toUpperCase() == newName.toUpperCase()
}toLowerCase() 编译之后的 Java 代码

如上图所示首先会生成一个新的字符串,然后在进行字符串比较,那么 toUpperCase() 方法也是一样的如下图所示。
toUpperCase() 编译之后的 Java 代码

这里有一个更好的解决方案,使用 equals 方法来比较两个字符串,添加可选参数 ignoreCase 来忽略大小写,这样就不需要分配任何新的字符串来进行比较了。
fun main(args: Array<String>) {
val oldName = "hi DHL"
val newName = "hi dhl"
val result = oldName.equals(newName, ignoreCase = true)
}equals 编译之后的 Java 代码

使用 equals 方法并没有创建额外的对象,如果遇到需要比较字符串的时候,可以使用这种方法,减少额外的对象创建。
by lazy
by lazy 作用是懒加载,保证首次访问的时候才初始化 lambda 表达式中的代码, by lazy 有三种模式。
LazyThreadSafetyMode.NONE仅仅在单线程LazyThreadSafetyMode.SYNCHRONIZED在多线程中使用LazyThreadSafetyMode.PUBLICATION不常用
LazyThreadSafetyMode.SYNCHRONIZED 是默认的模式,多线程中使用,可以保证线程安全,但是会有 double check + lock 性能开销,代码如下图所示。
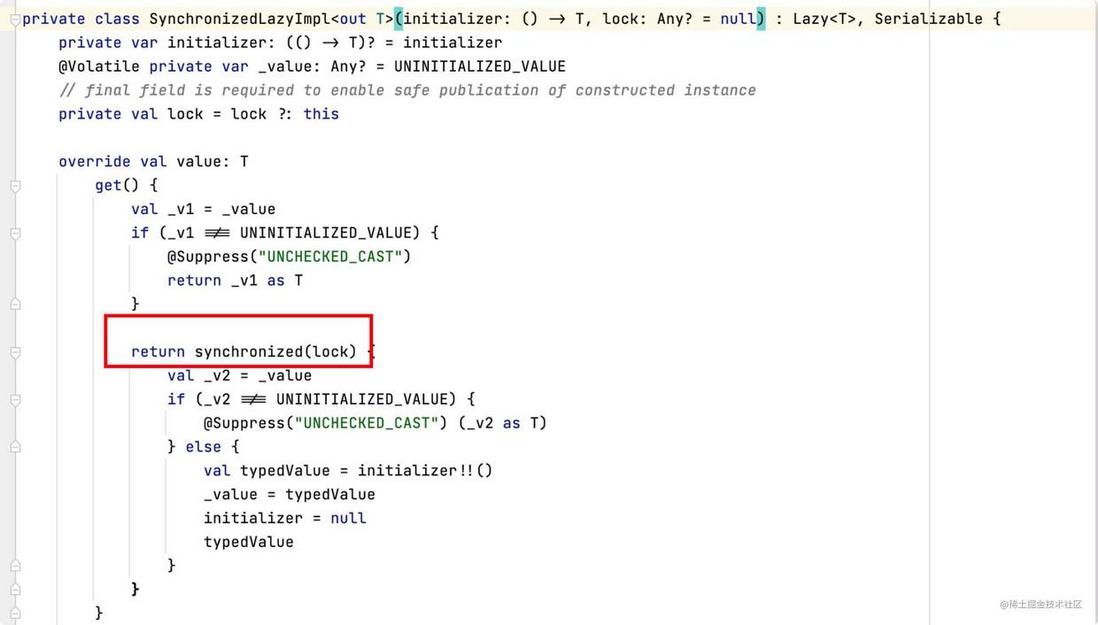
如果是在主线程中使用,和初始化相关的逻辑,建议使用 LazyThreadSafetyMode.NONE 模式,减少不必要的开销。
学习资源推荐👉
《Kotlin 入门教程指南》,篇幅有限,下方有免费领取方式!
这份完整版的《Kotlin 入门教程指南》PDF版电子书,点这里可以看到全部内容。或者点击 【这里】 查看获取方式。














