
先奉上图夫地址:https://tufu.xkboke.com
GIT开源地址:git地址(欢迎star)
懒惰驱动Idea
有时候在站酷或者UI中国看到很好的图片和作品都会想收藏下来学习一下,但是每次右击另存为都很麻烦,而且有的还要放大后才有原图可以下载;作为一个伪全栈怎么能忍呢,然后就想着扒扒他们网站的源码看,这一看发现图片原图存放的位置都有着规律,这就很高兴啦,哈哈!
雏形诞生
浪起来!!很快完成了第一个小脚本,顺利把需要的图片下载了下来,但只是最简单的爬取图片,后来优化了一下,把每次下载的图片都放到不同文件夹。但是转头一想,独乐乐不如众乐乐,就想着干脆把这个脚本工具化,做一个可以兼容多个网站的爬虫工具,并且可以批量下载原图,想法很快被付诸实践,经过不断的改版后,终于我的图夫出来了第一版。
迭代优化
一开始只支持站酷和UI中国,而且对其他的网站都兼容的不是很好,没关系,先做出第一版,接着慢慢迭代,后来根据反馈又添加了涂鸦王国,设计癖,视觉ME等网站,最近几天在逛贴吧,发现贴吧的一些图片也是很漂亮,有很多可以当壁纸的图片,但是要下到原图需要三四次步骤,而且一次只能下载一个,所以呢,我又把它加入我的图夫工具中了,哈哈!我的图夫又慢慢壮大起来了!先放一张图展示一下我的图夫

技术栈
其实原理大家都知道的,就是爬虫,只是我把爬虫可视化做成了一个工具,方便日常使用而已,这里主要使用的是express,库的话用的是request,compressing用来压缩文件夹,node-uuid用来生成随机hash;放一张目录结构
部分代码
index.js 主要请求文件,其他文件就移步git查看吧
const path = require('path');
const fs = require('fs');
const analyze = require('./analyze');
const tarTool = require('./tarTool')
const uuid =require('node-uuid')
/**
* 根据hash值创建文件夹
* @param path
*/
function write(path) {
fs.exists(path, function (exists) { //path为文件夹路径
if (!exists) {
fs.mkdir(path, function (err) {
if (err) {
console.log('创建失败');
return false;
} else {
console.log('创建成功');
}
})
}
})
}
/**
* 请求图片地址
* @param response
* @param req
* @param next
*/
function start(req,response,next) {
const hash = uuid.v1().replace(/-/g, "")
const imgDir = path.join(path.resolve(__dirname, '..'), 'output/img/'+hash);
write(imgDir)
// 发起请求获取 DOM
console.log('请求地址',req.url);
request(req.url, function(err, res, body) {
if (!err && res) {
console.log('start');
// 将 downLoad 函数作为参数传递给 analyze 模块的 findImg 方法
analyze.findImg(body,req.type,imgDir,downLoad,req.url);
response.json({head: {code: 0, msg: 'ok'}, data: hash})
}else {
response.json({head: {code: 1000, msg: err}, data: ''})
}
});
}
/**
* 获取到 findImg 函数返回的图片地址后,利用 request 再次发起请求,将数据写入本地。
*
* @param {*} imgUrl
* @param {*} i
* @param {*} imgDir
*/
function downLoad(imgUrl, i,imgDir) {
console.log('图片地址',imgUrl);
let ext = imgUrl.split('.').pop();
// 再次发起请求,写文件
request(imgUrl).pipe(fs.createWriteStream(path.join(imgDir, i + '.' + ext), {
'encoding': 'utf8',
}));
}
/**
* 下载图片到本地后,利用tar压缩成一个压缩包,并返回路径
* @param {*} req
* @param {*} response
* @param {*} next
*/
function tarFile(req,response,next) {
console.log('接收',req);
tarTool.tarTool(req.path,response)
}
module.exports= {
getImg:start,
tarTool:tarFile
}使用方法
当然既然是工具,就必须非常简单啦,你只需复制你要下载页面的URL链接,然后粘贴到我的输入框中就可以,然后选择网站类型(当然悄悄告诉你,不选也没关系,我做了一个校验),然后就是点击搜索了,接下来就是耐心的等待...loading....(因为服务器的带宽只有1M,所以会下载有点慢,如果你愿意打赏一下,我也是不介意的,哈哈),执行完毕后,会出现下载按钮,你只需要点击下载即可下载打包完毕的文件了。

