
前言
测试团队在执行自动化或者黑盒测试时,希望同时获取代码的覆盖率,测研团队由此开发了第一代自动化覆盖率平台。随着业务迭代,存量代码越来越多,使用过程中遇到了很多新的问题,例如:
- 无法统计增量代码覆盖率,以便量化测试完整度
- 不支持合并覆盖率报告,多人多环境协作测试时无法获得完整统计数据
- 报告手动生成,以及生成报告的必要信息也需要人肉收集,系统间自动化程度低,用户使用效率低
针对上述的问题,测试研发团队开发了覆盖率平台2.0版本,实现了增量代码覆盖率,包括定时采样,自动合并报告等功能,以赋能团队精准测试能力。
方案设计
增量代码覆盖率基于Jacoco实现,Jacoco是基于JVM虚拟机的使用最广的第三方代码覆盖率开源工具。我们的设计主要针对JacocoCore模块,Analyze模块进行功能扩展,在数据分析中加入增量行计数逻辑,以实现增量覆盖率统计。出于体系建设考虑,我们集成增量覆盖率功能到DevOps发布流程,完善了质量量化和风险约束能力,设计方案如下: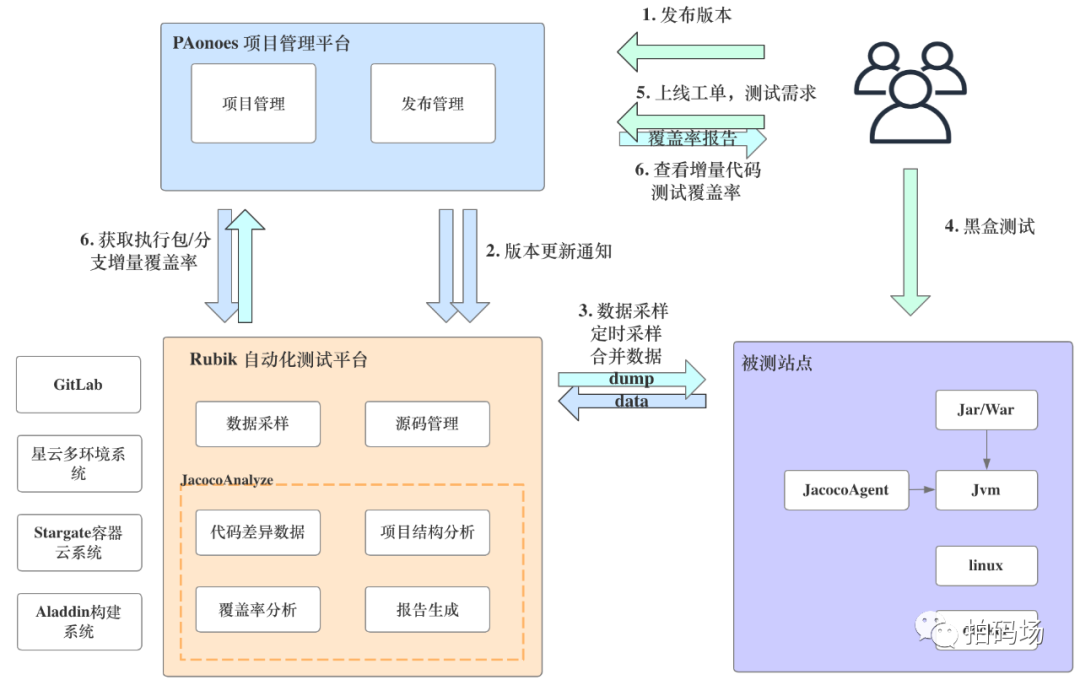
增量覆盖率实现方案
Rubik自动化平台会根据发布系统推送的发布事件自动触发定时采样,数据合并,另外项目管理系统按一定规则读取统计数据,并且会对覆盖率未达标的发布流程进行卡点约束。
主要功能说明
CodeDiff数据解析
增量行数据是计算增量覆盖率的前提,Rubik平台通过发布系统获得被测站点的包版本与生产包版本,调用GitLabApi获取差异代码数据,差异代码数据为纯字符串格式,解析转换为差异行数据,转换逻辑如下:
/// / 解析GitDiff数据 / @param diff 代码差异生数据 / @return 增量行数组 // public static int[] parseIncrLines(String diff) { GitDiffHelper helper = new GitDiffHelper(diff); helper.parse(); return helper.newLines; } private void parse(){ if (diff == null || diff.length() == 0) { return; } // 跳过文件信息 nextLineIfMinusFile(); nextLineIfPlusFile(); while (!eof()) { // 解析差异行数据块 parseBlock(); } }
采样数据分析
Jacoco通过各个维度的计数器逐层累加实现,分别为:
- 指令计数器(CounterImpl)
- 行计数器(LineImpl)
- 方法计算节点(MethodCoverageImpl)
- 类计算节点(ClassCoverageImpl)
- Package计算节点(PackageCoverageImpl)
- Module计算节点(BundleCoverageImpl)
- 站点计算节点(Jacoco未提供,可自行实现)
通过从底层指令计数器开始逐层累加,最终得到站点级统计信息。为实现增量行统计,我们将增量行与全量行分开,在计算节点父类中(CoverageNodeImpl)中增加了增量行计数器。
public class CoverageNodeImpl implements ICoverageNode{ ... /// / 全量行计数器 // protected CounterImpl lineCounter; /// / 增量行计数器 // protected CounterImpl diffLineCounter; ...
