
ShuffleNet系列是轻量级网络中很重要的一个系列,ShuffleNetV1提出了channel shuffle操作,使得网络可以尽情地使用分组卷积来加速,而ShuffleNetV2则推倒V1的大部分设计,从实际出发,提出channel split操作,在加速网络的同时进行了特征重用,达到了很好的效果
来源:晓飞的算法工程笔记 公众号
ShuffleNet V1
论文: ShuffleNet: An Extremely Efficient Convolutional Neural Network for Mobile Devices

- 论文地址:https://arxiv.org/pdf/1707.01083.pdf
- 论文代码:https://github.com/megvii-model/ShuffleNet-Series/tree/master/ShuffleNetV1
Introduction
神经网络的精度越来越高,而推理性能也在逐渐变慢,在实际应用中不得不在性能与准确率间进行折中。为此,论文对小网络的耗时进行分析,提出了ShuffleNet。论文首先介绍了ShuffleNet的核心操作Channel Shuffle以及Group Convolutions,然后再介绍Shuffle unit的结构,最后介绍ShuffleNet的架构。
Channel Shuffle for Group Convolutions

在目前的一些主流网络中,通常使用pointwise卷积进行维度的降低,从而降低网络的复杂度,但由于输入维度较高,pointwise卷积的开销是十分巨大的。对于小网络而言,昂贵的pointwise卷积会带来明显的性能下降,比如在ResNext unit中,pointwise卷积占据了93.4%的计算量。为此,论文引入了分组卷积,首先探讨了两种ShuffleNet的实现:
- 图1a是最直接的方法,将所有的操作进行了绝对的维度隔离,但这会导致特定的输出仅关联了很小一部分的输入,阻隔了组间的信息流,降低了表达能力。
- 图1b对输出的维度进行重新分配,首先将每个组的输出分成多个子组,然后将每个子组输入到不同的组中,能够很好地保留组间的信息流。
图1b的思想可以简单地用channel shuffle操作进行实现,如图1c所示,假设包含$g$组的卷积层输出为$g\times n$维,首先将输出reshape()为$(g, n)$,然后进行transpose(),最后再flatten()回$g\times n$维。
ShuffleNet Unit
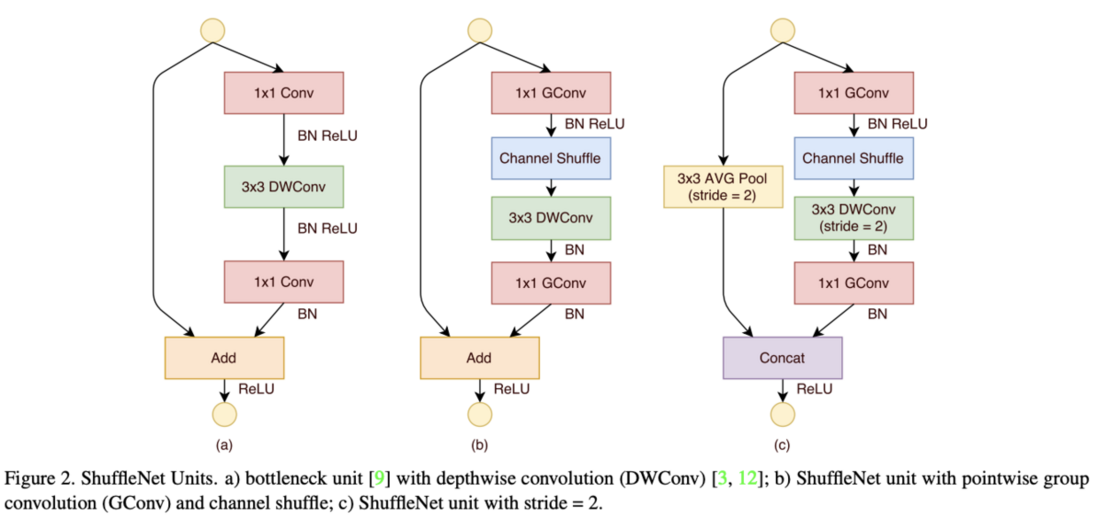
