
学习的时候没有太过留意Shuffle这个概念,以至于还以为是不是漏掉了什么知识点,后面看了一些帖子才发现Shuffle原来是map()方法执行结束到reduce()方法执行这么一大段过程....
小声BB:实质上该过程包含许多环节,不知道为啥就统称Shuffle了......
1. Mapper的写出
图见意现 -- 直接上图:
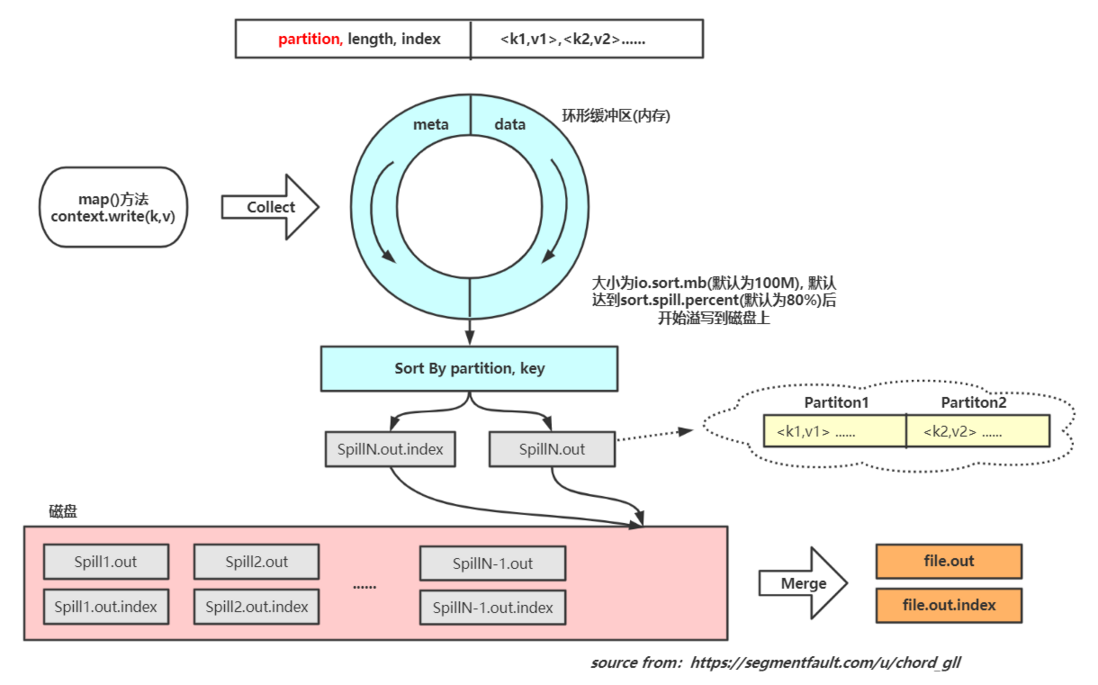
需要明确的点:
- 在环形缓冲区触发溢写时,进行的排序是先根据每个键值对的分区进行排序,然后再根据key进行排序
- 每次写出实际上包括两个文件,一个是meta数据写出形成的index文件,另一个则是排序后的data文件
- 在溢写时发生一次排序,为快速排序算法;在最后合并为一个整体文件时,因为各小文件已有序,直接归并排序即可
- Reducer从Mapper节点的最终文件file.out读取数据,根据index文件只读取对应分区的数据
2. Mapper的分区
分区的作用是将Mapper阶段输出的结果分为不同的区域,并传送给不同的ReduceTask,因此分区数和Reduce的并行度是相互决定的,即 Num Of Partitions = Num Of ReduceTask
设置ReduceTask数量:job.setNumReduceTasks(n)
分区方式:
- 默认方式:hash(key) % Num of ReduceTask -- 键值哈希取模
- 自定义分区类:定义类继承Partitioner类,并重写getPartition()方法
注意:
- 在没有设置ReduceTask数目的情况下,MR默认只分配一个ReduceTask,即不管自定义分区方法需要分几个区,最后的结果都只会进入这一个Reducer,最终生成一个结果文件;
- 如果设置了ReduceTask数量大于1,但该数量小于自定义的分区数,则运行MR程序会报错,因为会产生一些Mapper的结果数据没有Reducer来获取的情况
