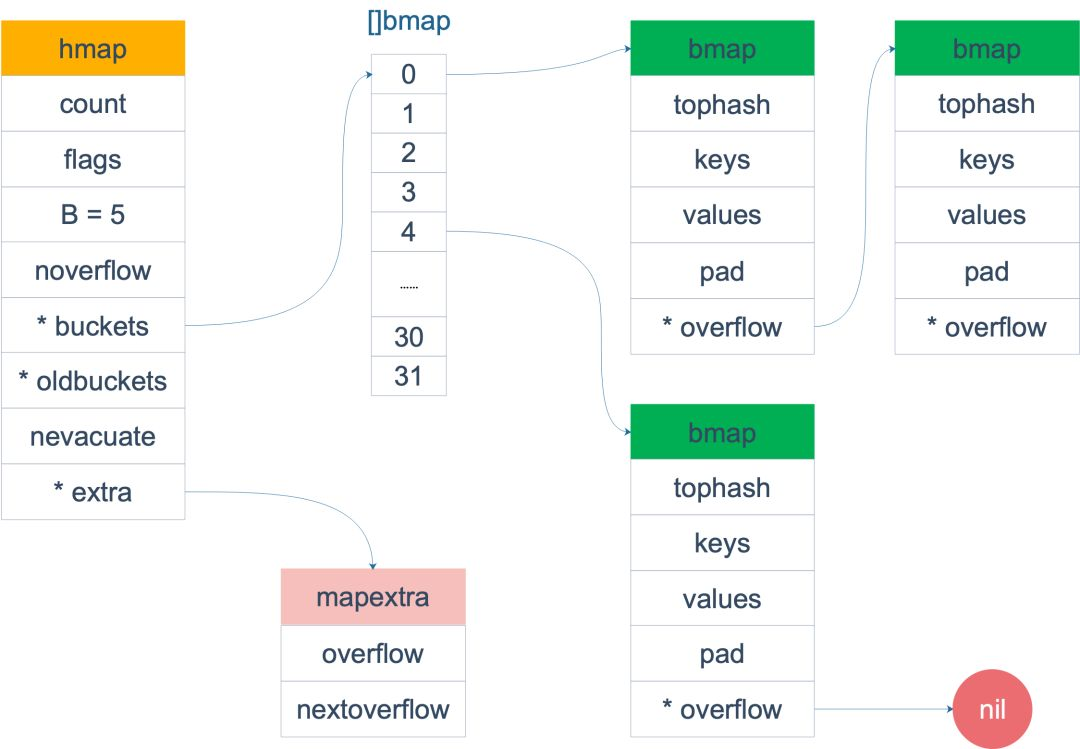
哈希冲突是指在哈希表中,两个或多个元素被映射到了同一个位置的情况。
String str1 = "3C";
String str2 = "2b";
int hashCode1 = str1.hashCode();
int hashCode2 = str2.hashCode();
System.out.println("字符串: " + str1 + ", hashCode: " + hashCode1);
System.out.println("字符串: " + str2 + ", hashCode: " + hashCode2);程序的运行结果如下:
不同的字符串,却拥有了相同的 hashCode 这就是哈希冲突。因为元素的位置是根据 hashCode 的值进行定位的,此时它们的 hashCode 相同,但一个位置只能存储一个值,这就是哈希冲突。
解决哈希冲突
在 Java 中,解决哈希冲突的常用方法有以下三种:链地址法、开放地址法和再哈希法。
- 链地址法(Separate Chaining):将哈希表中的每个桶都设置为一个链表,当发生哈希冲突时,将新的元素插入到链表的末尾。这种方法的优点是简单易懂,适用于元素数量较少的情况。缺点是当链表过长时,查询效率会降低。
- 开放地址法(Open Addressing):当发生哈希冲突时,通过一定的探测方法(如线性探测、二次探测、双重哈希等)在哈希表中寻找下一个可用的位置。这种方法的优点是不需要额外的存储空间,适用于元素数量较多的情况。缺点是容易产生聚集现象,即某些桶中的元素过多,而其他桶中的元素很少。
- 再哈希法(Rehashing):当发生哈希冲突时,使用另一个哈希函数计算出一个新的哈希值,然后将元素插入到对应的桶中。这种方法的优点是简单易懂,适用于元素数量较少的情况。缺点是需要额外的哈希函数,且当哈希函数不够随机时,容易产生聚集现象。
链地址法 VS 开放地址法
链地址法和开放地址法个人觉得以下几点不同:
- 存储结构不同:链地址法规定了存储的结构为链表(每个桶为一个链表),每次将值存储到链表的末尾;而开放地址法未规定存储的结构,所以它可以是链表也可以是树结构等。
- 查找方式不同:链地址法查找时,先通过哈希函数计算出哈希值,然后在哈希表中查找对应的链表,再遍历链表查找对应的值。而开放地址法查找时,先通过哈希函数计算出哈希值,然后在哈希表中查找对应的值,如果查找到的值不是要查找的值,就继续查找下一个值,直到查找到为止。
- 插入方法不同:链地址法插入时,先通过哈希函数计算出哈希值,然后在哈希表中查找对应的链表,再将值插入到链表的末尾。而开放地址法插入时,是通过一定的探测方法,如线性探测、二次探测、双重哈希等,在哈希表中寻找下一个可用的位置。所以链地址法插入方法实现非常简单,而开放地址法插入方法实现相对复杂。
线性探测 VS 二次探测
线性探测是发生哈希冲突时,线性探测会在哈希表中寻找下一个可用的位置,具体来说,它会检查哈希表中下一个位置是否为空,如果为空,则将元素插入该位置;如果不为空,则继续检查下一个位置,直到找到一个空闲的位置为止。
二次探测是发生哈希冲突时,二次探测会使用一个二次探测序列来寻找下一个可用的位置,具体来说,它会计算出一个二次探测序列,然后依次检查哈希表中的每个位置,直到找到一个空闲的位置为止。二次探测的优点是相对于线性探测来说,它更加均匀地分布元素,缺点是当哈希表的大小改变时,需要重新计算二次探测序列。
具体来说,二次探测序列是一个二次函数,它的形式如下:
f(i) = i^2
其中,i 表示探测的步数,f(i) 表示探测的位置。
例如,当发生哈希冲突时,如果哈希表中的第 k 个位置已经被占用,那么二次探测会依次检查第 k+1^2、第 k-1^2、第 k+2^2、第 k-2^2、第 k+3^2、第 k-3^2……等位置,直到找到一个空闲的位置为止。
二次探测的优点是相对于线性探测来说,它更加均匀地分布元素,但缺点是容易产生二次探测聚集现象,即某些桶中的元素过多,而其他桶中的元素很少。
HashMap 如何解决哈希冲突?
在 Java 中,HashMap 使用的是开放地址法解决哈希冲突的,因为在 JDK 1.8 之后(包含 JDK 1.8),HashMap 使用的数组 + 链表或红黑树的结构来存储数据了,所以显然不能使用链地址法来解决哈希冲突。
本文已收录至《Java面试突击》,专注 Java 面试 100 年,查看更多:www.javacn.site