基于channel shuffle操作,论文提出了两种ShuffleNet unit,从图2a的基础残差结构开始,中间包含一个$3\times 3$深度卷积进行特征提取:
- 图2b为特征图大小不变的ShuffeNet unit,将开始的$1\times 1$卷积层替换成pointwise分组卷积+channel shuffle操作,第二个pointwise分组卷积的作用是为了恢复到unit的输入维度,方便与shortcut进行element-wise addition。后面的两个卷积操作根据可分离深度卷积论文的建议只接了BN,没有接BN+ReLU。论文尝试了在第二个pointwise分组卷积后面再接一次channel shuffle操作,但并没有提高很多精度。
- 图2c为特征图大小减半的ShuffleNet unit,可用于block间的特征下采样。主要在shortcut中添加$3\times 3$平均池化以及将最后的element-wise addition替换为channel concatenation,增加输出维度且不会带来太多的计算量。
Shuffle unit的计算是比较高效的,对于$c\times h\times w$的输入,bottleneck的中间维度为$m$,ResNet unit的计算量为$hw(2cm + 9m^2)$FLOPs,ResNeXt unit的计算量为$hw(2cm+9m^2/g)$FLOPs,ShuffleNet unit的计算量为$hw(2cm/g + 9m)$,$g$为卷积的分组数。在同等计算资源情况下,计算量的减少意味着ShuffeNet可以使用维度更多的特征图,这在小网络中十分重要。
需要注意的是,尽管深度卷积通常有较低的理论复杂度,但在实现时的效率是不高的。为此,ShuffleNet仅对bottleneck中的特征(维度较低)使用深度卷积。
Network Architecture
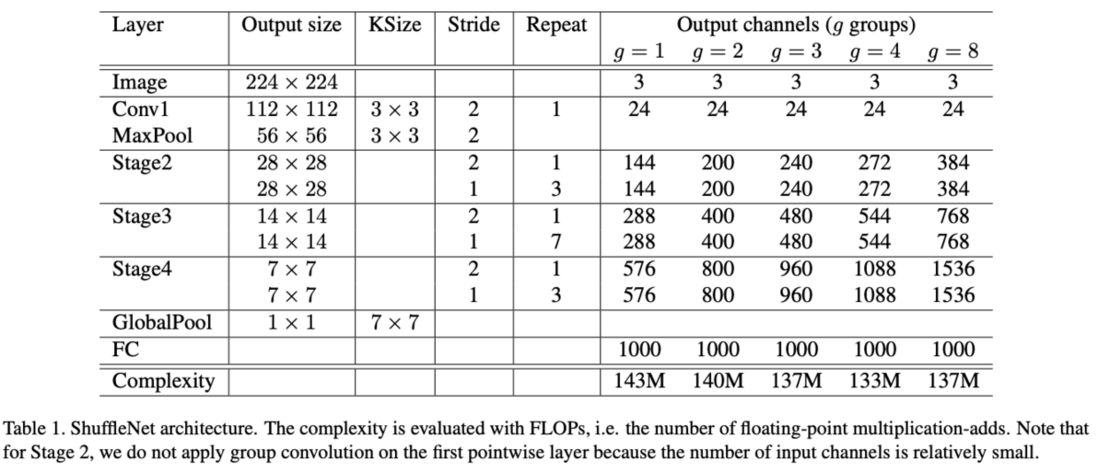
ShuffleNet的结构如表1所示,3个不同的stage由ShuffleNet unit堆叠而成,每个stage的首个ShuffleNet unit比较特殊,使用图2c的stride=2结构,特征图大小缩小一倍,channel数增大一倍。其它的ShuffleNet unit使用图2b的结构,bootlneck的维度设定为输出的$1/4$。表1中设计不同分组数的网络,并修改了对应的输出维度,模型大小整体保持在140MFLOPs左右,网络的分组数越大,可设置维度也越大。
Experiments
为了设定不同的网络复杂度,对表1的网络层维度加一个缩放因子$s$,比如ShuffleNet 0.5X为表1的所有层输出维度减少一倍。

