
2023 新年伊始,OpenMLDB v0.7.0 正式发布。本次版本更新重点增强了易用性和稳定性,下文将详细介绍主要改进和更新内容。更多 0.7.0 版本内容详见链接:Release v0.7.0 · 4paradigm/OpenMLDB
系统性改进消息和错误码,提升易用性
在以前的版本中,消息和错误码系统的完善度不足,存在错误信息未被正确捕获、消息显示模糊等问题。v0.7.0 开始重构整个消息和错误码系统,目前主要改进了 CLI 和 SDK 上的大部分消息和错误码,其余将在后续版本继续完善。
以下举例在 OpenMLDB CLI 下,离线引擎的错误信息改进。
-- v0.6.x 的错误信息输出
127.0.0.1:7125/db> SELECT * FROM t1;
Error: Fail to get TaskManager client从上面可以看到,v0.6.x 错误信息消息提示相对模糊,并未显示详细的错误原因。
版本改进以后,错误消息输出如下:
-- v0.7.0 的错误信息输出
127.0.0.1:7125/db> SELECT * FROM t1;
Error: [2001] async offline query failed--ReturnCode[1003]--Fail to get TaskManager client相比较以前打印出更多的错误栈内消息提示:
[2001] async offline query failed:第一层捕获的错误信息,显示离线引擎在异步模式下执行失败,错误码为 2001,需要进一步查看错误链的后续错误代码或者信息ReturnCode[1003]:第二层捕捉的错误信息,错误码为 1003,通过查看错误代码文档可知,该错误码 1003 主要代表:“客户端连接服务端出错,通常出现在连接 TaskManager 失败,可能 TaskManager 并未启动或者不在集群中”
错误代码文档详见如下链接:https://openmldb.ai/docs/zh/m...
设定内存使用上限,增强服务稳定性
根据过往经验,OpenMLDB 作为在线服务,使用过程中最常见的稳定性问题是内存资源耗尽,导致 tablet 被操作系统杀掉,最终造成整体业务下线的风险。而内存资源耗尽往往属于无意中的非正常行为(比如突发流量洪峰,或者某些运维操作),带来极高的问题排查难度。为此,v0.7.0 规划了内存资源隔离及告警系统两个新功能,降低由于内存消耗带来的业务风险:
- 内存资源隔离,将内存资源消耗在可控范围内(v0.7.0 部分实现)
- 告警系统,在内存超过某一个使用阈值时,通知相关运维系统或运维人员(规划中,预期 v0.8.0 发布)
v0.7.0 实现了一个针对 tablet 粒度的配置参数 max_memory_mb (见 tablet 配置文件 https://openmldb.ai/docs/zh/m...),该配置会限制当前 tablet 可以使用的最大内存。当内存使用量超过预设值时,写操作将会失败,但是不会影响读操作,服务依然在线,即读相关的业务依然可以保持正常。用户后续可以通过扩容、分片迁移等手段彻底解决内存资源不够的问题,从而将对对于线上业务的影响降至最低。
下图显示了当设置单个 tablet 的内存限制为 500 MB 的时候,在不断写入操作下,该 tablet 的内存资源占用随着时间推移的情况。可以看到在测试场景下,该 tablet 内存占用初始持续上涨,当到达设定的内存最大使用值时,即使不断再进行写入,内存占用不会上涨(写入会返回失败),从而保证了该 tablet 的内存使用量在可控范围内,避免导致业务下线等严重问题。
新增自动化部署和启动工具,降低使用门槛
OpenMLDB 0.7.0 之前的版本存在较为复杂的部署和启动命令,以及一些隐含的顺序依赖,往往给使用者带来很多困扰,耗费不必要的精力。当前版本针对性的改进了部署,服务启动和停止命令。
在 v0.7.0 以前,部署并且启动 OpenMLDB 集群服务需要分别对 ZooKeeper、tablets、nameserver、APIServer、TaskManager 五个组件进行部署和启动,总计二十多条命令,并且容易出现配置不一致而导致启动失败。
v0.7.0 引入了三个自动化命令,deploy-all, start-all, stop-all 分别用于一键化集群部署、启动、停止。用户只需要一次性正确配置环境,就可以正确地进行自动化部署和服务启动/停止。
下图显示了执行 deploy-all 命令以后的输出信息,可以看到该命令自动进行了 tablet、nameserver、APIServer 等组件的自动化部署。

下图显示了执行 start-all 工具以后的输出信息,可以看到该命令按照正确的顺序,自动启动了 tablet、nameserver、TaskManager 等组件。
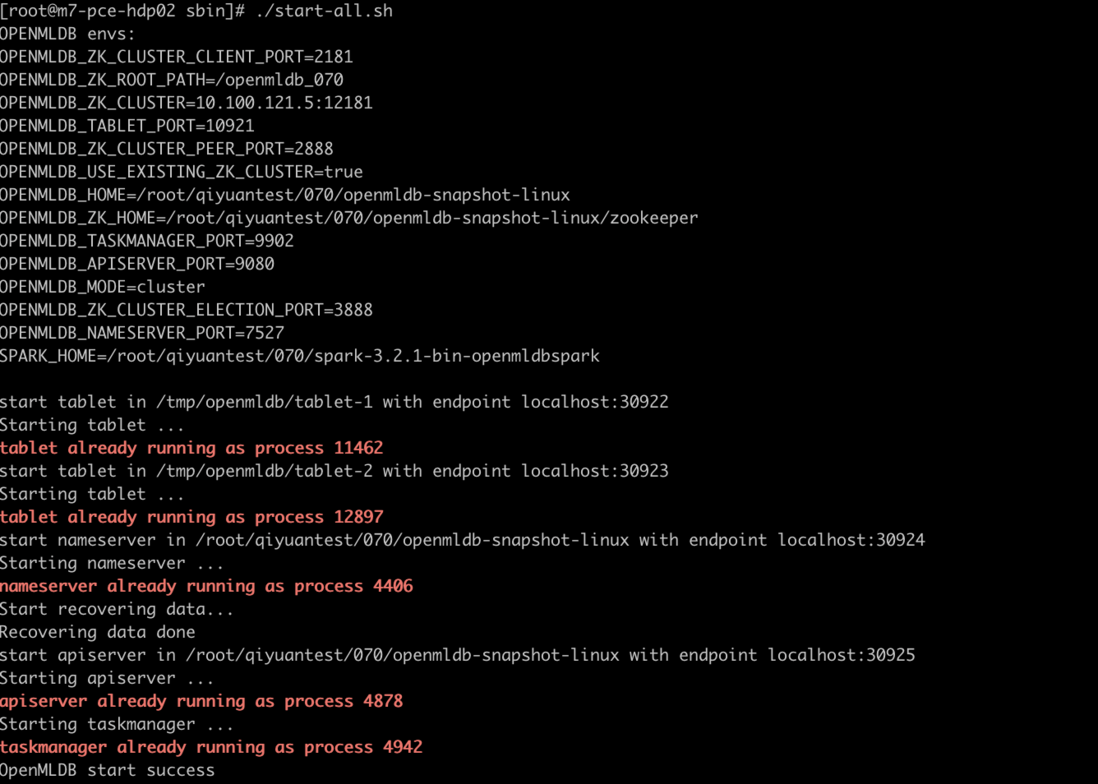
在使用了 deploy-all 以及 start-all 命令以后,原本复杂的部署和启动过程简化为一行命令,大大降低了整体的使用门槛。













