
本文以流式数据入库的场景为基础,介绍引入 Iceberg 作为落地格式和嵌入 Flink sink 的收益,并分析了当前可实现的框架及要点。
应用场景
流式数据入库,是大数据和数据湖的典型应用场景。上游的流式数据,如日志,或增量修改,通过数据总线,经过必要的处理后,汇聚并存储于数据湖,供下游的应用(如报表或者商业智能分析)使用。

上述的应用场景通常有如下的痛点,需要整个流程不断的优化:
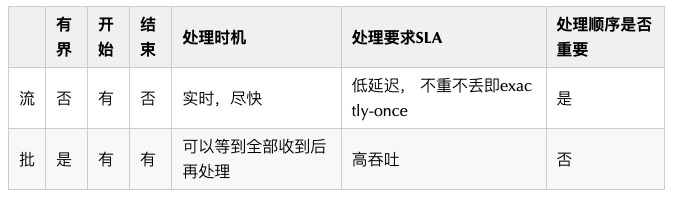
- 支持流式数据写入,并保证端到端的不重不丢(即 exactly-once);
- 尽量减少中间环节,能支持更实时(甚至是 T+0)的读取或导出,给下游提供更实时更准确的基础数据;
- 支持 ACID,避免脏读等错误发生;
- 支持修改已落地的数据,虽然大数据和数据湖长于处理静态的或者缓慢变化的数据,即读多写少的场景,但方便的修改功能可以提升用户体验,避免用户因为极少的修改,手动更换整个数据文件,甚至是重新导出;
- 支持修改表结构,如增加或者变更列;而且变更不要引起数据的重新组织。
引入 Iceberg 作为 Flink sink
为了解决上述痛点,我们引入了 Iceberg 作为数据落地的格式。Iceberg 支持 ACID 事务、修改和删除、独立于计算引擎、支持表结构和分区方式动态变更等特性,很好的满足我们的需求。
同时,为了支持流式数据的写入,我们引入 Flink 作为流式处理框架,并将 Iceberg 作为 Flink sink。
下文主要介绍 Flink Iceberg sink 的实现框架和要点。但在这之前,需要先介绍一些实现中用到的 Flink 基本概念。
Flink 基本概念
从 Flink 的角度如何理解"流"和"批"
Flink 使用 DataFrame API 来统一的处理流和批数据。
Stream, Transformation 和 Operator
一个 Flink 程序由 stream 和 transformation 组成:
- Stream: Transformation 之间的中间结果数据;
- Transformation:对(一个或多个)输入 stream 进行操作,输出(一个或多个)结果 stream。
当 Flink 程序执行时,其被映射成 Streaming Dataflow,由如下的部分组成:
- Source (operator):接收外部输入给 Flink;
- Transformation (operator):中间对 stream 做的任何操作;
- Sink (operator):Flink 输出给外部。
下图为 Flink 官网的示例,展示了一个以 Kafka 作为输入 Source,经过中间两个 transformation,最终通过 sink 输出到 Flink 之外的过程。

State, Checkpoint and Snapshot
Flink 依靠 checkpoint 和基于 snapshot 的恢复机制,保证程序 state 的一致性,实现容错。
Checkpoint 是对分布式的数据流,以及所有 operator 的 state,打 snapshot 的过程。
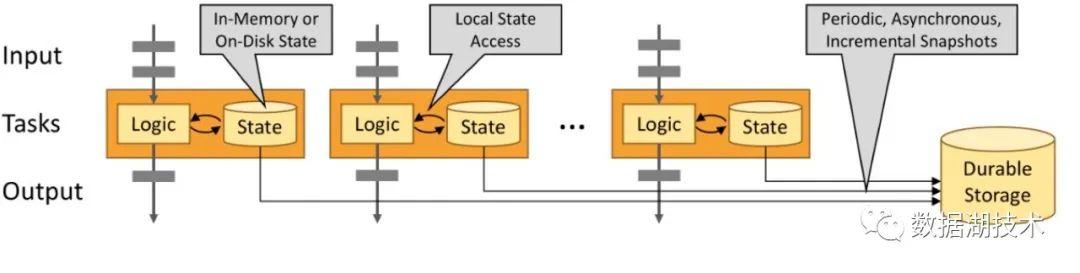
■ State
一个 operator 的 state,即它包含的所有用于恢复当前状态的信息,可分为两类:
- 系统 state:如 operator 中对数据的缓存。
- 用户自定义 state:和用户逻辑相关,可以利用 Flink 提供的 managed state,如 ValueState、ListState,来存储。
State 的存储位置,可以分为:
- Local:内存,或者本地磁盘
- State backend:远端的持久化存储,如 HDFS。
如下图所示:
■ Checkpoint
Flink 做 checkpoint 的过程如下:
- Checkpoint coordinator 首先发送 barrier 给 source。
- Source 做 snapshot,完成后向 coordinator 确认。
- Source 向下游发送 barrier。
- 下游 operator 收到所有上游的 barrier 后,做 snapshot,完成后向 coordinator 确认。
- 继续往下游发送 barrier,直到 sink。
- Sink 通知 coordinator 自己完成 checkpoint。
- Coordinator 确认本周期 snapshot 做完。
如下图所示:

■ Barrier
Barrier 是 Flink 做分布式 snapshot 的重要概念。它作为一个系统标记,被插入到数据流中,随真实数据一起,按照数据流的方向,从上游向下游传递。
由于每个 barrier 唯一对应 checkpoint id,所以数据流中的 record 实际被 barrier 分组,如下图所示,barrier n 和 barrier n-1 之间的 record,属于 checkpoint n。