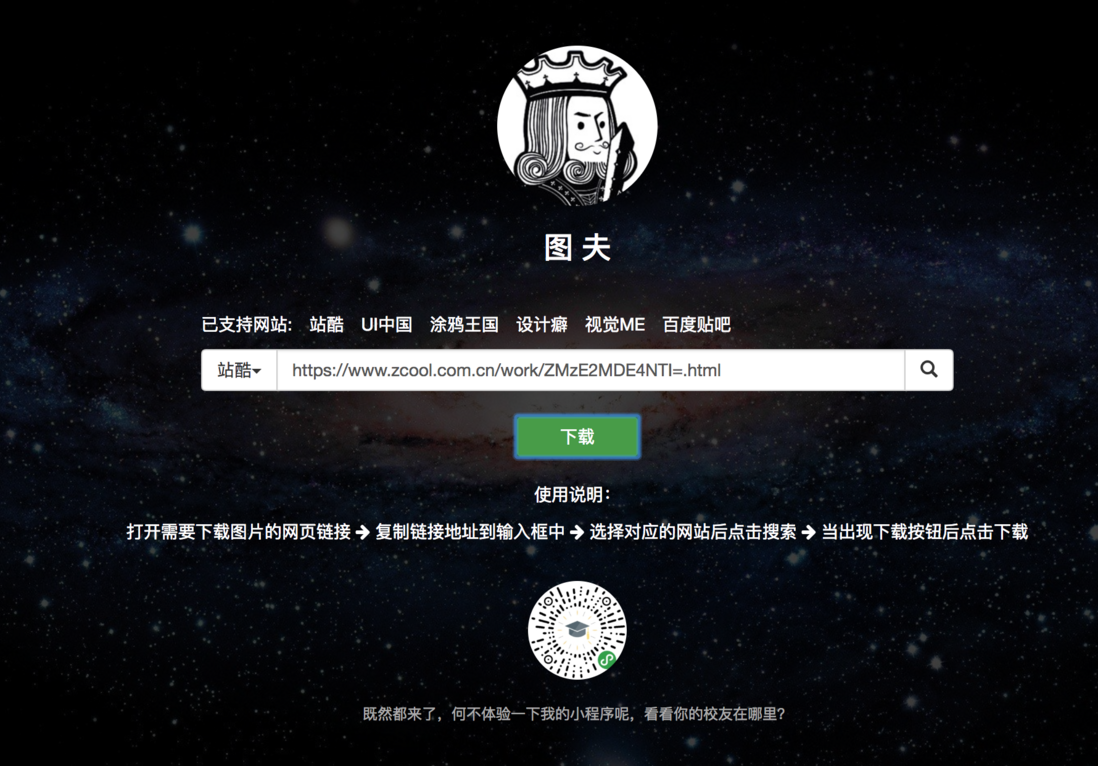


已支持网站
- 站酷
- UI中国
- 涂鸦王国
- 设计癖
- 视觉ME
- 百度贴吧
- ...(等待你的意见)
声明
本工具仅作为技术交流工具,不得用于任何商业用途或获利。本网站不存储任何图片,所有内容均通过爬虫工具爬取网页上存在的内容。通过本网站下载的任何图片不代表你拥有商用的权利或者授权,如需授权或商用请联系原网站作者或平台,谢谢理解!
最后,奉上我的开源GIT地址:https://github.com/gengchen52...
图夫网站地址:https://tufu.xkboke.com
如果喜欢的话,请给个star,如果有什么想法的话可以提issues,也可以微信联系我,欢迎交流,也可在评论中留下你想采集的网站链接,我会不定期更新图夫完全支持的网站
往期文章
使用node脚本全自动删除豆瓣评论与帖子(这个最近正在更新,也会上线可视化操作,敬请关注)
[基于mongodb+express+vue+axios+bootstrap的掘金最热文章收藏评论分析
](https://juejin.im/post/5a1293...
个人博客:www.xkboke.com