在原计数逻辑中加入增量行计数逻辑,如下:
public class SourceNodeImpl extends CoverageNodeImpl implements ISourceNode{ private LineImpl[] lines; // 由GitDiff计算得到的差异行数据 private int[] diffLines; ... // 由行内指令计数器累加行计数器 private void incrementLine(final ICounter instructions, final ICounter branches, final int line){ ensureCapacity(line, line); final LineImpl l = getLine(line); final int oldTotal = l.getInstructionCounter().getTotalCount(); final int oldCovered = l.getInstructionCounter().getCoveredCount(); boolean isDiffLine; if (l == LineImpl.EMPTY) { // 确定是否为增量行 isDiffLine = diffLines != null && Arrays.binarySearch(diffLines, line) >= 0; } else { isDiffLine = l.isDiffLine(); } lines[line - offset] = l.increment(instructions, branches, isDiffLine); // Increment line counter: if (instructions.getTotalCount() > 0) { if (instructions.getCoveredCount() == 0) { if (oldTotal == 0) { lineCounter = lineCounter.increment(CounterImpl.COUNTER_1_0); // 增量行处理逻辑:处理已覆盖行 if (isDiffLine) { diffLineCounter = diffLineCounter.increment(CounterImpl.COUNTER_1_0); } } } else { if (oldTotal == 0) { lineCounter = lineCounter.increment(CounterImpl.COUNTER_0_1); // 增量行处理逻辑:处理未覆盖行 if (isDiffLine) { diffLineCounter = diffLineCounter.increment(CounterImpl.COUNTER_0_1); } } else { if (oldCovered == 0) { lineCounter = lineCounter.increment(-1, +1); // 增量行处理逻辑:处理部分覆盖行 if (isDiffLine) { diffLineCounter = diffLineCounter.increment(-1, +1); } } } } } }
另外行计数器中Jacoco通过四维数组单例,用固定数量的对象表示8^4(4096)种计数情况,实现了计数缓存,以提高内存使用率,这里增加了增量行标志位以区别全量行计数器,但是Jacoco自身的缓存计数器(Fix类)无法适配增量的情况,所以这里也同样增加了增量行缓存计数器,即DiffFix类,这里会带来固定的4096个DiffFix对象的额外开销,但是对整体性能影响几乎可以忽略。
public abstract class LineImpl implements ILine{ ... private final boolean isDiffLine; private static final LineImpl[][][][] SINGLETONS = new LineImpl[SINGLETON_INS_LIMIT + 1][][][]; private static final LineImpl[][][][] DIFF_SINGLETONS = new LineImpl[SINGLETON_INS_LIMIT + 1][][][]; static { // 全量行计数缓存 for (int i = 0; i <= SINGLETON_INS_LIMIT; i++) { SINGLETONS[i] = new LineImpl[SINGLETON_INS_LIMIT + 1][][]; for (int j = 0; j <= SINGLETON_INS_LIMIT; j++) { SINGLETONSi = new LineImpl[SINGLETON_BRA_LIMIT + 1][]; for (int k = 0; k <= SINGLETON_BRA_LIMIT; k++) { SINGLETONSi[k] = new LineImpl[SINGLETON_BRA_LIMIT + 1]; for (int l = 0; l <= SINGLETON_BRA_LIMIT; l++) { SINGLETONSik = new Fix(i, j, k, l); } } } } // 增量行计数缓存 for (int i = 0; i <= SINGLETON_INS_LIMIT; i++) { DIFF_SINGLETONS[i] = new