对不同scale和分组数的性能。

对比channel shuffle对不同网络大小作用。

在保持复杂度的情况下,将stage2-4尽量替换成类似于其它主流网络结构(具体设计看原文),进行性能对比。
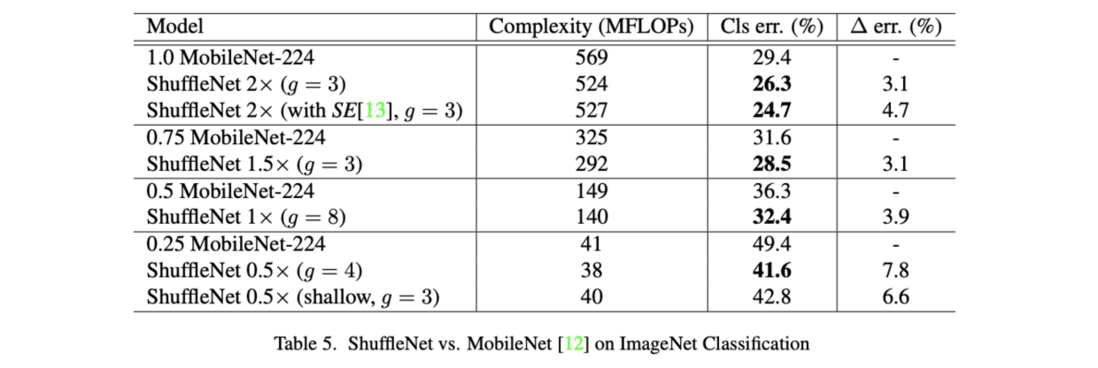
对比同复杂度的MobileNet性能。

对比主流网络的性能。

对比作为目标检测主干的性能。

CPU单线程推理速度对比。
Conclusion
ShuffleNet的核心在于使用channel shuffle操作弥补分组间的信息交流,使得网络可以尽情使用pointwise分组卷积,不仅可以减少主要的网络计算量,也可以增加卷积的维度,从实验来看,是个很不错的work。
ShuffleNet V2
**论文: ShuffleNet V2: Practical Guidelines for Efficient
CNN Architecture Design**

