
内容一览:疟疾是严重危害人类生命健康的重大传染病,研究人员一直在致力于寻找新的植物源性抗疟疾化合物,以研发相关药物。近期英国皇家植物园利用机器学习 算法 有效预测了植物抗疟性,该研究成果目前已发表在《Frontiers in Plant Science》期刊上。
关键词:植物学 抗疟疾 支持向量
作者 | 缓缓
编辑 | 三羊
本文首发自 HyperAI 超神经微信公众平台~
疟疾是一种肆虐全球的寄生虫病,它通过蚊媒传播,其发病率以及致死率始终在虫媒传播疾病中居高不下。根据最新的《世界疟疾报告》,2021 年全球疟疾流行进一步加剧,全年共有 2.47 亿例新发病例,预计死亡病例 61.9 万人。
目前全球仍以药物治疗作为主要的疟疾防治手段,并且很多药物的抗疟疾活性天然分子都来源于植物之中,因此,研究人员们一直致力于寻找新的植物源性抗疟疾化合物,不过,为了达到这个目的,需要对大量的植物进行筛选和测试,这个过程非常耗时且昂贵。
近期,英国皇家植物园 (Royal Botanic Gardens, Kew) 及圣安德鲁斯大学 (University of St Andrews) 的研究人员证明了机器学习算法能够有效预测植物抗疟性,且准确率为 0.67,相较传统试验方法的 0.46,已有了明显提升。目前,该研究成果已发表在《Frontiers in Plant Science》期刊上,标题为《Machine learning enhances prediction of plants as potential sources of antimalarials》。

该研究成果已发表在《Frontiers in Plant Science》上
数据集及抽样偏差校正
本实验重要目标之一是评估是否可以用植物特征数据训练机器学习模型来预测植物抗疟活性。首先,研究人员提供了一个数据集,该数据集基于龙胆目的 3 个花卉植物科——夹竹桃科、马钱科和茜草科的 21,100 个植物物种。 这些植物已被发现含有许多生物碱,如抗疟生物碱奎中的奎宁以及其异构体奎尼丁等。

图 1:夹竹桃、马钱和茜草科中含有抗疟疾生物碱的实例
A:在夹竹桃科植物中发现的一种生物碱:Aspidocarpine。
B:在马钱子科植物中发现的一种生物碱:Strychnogucine。
C:在茜草科植物中发现的、现被广泛用于抗疟药物中的生物碱:Quinine(奎宁)。
数据集具体包括植物形态特征、生物化学特征、生长环境条件以及地理位置等信息,下图展现了这份数据集中二元特征之间(只有两种取值的特征,如有毒/无毒)的关系。