LineImpl[SINGLETON_INS_LIMIT + 1][][]; for (int j = 0; j <= SINGLETON_INS_LIMIT; j++) { DIFF_SINGLETONSi = new LineImpl[SINGLETON_BRA_LIMIT + 1][]; for (int k = 0; k <= SINGLETON_BRA_LIMIT; k++) { DIFF_SINGLETONSi[k] = new LineImpl[SINGLETON_BRA_LIMIT + 1]; for (int l = 0; l <= SINGLETON_BRA_LIMIT; l++) { DIFF_SINGLETONSik = new DiffFix(i, j, k, l); } } } } }
覆盖率报告
出于对可读性的要求,我们没有采用Jacoco原生的Html报告,而是独立开发了相对更为简洁的增量/全量报告,如下: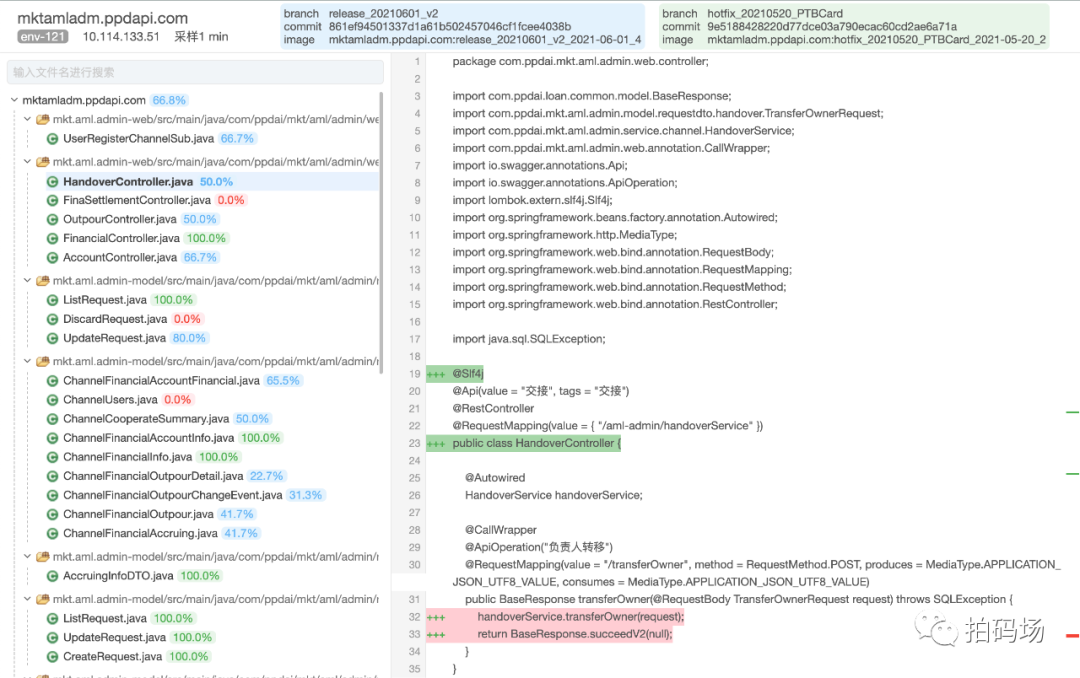
全环境覆盖率报告如下:
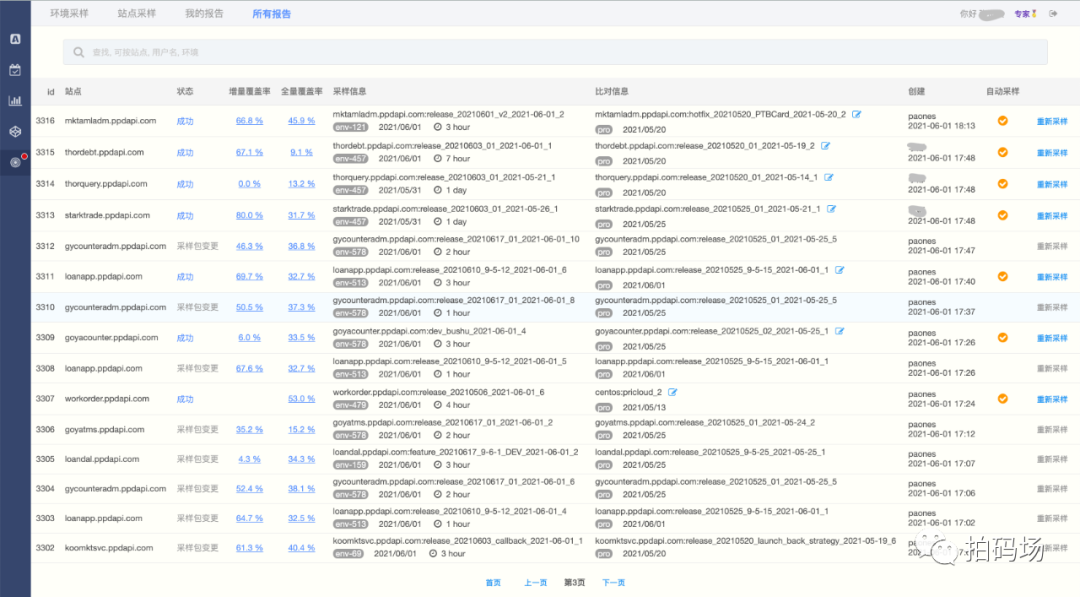
数据合并
测试过程往往经过多次发布,可能因为分批提测,也可能因为修复缺陷,每次JVM启动后需要将之前的采样数据合并到下一次采样数据中继续累加,Rubik平台接收发布事件并按以下规则自动合并:
- 站点发布新版本前进行最后一次采样
- 站点发布新版本中,健康检查通过后立即进行一次采样,并且同时开启定时采样
- 任意一次采样都将进行向前自动合并数据,向前查找规则为:同一站点,同一环境,同一代码分支的最近一次采样数据
虽然可以在PAones项目管理平台的发布工单中查看站点覆盖率报告,但想实时查看站点的增量覆盖情况,用户可登录Rubik平台,指定自己的测试环境,就可以方便的看到被测环境内所有站点的增量覆盖率(按每小时定时采样,也可手动触发实时采样),从而相对精准的控制测试进度,减少漏测问题。效果如下图。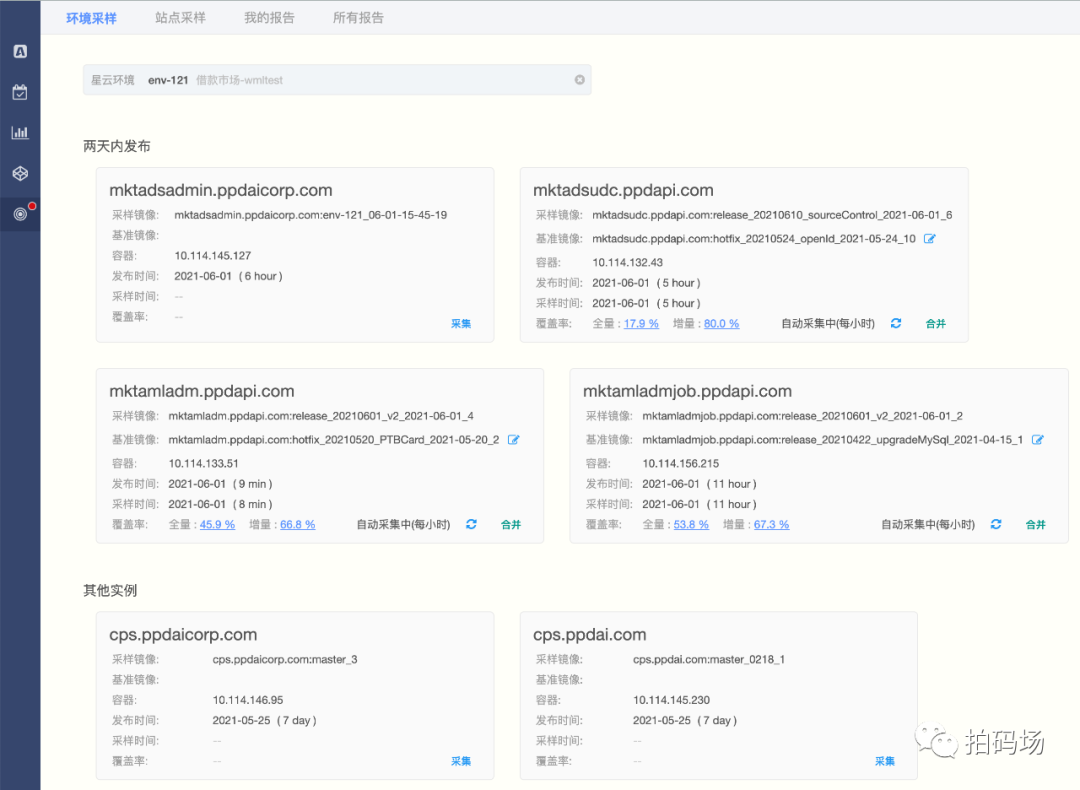
项目实施中遇到的问题
数据合并问题
现象
覆盖率平台平均每天需要对400+个站点提供分析服务,另外算上每小时定时采样,一天完成超过8000次采样分析以及报告生成,在上线运行一段时间后发现,偶尔会出现服务响应慢或卡顿,甚至不可用现象。
分析
针对异常时内存分析发现,主要堆积的对象是SessionInfoStore。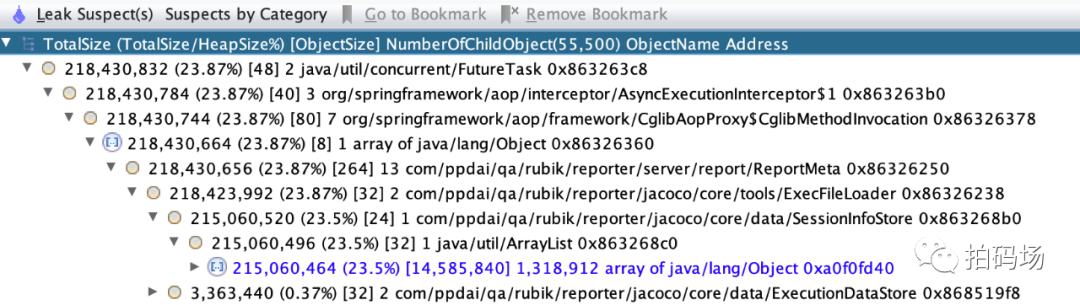
