
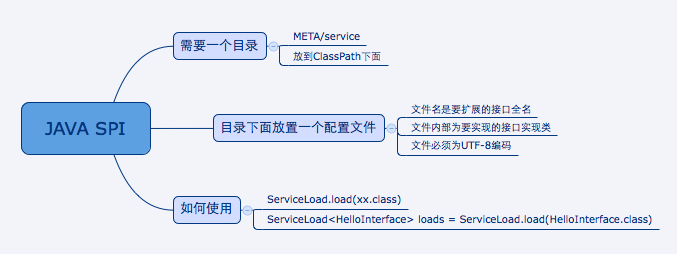
SPI 简介
service provider interface JDK内置的中服务发现机制
一种动态替换发现的机制
此图使用(https://www.jianshu.com/p/46aa69643c97)作者画的
使用方式
实现方式:
写service 具体对外提供的接口
public interface DriverService { String getName(); }
具体的实现,继承对应的接口
public class JavaDriverImpl implements DriverService { @Override public String getName() { return "java implement"; } }
编写META-INF/service 具体的实现类 包名+类名
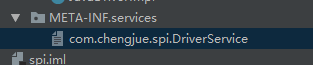
com.chengjue.spi.JavaDriverImpl
- 编译jar包对外提供服务
使用方:
引用相关依赖 jar包
使用ServiceLoader加载使用
public static void main(String[] args) { ServiceLoader
serviceLoader = ServiceLoader.load(DriverService.class); for (DriverService driverService: serviceLoader){ System.out.println(driverService.getName()); } }
实现原理
我们使用的时候都是使用的ServiceLoader加载服务,下面来看下ServiceLoader是具体怎么实现的
ServiceLoader是JDK提供的一个util,在java.uyil包下
我们可以看到他的介绍A simple service-provider loading facility.用来加载服务的
public final class ServiceLoader<S> implements Iterable<S>
我们可以看到他是一个final类型的,不可以被继承修改,同时实现了Iterable接口,方便我们使用迭代器取出所有的实现类
接下来我们可以看到一个熟悉的常量,这个就是我们在前面定义实现类的路径
private static final String PREFIX = "META-INF/services/";
下面便是load方法的具体实现
public static <S> ServiceLoader<S> load(Class<S> service) {
ClassLoader cl = Thread.currentThread().getContextClassLoader();
return ServiceLoader.load(service, cl);
}
public static <S> ServiceLoader<S> load(Class<S> service,
ClassLoader loader)
{
return new ServiceLoader<>(service, loader);
}
private ServiceLoader(Class<S> svc, ClassLoader cl) {
service = Objects.requireNonNull(svc, "Service interface cannot be null");
loader = (cl == null) ? ClassLoader.getSystemClassLoader() : cl;
acc = (System.getSecurityManager() != null) ? AccessController.getContext() : null;
reload();
}
public void reload() {
providers.clear();
lookupIterator = new LazyIterator(service, loader);
}
上面的代码我是根据调用顺序贴出来的,方便阅读
通过跟踪代码发现,在reload方法中具体是通过一个内部类LazyIterator实现的。接下来我们去看LazyIterator的构造方法传入 Class 和ClassLoader。
下面是ServiceLoader的iterator方法实现,这边会去new一个Iterator,首先在ServiceLoader中有一个provider的缓存,每次操作的时候都会先去缓存中查找,否则采取LazyIterator中去查找。
public Iterator<S> iterator() {
return new Iterator<S>() {
Iterator<Map.Entry<String,S>> knownProviders
= providers.entrySet().iterator();
public boolean hasNext() {
if (knownProviders.hasNext())
return true;
return lookupIterator.hasNext();
}
public S next() {
if (knownProviders.hasNext())
return knownProviders.next().getValue();
return lookupIterator.next();
}
public void remove() {
throw new UnsupportedOperationException();
}
};
}
下面是LazyIterator的具体处理
public boolean hasNext() {
if (acc == null) {
return hasNextService();
} else {
PrivilegedAction<Boolean> action = new PrivilegedAction<Boolean>() {
public Boolean run() { return hasNextService(); }
};
return AccessController.doPrivileged(action, acc);
}
}