- 论文地址:https://arxiv.org/pdf/1807.11164.pdf
- 论文代码:https://github.com/megvii-model/ShuffleNet-Series/tree/master/ShuffleNetV2
Introduction
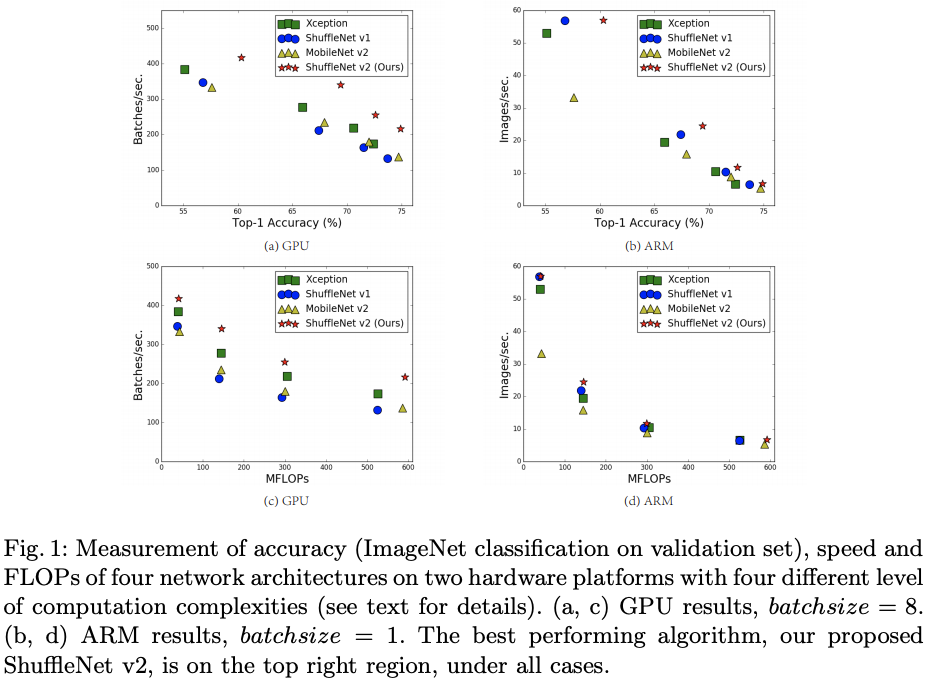
论文发现,作为衡量计算复杂度的指标,FLOPs实际并不等同于速度。如图1所示,FLOPs相似的网络,其速度却有较大的差别,只用FLOPs作为衡量计算复杂度的指标是不够的,还要考虑内存访问消耗以及GPU并行。基于上面的发现,论文从理论到实验列举了轻量级网络设计的5个要领,然后再根据设计要领提出ShuffleNet V2。
Practical Guidelines for Efficient Network Design
为了保证结果的正确性,论文在以下工业设备中进行理论的相关测试:
- GPU. A single NVIDIA GeForce GTX 1080Ti is used. The convolution library is CUDNN 7.0
- ARM. A Qualcomm Snapdragon 810.
包含以下5个轻量级网络设计要领:
G1: Equal channel width minimizes memory access cost (MAC).
主流的网络大都使用深度分离卷积,其中pointwise卷积承担了大部分的计算开销。假设输入维度$c_1$和输出维度$c_2$,特征图大小为$h$和$w$,则$1\times 1$的卷积核的计算量$B=hwc_1 c_2$,内存访问消耗$MAC=hw(c_1+c_2)+c_1 c_2$,MAC可以表示为B相关的公式:
$MAC=hw(c_1+c_2)+c_1 c_2 \ge hw\sqrt{c_1 c_2} + c_1 c_2=\sqrt{hwB} + \frac{B}{hw}$
上式在$c_1$和$c_2$相等时取得最小值,即输入输出维度相等时,内存访问消耗最小。
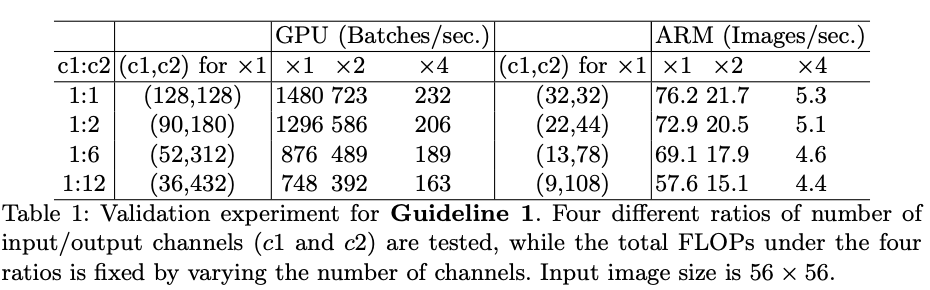
为了避免理论与实际不符,论文在实际设备上进行了对比,在保持FLOPs不变的情况下,调整输入输出维度的比例,可以看到1:1的情况下计算速度最快。因此,在设计结构时尽量保持卷积的输入输出的维度一致。
G2: Excessive group convolution increases MAC
分组卷积能够降低FLOPs,在固定的FLOPs情况下,分组卷积能够使用更多的channel数,但channel的增加会带来MAC的提高,$1\times 1$分组卷积的MAC与FLOPs的关系为