SessionInfoStore是Jacoco用来进行代码分析展示的底层类,包含所有的执行类信息,在自动合并过程中Jacoco默认对SessionInfo进行了累加而非合并,导致每进行一次合并采样文件数据量都会增加30%到50%,随着不断对采样数据合并,加载文件所消耗内存急剧增加,直到并发加载几个文件就导致内存耗尽,频繁触发GC,通过复盘发现,一份采样文件由最初的10K到问题出现时可以扩大到800M到1.5G。
优化方案
通过调查发现SessionInfo只在原生Html报告中需要使用,去掉后不影响自研报告展示,也不会破坏Jacoco分析数据流程,于是优(cu)雅(bao)的将合并数据中的对应逻辑直接去除,最终解决了这个问题,修改代码如下:
/// / Deserialization of execution data from binary streams. // public class ExecutionDataReader{ ... // Rubik报告无需合并SessionInfo private void readSessionInfo() throws IOException{ // if (sessionInfoVisitor == null) { // throw new IOException("No session info visitor."); // } // final String id = in.readUTF(); // final long start = in.readLong(); // final long dump = in.readLong(); // sessionInfoVisitor.visitSessionInfo(new SessionInfo(id, start, dump)); } // 合并采样数据 private void readExecutionData() throws IOException{ if (executionDataVisitor == null) { throw new IOException("No execution data visitor."); } final long id = in.readLong(); final String name = in.readUTF(); final boolean[] probes = in.readBooleanArray(); executionDataVisitor.visitClassExecution(new ExecutionData(id, name, probes)); }
后续规划
增量覆盖率为测试结果量化提供了能力支撑,一定程度上解决了测试结果的信任问题,也为测试团队质量分提供了基础能力,帮助信也研发中心在Devops体系化建设上又推进了一步。接下来效能研发团队还将在精准测试方向上进行更多尝试,包括自动回归范围分析,代码调用链路等,欢迎大家继续关注。









