在我们使用代理ip时,如何使爬虫更有效的进行,在爬虫采集数据信息需要注意哪些地方,我们一起来分析如何更有效的采集到数据信息,提高工作效率。
分析目标网站数据模块
当我们确定要爬取的网站时,一定不是立刻去敲代码,应该先分析目标网站的数据模块,以电商类网站举例,包括商品、价格、评价、销量、促销活动等信息;还有信息综合类网站,有体育新闻、科技新闻、娱乐新闻等,而且每一个版块下面可能还有二级分类,三级分类。
分析目标网站反网络爬虫策略
正常发出去的http请求到目标网站,返回的200状态,表明请求合法被接受,并且能够看到返回的数据。要是触发了目标网站的反爬策略,那就会把当前ip列入到异常黑名单,再也不可以正常浏览了。所以如何分析目标网站的反网络爬虫策略呢,只能不断的去尝试,比如一个ip访问多少次会触发,短时间访问多少次会触发,还有一些其他方面的限制,比如验证码、cookies等等。通过不断尝试,逐渐了然于心。
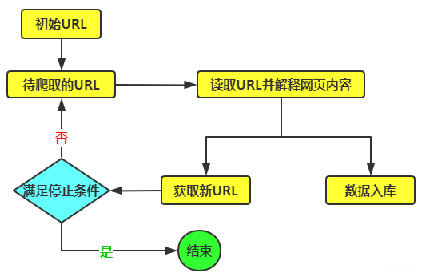
编写demo,分析网站结构
先模拟http请求目标网页,看下网站响应的数据内容大概的形式,正常浏览的时候是能获取目录数据和进入目录的具体链接,然后根据链接抓取获得每一个模块的具体数据包。
数据分析,代理ip池要求
我们通过需要获取多少数据,能够大概了解需要访问多少网页;通过目标网站的反爬策略,能大概知道需要多少代理ip,需要多大的代理ip池。假设要访问100万个页面,每个ip能访问100个页面后会触发反爬机制,那大概需要1万左右不重复的代理ip;假设每次爬取一个页面需要10秒,加上抓取频率控制5秒,100个页面需要1500秒,可以得出单个ip的使用时间大概需要30分钟左右,当然,这只是个大概的数字,也不一定准确,毕竟目标网站的响应时间不是固定的,频率控制也是随机的,而且在抓取过程中也会有其他状况发生。