$g$为分组数,$B=hwc_1 c_2/g$为FLOPs。在固定输入和计算量情况下,MAC随着$g$增加而增加。
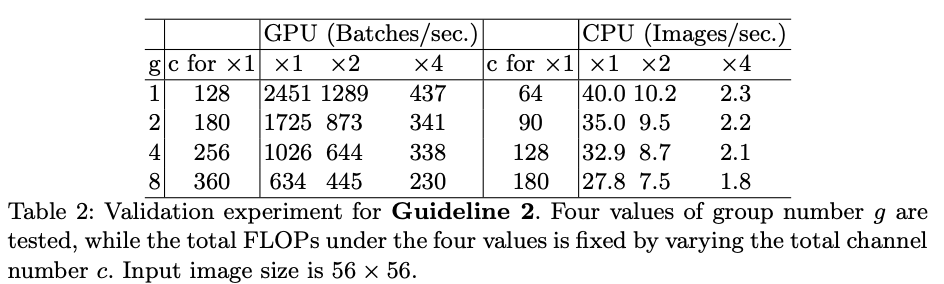
论文同样也在实际设备上进行了对比,使用更多的分组反而降低了推理的速度,主要由于MAC的增加。因此,需要谨慎地根据平台和任务选择分组数,选择大的分组数能带来一定程度的准确率提升,但也会导致计算消耗的快速提升。
G3: Network fragmentation reduces degree of parallelism
目前一些网络在单个block中使用了多通过,比如NASNET-A在单个block中使用了13个分支,而常规的网络仅使用2-3个分支。尽管这样的设计能够提升准确率,但是对设备并行计算不友好,会带来性能的下降。


在实际设备上进行对比,在固定FLOPs情况下,分别对比串行和并行分支结构的性能。从结果来看,单分支的结构性能最好,性能的下降在GPU设备上最为明显。
G4: Element-wise operations are non-negligible
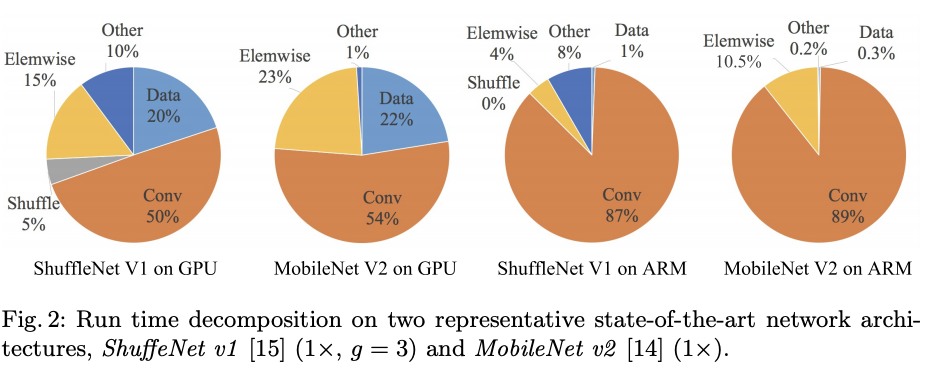
论文对ShuffleNetV1和MobileNetV2的耗时进行了分析,发现element-wise操作(ReLU, AddTensor, AddBias, etc)的消耗是不可忽视的,特别在GPU设备上。尽管这些操作FLOPs不高,但其MAC相对较高。

在实际设备对比中,固定FLOPs的情况下,使用更多的element-wise操作会导致网络的性能下降。
最后总结下论文发现的网络设计要领:
- 使用相同输入输出维度的卷积
- 了解分组卷积带来的损耗
- 减少分支的数量
- 减少element-wise操作
ShuffleNet V2: an Efficient Architecture
如上面提到的,ShuffleNetV1的pointwise分组卷积以及bottleneck结果均会提高MAC,导致不可忽视的计算损耗。为了达到高性能以及高准确率,关键是在不通过稠密卷积以及过多分组的情况下,获得输入输出一样的大维度卷积。

