
2020年5月底OpenAI发布了有史以来最强的NLP预训练模型GPT-3,最大的GPT-3模型参数达到了1750亿个参数。论文《Language Models are Few-Shot Learners》长达74页已发布在arXiv。
视频讲解:
有网友估算最大的GPT-3模型大小大约有700G,这个大小即使OpenAI公开模型,我们一般的电脑也无法使用。一般需要使用分布式集群才能把这个模型跑起来。虽然OpenAI没有公布论文的花费,不过有网友估计这篇论文大约花费了上千万美元用于模型训练。
如此惊人的模型在模型的设计上和训练上有什么特别之处吗?答案是没有。作者表示GPT-3的模型架构跟GPT-2是一样的,只是使用了更多的模型参数。模型训练也跟GPT-2是一样的,使用预测下一个词的方式来训练语言模型,只不过GPT-3训练时使用了更多的数据。
既然这样,那这只怪兽特别之处是什么?GPT-3论文的核心在于下图:
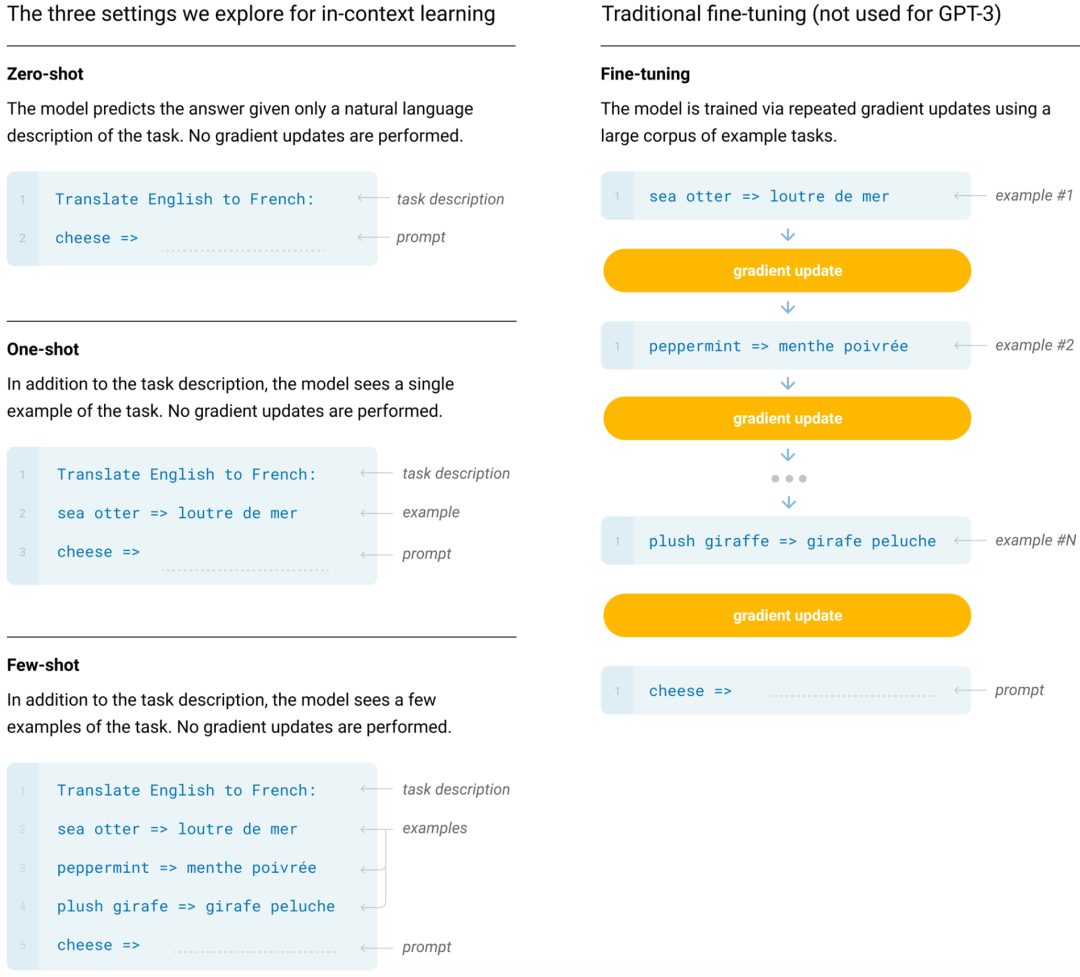
一般的NLP模型都是先预训练一个语言模型,然后再使用这个语言模型来进行Fine-tuning完成不同的任务。比如可以使用文本分类数据集Fine-tuning一个专门用于文本分类的NLP模型;可以使用翻译数据集Fine-tuning一个专门用于翻译的数据集;可以使用问答数据集Fine-tuning一个专门用于问答的数据集等等。
而GPT-3只训练了一个语言模型,没有针对任何任务进行Fine-tuning。但是却可以完成多项NLP任务,并且每一项任务都可以得到很好的效果。如上图所示,GPT-3作者提出了三种模型预测方式,Zero-shot,One-shot,Few-shot。
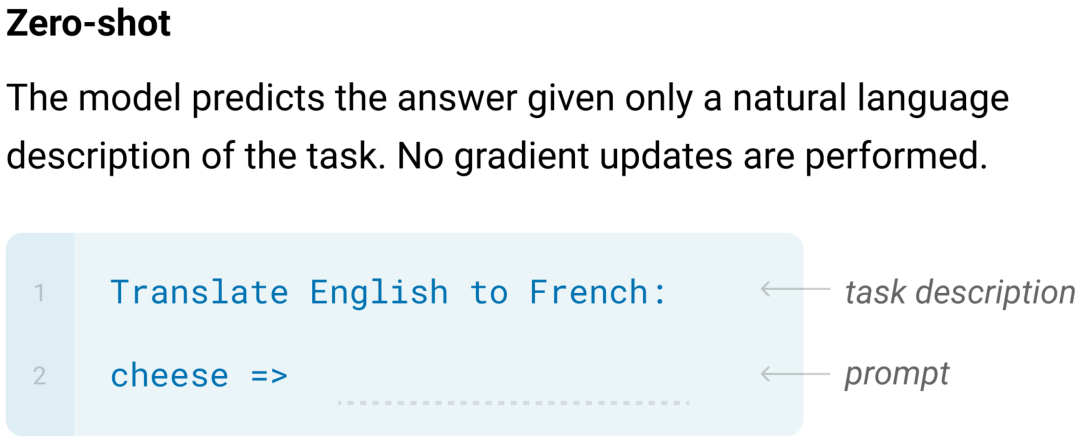
Zero-shot表示直接告诉GPT-3要做的事,然后让它给出结果。比如告诉它"Translate English to French:cheese=>",模型就会输出跟翻译得到的法文。
One-shot表示给模型提出要求后给它举一个实际的例子:

