
在机器学习中,L1正则化、L2正则化和Elastic Net正则化是用来避免过拟合的技术,它们通过在损失函数中添加一个惩罚项来实现。
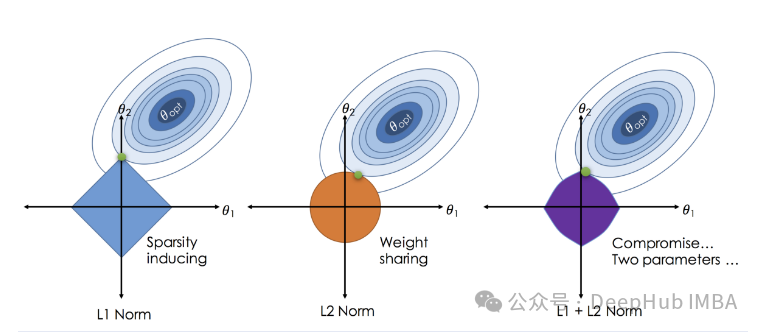
正则化介绍
L1 正则化(Lasso回归):
L1 正则化通过向损失函数添加参数的绝对值的和来实施惩罚,公式可以表示为:
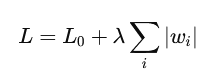
其中 L0 是原始的损失函数,λ 是正则化强度,wi是模型参数。
L1 正则化的特点是它可以产生稀疏模型,即许多模型参数会被设置为零。这种特性使得L1正则化不仅可以防止过拟合,还可以进行特征选择。
L2 正则化(Ridge回归):
L2 正则化通过添加参数的平方和来施加惩罚,公式为:
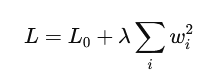
λ 控制着正则化的强度。
L2 正则化倾向于让参数值趋近于零但不会完全为零,这有助于处理参数值过大的问题,从而减少模型在训练数据上的过拟合。
Elastic Net 正则化:
Elastic Net 正则化是L1和L2正则化的组合,它在损失函数中同时添加了L1和L2惩罚项,公式为:
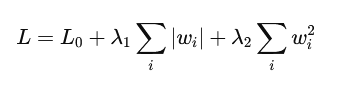
这种方法结合了L1和L2的优点,既可以产生稀疏模型,也可以平滑模型参数。
在实际应用中,Elastic Net特别适合于那些特征数量多于样本数量,或者特征之间高度相关的情况。
在sklearn中,我们可以使用内置的回归函数来实现
Lasso回归是应用L1正则化的典型模型。它可以通过
Lasso类实现;Ridge回归使用L2正则化。它可以通过
Ridge类来实现;Elastic Net回归结合了L1和L2正则化。它通过
ElasticNet类实现
Pytorch代码实现
但是这些都是最简单的线性回归的扩展,通过上面的介绍,我们看到这些正则化的方式都是通过修改模型本身的权重来实现的,所以我们可以在MLP上也使用这些正则化的方法,下面我们将使用Pytorch来演示这个步骤
首先我们看下L1
importos
importtorch
fromtorchimportnn
fromtorchvision.datasetsimportMNIST
fromtorch.utils.dataimportDataLoader
fromtorchvisionimporttransforms
classMLP(nn.Module):
'''
Multilayer Perceptron.
'''
def__init__(self):
super().__init__()
self.layers=nn.Sequential(
nn.Flatten(),
nn.Linear(28*28*1, 64),
nn.ReLU(),
nn.Linear(64, 32),
nn.ReLU(),
nn.Linear(32, 10)
)
defforward(self, x):
'''Forward pass'''
returnself.layers(x)
defcompute_l1_loss(self, w):
returntorch.abs(w).sum()
if__name__=='__main__':
# Set fixed random number seed
torch.manual_seed(42)
# Prepare CIFAR-10 dataset
dataset=MNIST(os.getcwd(), download=True, transform=transforms.ToTensor())
trainloader=torch.utils.data.DataLoader(dataset, batch_size=10, shuffle=True, num_workers=1)
# Initialize the MLP
mlp=MLP()
# Define the loss function and optimizer
loss_function=nn.CrossEntropyLoss()
optimizer=torch.optim.Adam(mlp.parameters(), lr=1e-4)
# Run the training loop
forepochinrange(0, 5): # 5 epochs at maximum
# Print epoch
print(f'Starting epoch {epoch+1}')
# Iterate over the DataLoader for training data
fori, datainenumerate(trainloader, 0):
# Get inputs
inputs, targets=data
# Zero the gradients
optimizer.zero_grad()
# Perform forward pass
outputs=mlp(inputs)
# Compute loss
loss=loss_function(outputs, targets)
# Compute L1 loss component
l1_weight=1.0
l1_parameters= []
forparameterinmlp.parameters():
l1_parameters.append(parameter.view(-1))
l1=l1_weight*mlp.compute_l1_loss(torch.cat(l1_parameters))
# Add L1 loss component
loss+=l1
# Perform backward pass
loss.backward()
# Perform optimization
optimizer.step()
# Print statistics
minibatch_loss=loss.item()
ifi%500==499:
print('Loss after mini-batch %5d: %.5f (of which %.5f L1 loss)'%
(i+1, minibatch_loss, l1))
current_loss=0.0
# Process is complete.
print('Training process has finished.')我们在本身的一个简单的MLP中增加了一个
compute_l1_loss方法,在我们计算完基本的损失后,还会计算模型参数的L1 损失,然后与基本损失相加,最后使用这个最终损失来进行反向传播。
L2正则化也很容易。我们不取权重值的绝对值,而是取它们的平方。
importos
importtorch
fromtorchimportnn
fromtorchvision.datasetsimportMNIST
fromtorch.utils.dataimportDataLoader
fromtorchvisionimporttransforms
classMLP(nn.Module):
'''
Multilayer Perceptron.