ShuffeNetV1的unit结构如图3ab所示,为了达到上面的目的,V1的基础上加入channel split操作,如图3c所示。在每个unit的开头,将特征图分为$c-c^{'}$以及$c^{'}$两部分。根据G3,一个分支直接往后传递。根据G1,另一个分支包含3个输入输出维度一样的卷积。根据G2,不再使用分组卷积,而且unit的开头已经相当于进行了分组卷积。在完成卷积操作后,将特征concate,恢复到unit的输入大小(符合G1),然后进行channel shuffle操作。这里没有了element-wise adddition操作,符合了G4,在实现的时候将concat/channel shuffle/channel split合在一起做了,能够进一步提升性能。
空间下采样的操作进行了少量的修改,如图3d所示,去掉了channel split操作,因此输出的维度会翻倍。

类似于ShuffleNetV1,设定$c^{'}=c/2$stage2-4为堆叠ShuffleNet unit的结构,在全局池化前加了一个$1\times 1$卷积来帮助特征融合。ShuffleNetV2不仅速度快,准确率也不低,主要得益于两个方面,首先是模型性能高,使得可以使用更大的维度以及网络容量,其次是channel split可以使得部分特征直接穿过block,相当于DenseNet的特征重用。
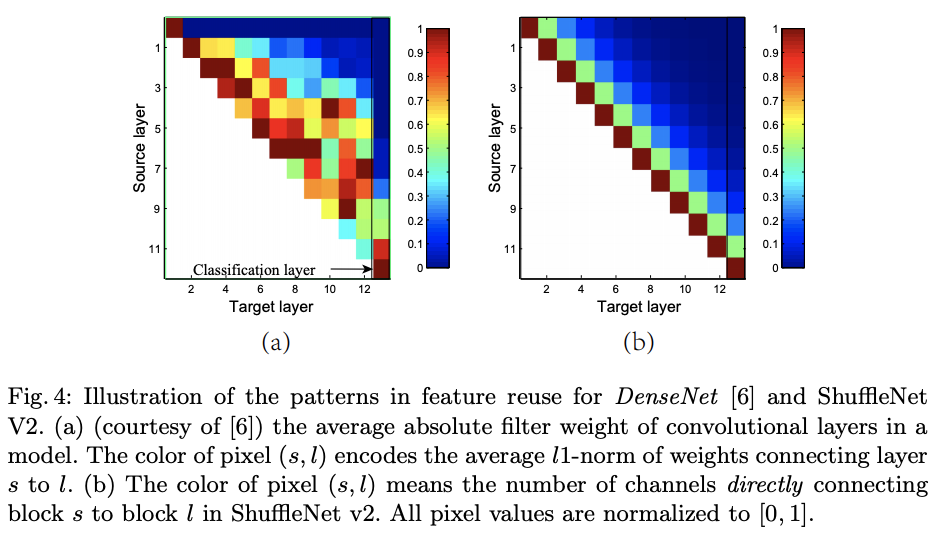
论文对DenseNet以及ShuffleNetV2的特征重用程度进行了可视化对比,在DenseNet中,相邻层的连接比其它层更强,意味着所有层的稠密连接存在冗余。而在ShuffleNet中,层间的影响力以$(1-c^{'})/c=0.5$的倍数进行衰减,与DenseNet有一定的相似性。
Experiment