private boolean hasNextService() {
if (nextName != null) {
return true;
}
if (configs == null) {
try {
//通过PREFIX(META-INF/services/)和类名 获取对应的配置文件,得到具体的实现类
String fullName = PREFIX + service.getName();
if (loader == null)
configs = ClassLoader.getSystemResources(fullName);
else
configs = loader.getResources(fullName);
} catch (IOException x) {
fail(service, "Error locating configuration files", x);
}
}
while ((pending == null) || !pending.hasNext()) {
if (!configs.hasMoreElements()) {
return false;
}
pending = parse(service, configs.nextElement());
}
nextName = pending.next();
return true;
}
public S next() {
if (acc == null) {
return nextService();
} else {
PrivilegedAction<S> action = new PrivilegedAction<S>() {
public S run() { return nextService(); }
};
return AccessController.doPrivileged(action, acc);
}
}
private S nextService() {
if (!hasNextService())
throw new NoSuchElementException();
String cn = nextName;
nextName = null;
Class<?> c = null;
try {
c = Class.forName(cn, false, loader);
} catch (ClassNotFoundException x) {
fail(service,
"Provider " + cn + " not found");
}
if (!service.isAssignableFrom(c)) {
fail(service,
"Provider " + cn + " not a subtype");
}
try {
S p = service.cast(c.newInstance());
providers.put(cn, p);
return p;
} catch (Throwable x) {
fail(service,
"Provider " + cn + " could not be instantiated",
x);
}
throw new Error(); // This cannot happen
}
总结
通过上面的代码学习,发现其实它根本还是通过反射的方式获取具体的实现类的实例,我们只是通过SPI定义的方式,将要暴露对外使用的具体实现在META-INF/services/文件下声明而已。所以对于反射的掌握还是很重要的,无论是spring还是其他的一些框架中经常可以看到反射的使用
在现有框架中的使用
其实了解SPI机制是因为最近看SpringBoot代码的时候发现的,我们知道在SprngBoot中好多的配置和实现都有默认的实现,我们只需要修改部分配置,比如数据库配置,我们只要在配置文件中写上对应的url,username,password就可以使用了。其实他这边用的就是SPI的方式实现的
不过Spring使用的只是和JDK中的原理相同而已。
- JDK使用的工具类是ServiceLoader
- Spring中使用的类是SpringFactoriesLoader,在org.springframework.core.io.support包中
区别:
- 文件路径不同 spring配置放在 META-INF/spring.factories中
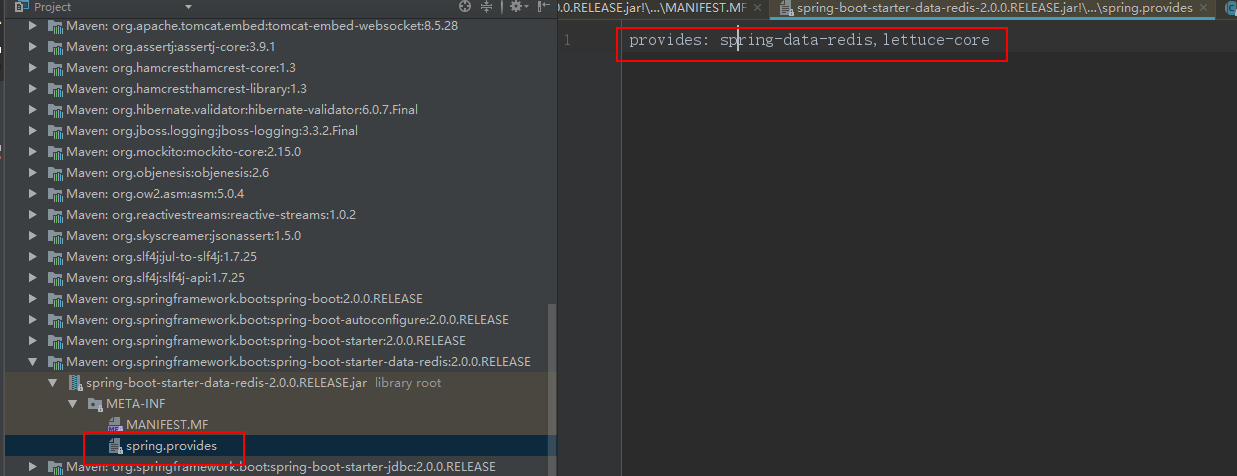
- 具体的实现步骤不一样,不过原理相同,都是使用的反射机制
Spring中实现
public static <T> List<T> loadFactories(Class<T> factoryClass, @Nullable ClassLoader classLoader) {
Assert.notNull(factoryClass, "'factoryClass' must not be null");
ClassLoader classLoaderToUse = classLoader;
if (classLoaderToUse == null) {
classLoaderToUse = SpringFactoriesLoader.class.getClassLoader();
}
List<String> factoryNames = loadFactoryNames(factoryClass, classLoaderToUse);
if (logger.isTraceEnabled()) {
logger.trace("Loaded [" + factoryClass.getName() + "] names: " + factoryNames);
}
List<T> result = new ArrayList<>(factoryNames.size());
for (String factoryName : factoryNames) {
result.add(instantiateFactory(factoryName, factoryClass, classLoaderToUse));
}
AnnotationAwareOrderComparator.sort(result);
return result;
}
学习就是这样,举一反三,如果JDK中的SPI原理搞明白了,再去看Spring中相关的实现就会比较容易理解