- 如果设置的分区数 < ReduceTask的数量,那么程序会正常执行,最后也会生成和ReduceTask数相等的结果文件,但其中有 (ReduceTask数 - 分区数) 个空文件,因为这部分的Reducer没有输入
3. Mapper的排序
- 比较简单,溢写时快速排序,合并时归并排序;排序标准为对key进行字典排序
- 可自定义排序(在自定义Bean对象时使用),需要让自定义的Bean类实现WritableComparable接口并重写compareTo方法,实际上和Java中的Comparable基本一样
4. Reducer的读入
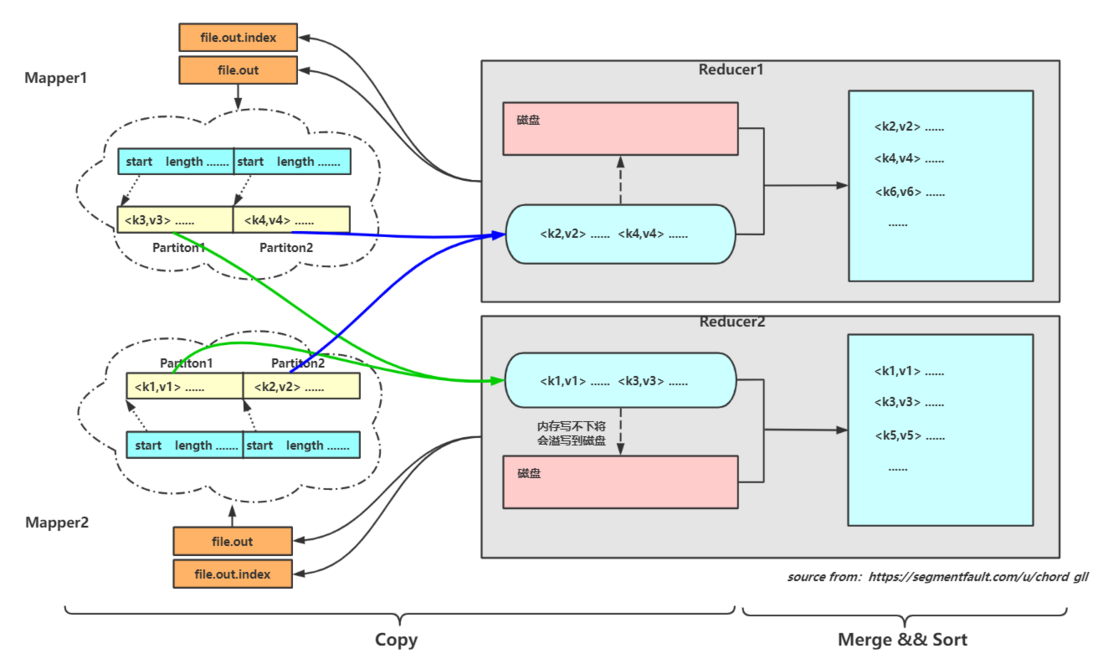
需要明确的点:
- 一个ReduceTask只会读取每个Mapper结果的同一个分区内的数据
- 拷贝到Reducer节点先是保存在内存中,如果内存不够就刷写到磁盘
- 所有数据拷贝完成后,对内存和磁盘(假如发生了刷写)进行Merge && Sort,这里排序也是默认根据Key进行字典排序,目的是让数据中key相同的KV对排列在一起,方便reduce方法的调用。【reduce方法调用前会将所有key相同的value封装为iterator迭代器对象,对于一个key调用一次reduce方法】
5. Reducer的排序
Reduce端的排序同样也是应用于使用了自定义Bean对象的场景,通过自定义的排序方式让Reducer把我们指定的keys判断为同样的key(在默认reduce排序中会被判定为非同key)
注意!注意!注意!此处有坑!!!
- Reducer端的自定义排序需要自定义排序类,继承WritableComparator并重写compare方法,并在Driver中关联我们自定义的排序类
- Mapper端的自定排序需要在我们定义Bean对象的时候让Bean对象继承WritableComparable类并重写方法CompareTo