Barrier 的作用是在分布式的数据流中,将 operator 的多个输入流按照 checkpoint对齐(align),如下图所示:

Flink Iceberg sink
了解了上述 Flink 的基本概念,这些概念又是如何被应用和映射到 Flink Iceberg sink 当中的呢?
总体框架

如图,Flink Iceberg sink 有两个主要模块和两个辅助模块组成:

实现要点
■ Writer
- 在当前的实现中,Java 的 Map 作为每条记录,输入给 writer。内部逻辑先将其转化为作为中间格式的 Avro IndexedRecord,而后通过 Iceberg 里的 Parquet 相关 API,累积的写入 DataFile。
- 使用 Avro 作为中间格式是一个临时方案,为简化适配,并最大限度的利用现有逻辑。但长期来看,使用中间格式会影响处理效率,社区也在试图通过 ISSUE-870 来去掉 Avro,进而使用 Iceberg 内建的数据类型作为输入,同时也需要加入一个到 Flink 内建数据类型的转换器。
- 在做 checkpoint 的过程中,发送 writer 自己的 barrier 到下游的 committer 之前,关闭单个 Parquet 文件,构建 DataFile,并发送 DataFile 的信息给下游。
■ Committer
- 全局唯一的 Committer 在收到上游所有 writer 的 barrier 以后,将收到的 DataFile 的信息填入 manifest file,并使用 ListState 把 manifest file 作为用户自定义的 state,保存于 snapshot 中。
- 当 checkpoint 完成以后,通过 merge append 将 manifest file 提交给 Iceberg。Iceberg 内部通过后续的一系列操作完成 commit。最终让新加入的数据对其他的读任务可见。
试用 Flink Iceberg sink
社区上https://github.com/apache/incubator-iceberg/pull/856提供了可以试用的原型代码。下载该 patch 放入 master 分支,编译并构建即可。如下的程序展示了如何将该 sink 嵌入到 Flink 数据流中:
// Configurate catalog
org.apache.hadoop.conf.Configuration hadoopConf =
new org.apache.hadoop.conf.Configuration();
hadoopConf.set(
org.apache.hadoop.hive.conf.HiveConf.ConfVars.METASTOREURIS.varname,
META_STORE_URIS);
hadoopConf.set(
org.apache.hadoop.hive.conf.HiveConf.ConfVars.METASTOREWAREHOUSE.varname,
META_STORE_WAREHOUSE);
Catalog icebergCatalog = new HiveCatalog(hadoopConf);
// Create Iceberg table
Schema schema = new Schema(
...
);
PartitionSpec partitionSpec = builderFor(schema)...
TableIdentifier tableIdentifier =
TableIdentifier.of(DATABASE_NAME, TABLE_NAME);
// If needed, check the existence of table by loadTable() and drop it
// before creating it
icebergCatalog.createTable(tableIdentifier, schema, partitionSpec);
// Obtain an execution environment
StreamExecutionEnvironment env =
StreamExecutionEnvironment.getExecutionEnvironment();
// Enable checkpointing
env.enableCheckpointing(...);
// Add Source
DataStream<Map<String, Object>> dataStream =
env.addSource(source, typeInformation);
// Configure Ieberg sink
Configuration conf = new Configuration();
conf.setString(
org.apache.hadoop.hive.conf.HiveConf.ConfVars.METASTOREWAREHOUSE.varname,
META_STORE_URIS);
conf.setString(IcebergConnectorConstant.DATABASE, DATABASE_NAME);
conf.setString(IcebergConnectorConstant.TABLE, TABLE_NAME);
// Append Iceberg sink to data stream
IcebergSinkAppender<Map<String, Object>> appender =
new IcebergSinkAppender<Map<String, Object>>(conf, "test")
.withSerializer(MapAvroSerializer.getInstance())
.withWriterParallelism(1);
appender.append(dataStream);
// Trigger the execution
env.execute("Sink Test");后续规划
Flink Iceberg sink 有很多需要完善的地方,例如:上文中提到的去掉 Avro 作为中间格式;以及在各种失败的情况下是否仍能保证端到端的 exactly-once;按固定时长做 checkpoint,在高低峰时生成不同大小的 DataFile,是否对后续读不友好等。这些问题都在我们的后续规划中,也会全数贡献给社区。
参考资料:
[1] Iceberg 官网:
https://iceberg.apache.org/
[2] Flink 1.10文 档:
https://ci.apache.org/projects/flink/flink-docs-release-1.10/
[3] Neflix 提供的 Flink Iceberg connector 原型:
https://github.com/Netflix-Skunkworks/nfflink-connector-iceberg
[4] Flink Iceberg sink 设计文档:
https://docs.google.com/document/d/19M-sP6FlTVm7BV7MM4Om1n_MVo1xCy7GyDl_9ZAjVNQ/edit?usp=sharing
[5] Flink 容错机制(checkpoint) :
https://www.cnblogs.com/starzy/p/11439988.html
# 社区活动推荐 #
普惠全球开发者,这一次,格外与众不同!首个 Apache 顶级项目在线会议 Flink Forward 全球直播中文精华版来啦,聚焦 Alibaba、Google、AWS、Uber、Netflix、新浪微博等海内外一线厂商,经典 Flink 应用场景,最新功能、未来规划一览无余。点击下方链接可了解更多大会详情:https://developer.aliyun.com/live/2594?spm=a2c6h.14242504.J_6074706160.2.3fca361f4cYyQx