Few-shot表示给模型提出要求后给它举多个实际的例子:

GPT-3神奇的地方就在于我们不需要Fine-tuning模型去学习翻译的任务,它就可以自己学会翻译。
同样的道理,作者使用GPT-3做了大量的实验,完成了大量NLP任务,比如作者用它来完成了填空,翻译,问答,阅读理解等任务并且都取得了不错的效果。而且它还可以用来做数学计算比如给它输入“Q:What is 48 plus 76?A:”,它会输出“124”。


从图标中我们可以看到两位数三位数的加减法做的还不错,位数太高的话准确率就会降低很多。毕竟这个模型的训练过程中从来没有学过数学,它只学习过根据前面的句子来预测后面一个词。所以它能够从词的预测中学习到基本的数学运算也是挺神奇的一件事。
另外它还可以进行文章生成,并且基本上达到了人类很难判别真假的水平。给它传入文章Title,它就可以生成文章内容:

告诉它一个词的用法,还能让它进行造句:

告诉它什么是正确的英文语法,什么是错误的英文语法,它还可以进行语法纠错:

总结:
现在NLP任务的常规做法都是预训练一个语言模型,然后使用语言模型对不同任务进行Fine-tuning,一般Fine-tuning后的一个模型就只能完成一个专门的任务。而GPT-3就像是一个全能选手,基本上所有NLP的任务它都可以胜任并且可以得到不错的效果,这对NLP领域未来的发展来说可能是一个新的启发。
公众号后台回复今天日期:200609,即可下载论文。

想学AI点击下方阅读原文:
👇
本文分享自微信公众号 - AI MOOC人工智能平台(AIMOOC_XLAB)。
如有侵权,请联系 support@oschina.cn 删除。
本文参与“OSC源创计划”,欢迎正在阅读的你也加入,一起分享。













