
缓存是什么?
将各种繁琐或简单的东西全部提取都一个大格子箱里面,下次拿的时候不需要慢慢找,直接快速的就能拿到。这是博主简单粗暴的理解。(没有那么多官方定义,有需要的可以去搜索一下),目的是它解决性能问题,同时能够支撑高并发,高可用。
缓存场景
放到软件开发里面,可以小到存储一些固定信息,定时保存数据、大到小型电商的页面静态化、大型电商商品详情页的缓存架构方案
缓存问题
注:这里针对电商详情页讲述缓存
页面静态化
通常的做法是有一套页面模板,每次数据改变,就自动或者手动的进行静态化html页面(通过模板引擎),然后挂到nginx服务器上,请求过来直接走html即可。如下图:
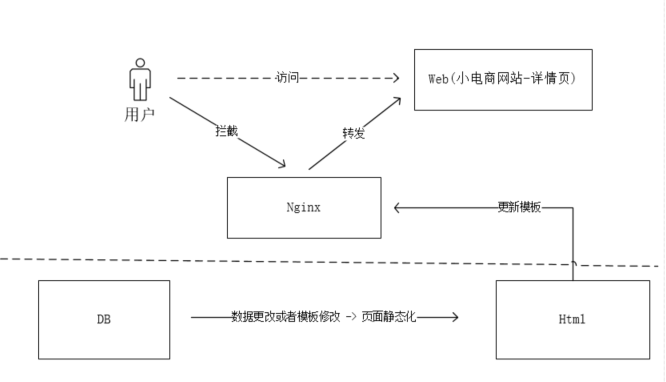
页面静态化
这里数据量小的时候,可以,完全没有问题,对于大数据量,模板或者数据一旦改变,那么就要重新静态化页面,数据量一亿呢,二亿等等,这事明显不靠谱
异步多级缓存构建+nginx数据本地化动态渲染的方案
既然页面静态化走不通,那思路是什么呢?针对大流量详情系统,可以采用目前比较常见的异步多级缓存构建+nginx数据本地化动态渲染的方案, 如下图所示:
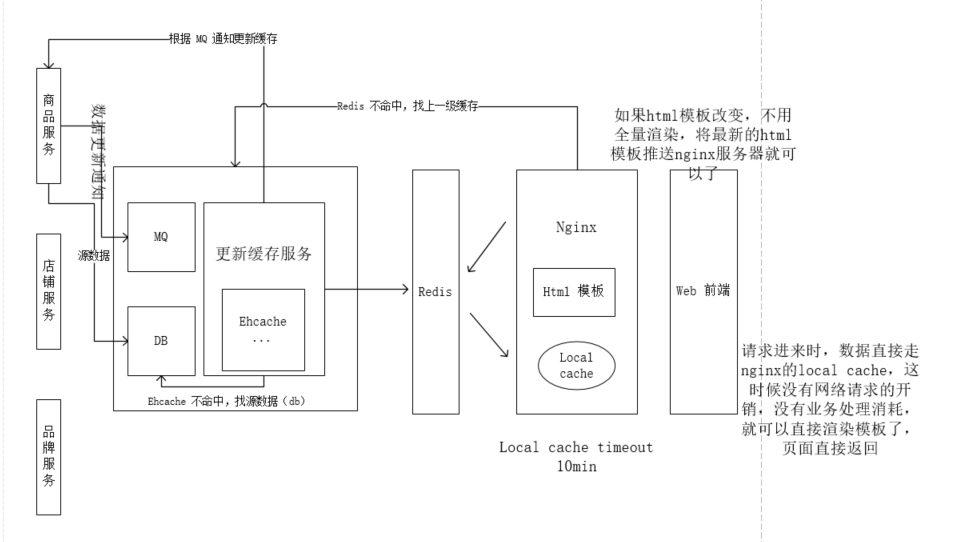
基本思路.png
- 商品服务数据更新,通知mq,更新缓存服务监听到mq的通知后,调用商品服务更新数据到ehcache中,同时更新到redis
- web 请求过来,首先到nginx 本地cache 中找,不命中,到上一级redis,如果有,则取回,不过继续不命中,再向上一级ehcache请求数据
- ehcache 继续不命中,只能请求源数据了
虽然有了思路,但是距离架构方案落地还相差甚远,在具体实现上有诸多细节、难点需要解决。比如:
- 如何解决redis QPS的高并发、高可用、数据备份和恢复
- 如何更好实现 nginx + redis + ehcache 多级缓存架构,结合lua ,三级缓存架构
- 如何解决高并发下的数据库和缓存双写的数据不一致,即数据库、缓存双写解决方案
- 如何解决big value 缓存的全量更新效率低下情况,即缓存维度化拆分
- 如何提高缓存命中率,即双层nginx部署方案,lua实现一致性hash流量分发策略
- 如何解决缓存重建时的分布式并发重建冲突,即基于zookeeper锁的缓存并发重建
- 如何解决缓存冷启动Mysql瞬间打死,即基于storm的实时统计热数据分布式快速缓存预热
- 如何解决热点缓存导致单机器负载瞬间飙高,即基于storm实时热点缓存负载均衡降级
- 如何解决服务高可用、避免多层服务依赖中因少量故障导致系统崩溃,即hystrix 实现资源隔离+ 限流+降级+熔断+超时控制
- 如何解决缓存雪崩,即事前、事中、事后的解决方案
- 如何解决缓存穿透,避免mysql 压力过大,即缓存穿透
- 如何解决缓存失效,避免redis 集群压力过大,即缓存失效
以上问题都是缓存方案落地时需要解决的问题。
解决了以上问题,将拥有一个99.99%高可用、高并发的缓存方案。
以上就是本章内容,如有不对的地方,请多多指教,谢谢!
为了方便有需要的人,本系列全部软件都在 https://pan.baidu.com/s/1qYsJZfY
下章预告:主要讲解 centos 集群搭建及ssh相互免密登录
作者:逐暗者 (转载请注明出处)