'''
def__init__(self):
super().__init__()
self.layers=nn.Sequential(
nn.Flatten(),
nn.Linear(28*28*1, 64),
nn.ReLU(),
nn.Linear(64, 32),
nn.ReLU(),
nn.Linear(32, 10)
)
defforward(self, x):
'''Forward pass'''
returnself.layers(x)
defcompute_l2_loss(self, w):
returntorch.square(w).sum()
if__name__=='__main__':
# Set fixed random number seed
torch.manual_seed(42)
# Prepare CIFAR-10 dataset
dataset=MNIST(os.getcwd(), download=True, transform=transforms.ToTensor())
trainloader=torch.utils.data.DataLoader(dataset, batch_size=10, shuffle=True, num_workers=1)
# Initialize the MLP
mlp=MLP()
# Define the loss function and optimizer
loss_function=nn.CrossEntropyLoss()
optimizer=torch.optim.Adam(mlp.parameters(), lr=1e-4)
# Run the training loop
forepochinrange(0, 5): # 5 epochs at maximum
# Print epoch
print(f'Starting epoch {epoch+1}')
# Iterate over the DataLoader for training data
fori, datainenumerate(trainloader, 0):
# Get inputs
inputs, targets=data
# Zero the gradients
optimizer.zero_grad()
# Perform forward pass
outputs=mlp(inputs)
# Compute loss
loss=loss_function(outputs, targets)
# Compute l2 loss component
l2_weight=1.0
l2_parameters= []
forparameterinmlp.parameters():
l2_parameters.append(parameter.view(-1))
l2=l2_weight*mlp.compute_l2_loss(torch.cat(l2_parameters))
# Add l2 loss component
loss+=l2
# Perform backward pass
loss.backward()
# Perform optimization
optimizer.step()
# Print statistics
minibatch_loss=loss.item()
ifi%500==499:
print('Loss after mini-batch %5d: %.5f (of which %.5f l2 loss)'%
(i+1, minibatch_loss, l2))
current_loss=0.0
# Process is complete.
print('Training process has finished.')最终的计算过程和L1正则化一样,只不过是计算附加损失的方法不同。
对于L2的正则化Pytorch的Adam优化器有一个官方的参数,叫做权重衰减 weight_decay
optimizer = torch.optim.Adam(mlp.parameters(), lr=1e-4, weight_decay=1.0)你可能不知道他和L2的关系,但是你一定用到过,所以我们这样一解释就非常明白了对吧
最后就是Elastic Net (L1 + L2)
classMLP(nn.Module):
'''
Multilayer Perceptron.
'''
def__init__(self):
super().__init__()
self.layers=nn.Sequential(
nn.Flatten(),
nn.Linear(28*28*1, 64),
nn.ReLU(),
nn.Linear(64, 32),
nn.ReLU(),
nn.Linear(32, 10)
)
defforward(self, x):
'''Forward pass'''
returnself.layers(x)
defcompute_l1_loss(self, w):
returntorch.abs(w).sum()
defcompute_l2_loss(self, w):
returntorch.square(w).sum()
if__name__=='__main__':
# Set fixed random number seed
torch.manual_seed(42)
# Prepare CIFAR-10 dataset
dataset=MNIST(os.getcwd(), download=True, transform=transforms.ToTensor())
trainloader=torch.utils.data.DataLoader(dataset, batch_size=10, shuffle=True, num_workers=1)
# Initialize the MLP
mlp=MLP()
# Define the loss function and optimizer
loss_function=nn.CrossEntropyLoss()
optimizer=torch.optim.Adam(mlp.parameters(), lr=1e-4)
# Run the training loop
forepochinrange(0, 5): # 5 epochs at maximum
# Print epoch
print(f'Starting epoch {epoch+1}')
# Iterate over the DataLoader for training data
fori, datainenumerate(trainloader, 0):
# Get inputs
inputs, targets=data
# Zero the gradients
optimizer.zero_grad()
# Perform forward pass
outputs=mlp(inputs)
# Compute loss
loss=loss_function(outputs, targets)
# Specify L1 and L2 weights
l1_weight=0.3
l2_weight=0.7
# Compute L1 and L2 loss component
parameters= []
forparameterinmlp.parameters():
parameters.append(parameter.view(-1))
l1=l1_weight*mlp.compute_l1_loss(torch.cat(parameters))
l2=l2_weight*mlp.compute_l2_loss(torch.cat(parameters))
# Add L1 and L2 loss components
loss+=l1
loss+=l2
# Perform backward pass
loss.backward()
# Perform optimization
optimizer.step()
# Print statistics
minibatch_loss=loss.item()
ifi%500==499:
print('Loss after mini-batch %5d: %.5f (of which %.5f L1 loss; %0.5f L2 loss)'%
(i+1, minibatch_loss, l1, l2))
current_loss=0.0
# Process is complete.
print('Training process has finished.')也非常的简单,并且我们可以设置两个权重,就是L1和L2的占比,使用不同的加权,可以获得更好的结果。
总结
这篇文章是要是为了介绍L1, L2和Elastic Net (L1+L2)正则化在理论上是如何工作的。并且我们也在PyTorch中使用了L1, L2和Elastic Net (L1+L2)正则化。这三种正则化方法在不同的情况和数据集上有不同的效果,选择哪种正则化方法取决于具体的应用场景和数据特性。
https://avoid.overfit.cn/post/c99ec105e41c4a71a0a1a29735245944