图 2:数据集中二元特征间的关系
X 轴:二元特征。
Y 轴:每个特征的平均值,其中每个特征代表了不同的植物属性,如是否有毒、是否被用作传统药物等。
如图所示,所有植物物种中有 10% 被用作传统药物,而有毒植物物种有 77% 被用作传统药物,研究人员将这种差异称为抽样偏差,并且提出抽样偏差是由民族植物法 (ethnobotanical approach) 造成的。
民族植物学是指通过寻找和研究当地居民用于治疗疾病的植物来寻找药用植物,但因为不同地区和不同文化之间存在差异, 就可能会出现某一种或几种具有抗疟性的植物频繁地在数据集里出现,而导致其他可能具有抗疟性的植物被忽略,这就是所谓的抽样偏差。
为了更好地训练模型,研究人员对抽样偏差进行了校正,具体方式是对每个植物物种进行重新加权,即使用了反向概率加权 (Inverse Probability Weighting) ,这样每个物种样本都能在模型训练中被平等对待,从而提高数据集的代表性和模型的性能。
实验成果展示
模型训练及验证
本次实验中,研究人员训练了基于支持向量 (SVC)、逻辑 回归 (Logit)、XGBoot (XGB) 以及贝叶斯神经网络 (BNN) 的 4 种机器学习模型,并将这些模型与 2 种民族植物学方法——寻找传统抗疟植物和寻找传统药用(不特定于疟疾)植物进行比较。
对于基于 Logit、SVC 和 XGB 的 3 个模型,研究人员的训练方法是通过 GridSearchCV 算法对模型的超参数进行调整,并使用 F0.5 指标来评估模型性能。其中,研究人员对基于 Logit、SVC 的两个模型调整了 正则化 参数 C 和 class_weight 参数;对基于 XGB 的模型,则调整了 max_depth 参数。
对于基于 BNN 的模型,研究人员使用了两层分别有 10 个和 5 个的神经网络以及 tahn 激活函数 (activation function),又通过 100,000 个马尔可夫链蒙特卡洛迭代 (Markov chain Monte Carlo iterations) 来训练模型。
在验证阶段,研究人员在两种情况(没有进行抽样偏差校正和进行抽样偏差校正)下采用 10 次迭代的 10 折分层交叉验证 (10 iterations of 10-fold stratified cross validation) 方法对模型性能进行评估。
实验结果
首先是没有进行抽样偏差校正情况下,研究人员对筛选植物源性抗疟化合物的实验结果如下:
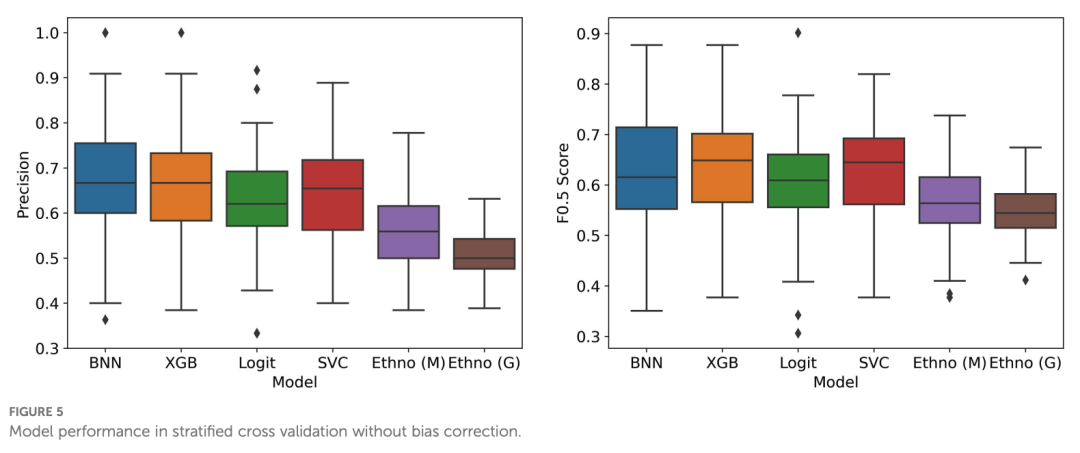
图 3:没有进行偏差校正情况下机器学习模型与 2 种民族植物法对比
如图所示,总体来看,机器学习模型的平均得分比 2 种民族植物法都要高, 并且能从数据特征中预测抗疟活性 (BNN: 0.66,XGB: 0.66,Logit: 0.62,SVC:0.65,Ethno (M): 0.57,Ethno (G): 0.50)。
进行了偏差校正情况下,研究人员对筛选植物源性抗疟化合物的实验结果如下:
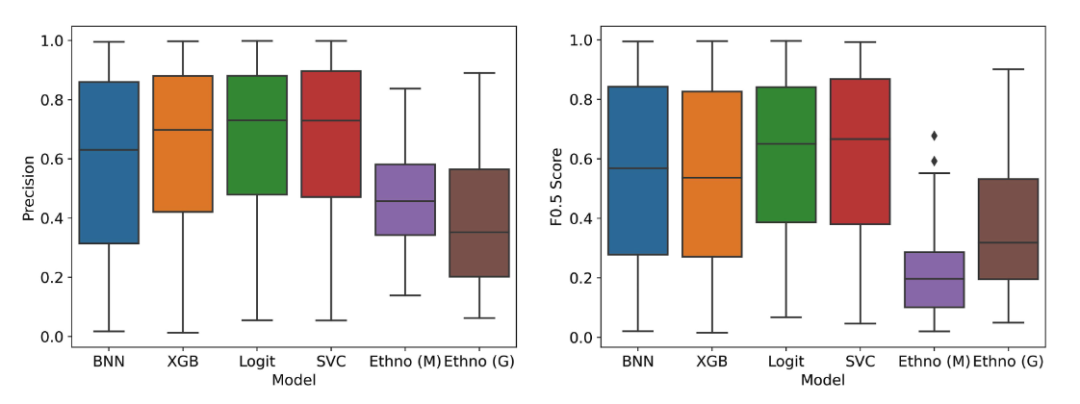
图 4:进行了偏差校正情况下机器学习模型与 2 种民族植物法对比
如图所示,虽然由于对训练和测试集增加了 权重 ,使得模型性能的方差较高,但机器学习模型表现仍然比民族植物学方法要好。 研究人员将传统植物选择法的准确率估计为 0.47,而机器模型的预测准确率则普遍高于这个数字 (BNN: 0.59,XGB: 0.63,Logit: 0.66,SVC: 0.67)。
不过,虽然此实验成果展示了机器学习模型可以相对准确地筛选出具有抗疟活性的植物,但研究人员称,该实验仍有需要改进的部分:
- 增加训练数据: 目前训练数据集相对较小,需要增加更多的植物物种数据来进一步提高模型的性能。
- 解决抽样偏差问题: 虽然本实验中已经试图解决抽样偏差问题,但仍需要发掘更多的偏差校正方法。
- 优化特征选择:需要进行更多的植物特征选择和优化。
- 进一步测试物种数量过少或样本分布不均衡的植物物种: 对于现有数据中代表性不足的物种,需要进行更多的测试,以获得更准确的结果。
英国皇家植物园:发现植物的力量
对于本项研究成果,英国皇家植物园院长表示:「我们的研究结果显示了植物在生产新药方面拥有巨大潜力。 据估计,目前已知的维管植物物种有 34,300 种,但很多并没有得到深入的科学研究。我们希望机器学习方法能够应用在这方面,以寻找新的药用化合物。 并且这些成果也凸显了保护生物多样性和可持续发展自然资源的重要性。」
闻名于世的英国皇家植物园 (Royal Botanic Gardens, Kew) 通常被简称为「邱园」(Kew Gardens) 。邱园是国际知名植物研究与教育机构,由英国政府环境食品和乡村事务部 (Department for Environment, Food and Rural Affairs, UK) 资助,它是一个非政府部门性质的公立团体。邱园的目标是:「保护生物多样性,研发基于自然的解决方案,来应对人类面临的全球性挑战。」
大约在几个月之前,有新闻报道致力于可持续发展的基金 Greensphere Capital 计划对邱园投资 1 亿英镑,该笔投资将用于可持续农业以及招聘新的研究人员来研究植物和真菌科学、栖息地保护、农业及林业等项目。
本文首发自 HyperAI 超神经微信公众平台~