将ShuffleNetV2 unit应用到大网络中进行对比。

对比ShuffleNetV2作为检测网络主干的性能。
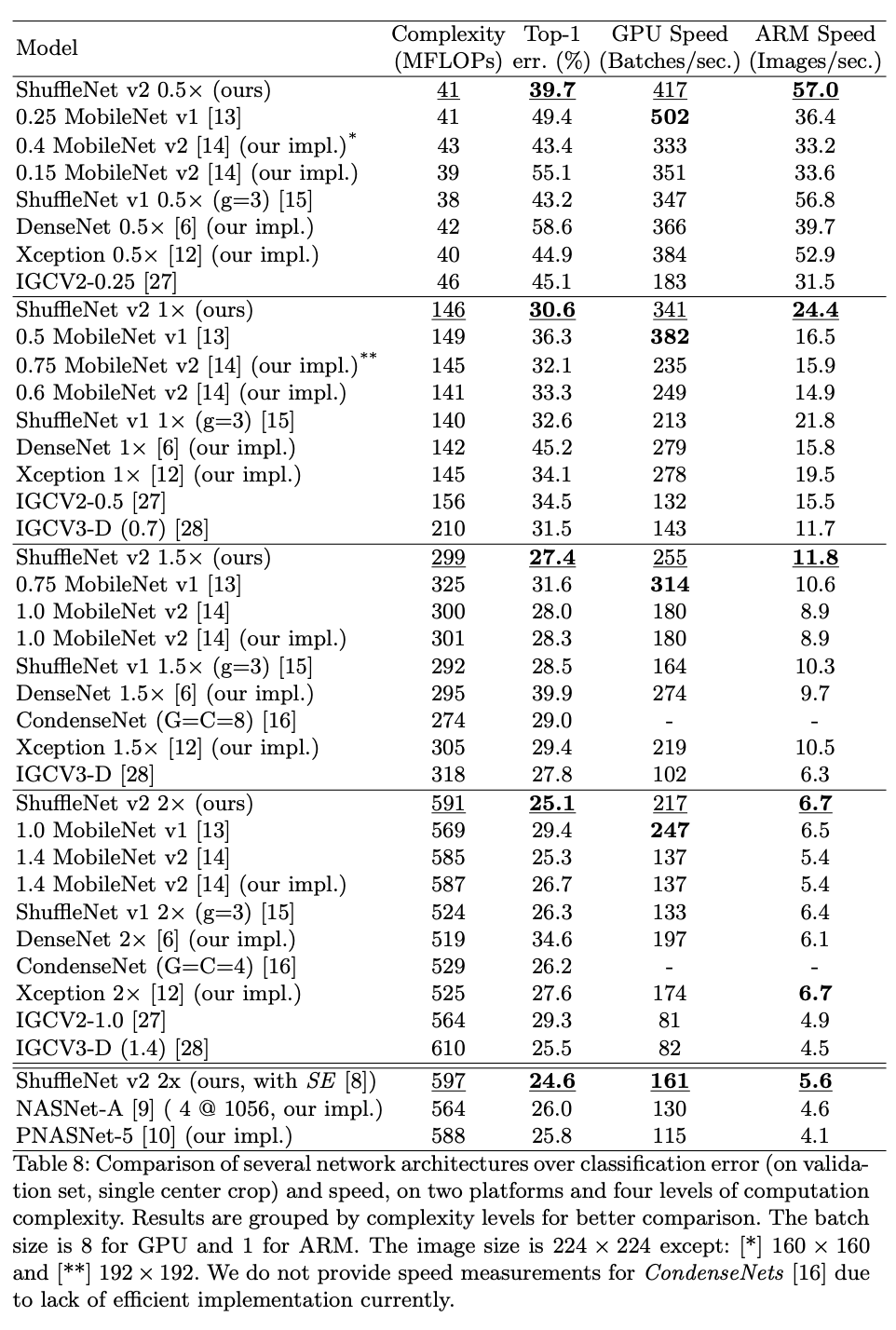
与不同大小的主流分类网络进行性能对比。
Conclusion
论文从实践出发,以实际的推理速度为指导,总结出了5条轻量级网络的设计要领,并根据要领提出了ShuffleNetV2,很好地兼顾了准确率和速度,其中channel split操作十分亮眼,达到了类似DenseNet的特征重用效果。
CONCLUSION
ShuffleNet系列是轻量级网络中很重要的一个系列,ShuffleNetV1提出了channel shuffle操作,使得网络可以尽情地使用分组卷积来加速,而ShuffleNetV2则推倒V1的大部分设计,从实际出发,提出channel split操作,在加速网络的同时进行了特征重用,达到了很好的效果 。
如果本文对你有帮助,麻烦点个赞或在看呗~
更多内容请关注 微信公众号【晓飞的算法工程笔记】















