
慢查询日志,将那些执行时间过长且占用资源过多的SQL拿来进行explain分析,导致CPU过高,多数是GroupBy、OrderBy排序问题所导致,然后慢慢进行优化改进。比如优化insert语句、优化group by语句、优化order by语句、优化join语句等等;
3)考虑定时优化文件及索引;
4)定期分析表,使用optimize table;
5)优化数据库对象;
6)考虑是否是锁问题;
7)调整一些MySQL Server参数,比如key_buffer_size、table_cache、innodb_buffer_pool_size、innodb_log_file_size等等;
8)如果数据量过大,可以考虑使用MySQL集群或者搭建高可用环境。
9)可能由于内存latch(泄露)导致数据库CPU高
10)在多用户高并发的情况下,任何系统都会hold不住的,所以,使用缓存是必须的,使用memcached或者redis缓存都可以;
11)看看tmp_table_size大小是否偏小,如果允许,适当的增大一点;
12)如果max_heap_table_size配置的过小,增大一点;
13)mysql的sql语句睡眠连接超时时间设置问题(wait_timeout)
14)使用show processlist查看mysql连接数,看看是否超过了mysql设置的连接数(http://www.cnblogs.com/kevingrace/p/6226324.html)
下面分享一例遇到过的案例:
网站在高峰时段访问,点击页面有点卡。登陆服务器,发现机器负载有点高,并且mysql占用了很高的CPU资源,如下图:
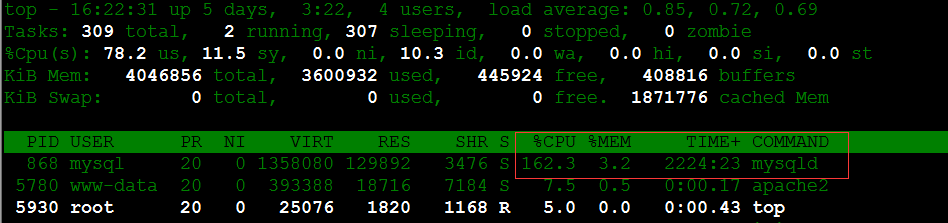
MySQL负载居高不下,如果打开了慢查询日志功能,最好的办法就是针对慢查询日志里执行慢的sql语句进行优化,如果sql语句用了大量的group by等语句,union联合查询等肯定会将mysql的占用率提高。所以就需要优化sql语句
除了优化sql语句外,也可以做一些配置上的优化。在mysql中运行show proceslist;出现下面回显结果:
1.查询有大量的Copying to tmp table on disk状态
明显是由于临时表过大导致mysql将临时表写入硬盘影响了整体性能。
Mysql中tmp_table_size的默认值仅为16MB,在当前的情况下显然是不够用的。
mysql> show variables like "%tmp%";
+-------------------+----------+
| Variable_name | Value |
+-------------------+----------+
| max_tmp_tables | 32 |
| slave_load_tmpdir | /tmp |
| tmp_table_size | 16777216 |
| tmpdir | /tmp |
+-------------------+----------+
4 rows in set (0.00 sec)
解决办法:调整临时表大小
1)进mysql终端命令修改,加上global,下次进mysql就会生效
mysql> set global tmp_table_size=33554432;
Query OK, 0 rows affected (0.00 sec)
再次登陆mysql
mysql> show variables like "%tmp%";
+-------------------+----------+
| Variable_name | Value |
+-------------------+----------+
| max_tmp_tables | 32 |
| slave_load_tmpdir | /tmp |
| tmp_table_size | 33554432 |
| tmpdir | /tmp |
+-------------------+----------+
4 rows in set (0.01 sec)
2)my.cnf配置文件修改
[root@www ~]# vim my.cnf
.....
tmp_table_size = 32M
重启mysql
[root@www ~]# /etc/init.d/mysqld restart
2.show processlist;命令的输出结果显示了有哪些线程在运行,可以帮助识别出有问题的查询语句。比如下面结果:
Id User Host db Command Time State Info
207 root 192.168.1.25:51718 mytest Sleep 5 NULL
先简单说一下各列的含义和用途,第一列,id,不用说了吧,一个标识,你要kill一个语句的时候很有用。user列,显示单前用户,如果不是root,这个命令就只显示你权限范围内的sql语句。host列,显示这个语句是从哪个ip的哪个端口上发出的。呵呵,可以用来追踪出问题语句的用户。db列,显示这个进程目前连接的是哪个数据库 。command列,显示当前连接的执行的命令,一般就是休眠(sleep),查询(query),连接(connect)。time列,此这个状态持续的时间,单位是秒。state列,显示使用当前连接的sql语句的状态,很重要的列,后续会有所有的状态的描述,请注意,state只是语句执行中的某一个状态,一个sql语句,已查询为例,可能需要经过copying to tmp table,Sorting result,Sending data等状态才可以完成,info列,显示这个sql语句,因为长度有限,所以长的sql语句就显示不全,但是一个判断问题语句的重要依据。
常见问题:
一般是睡眠连接过多,严重消耗mysql服务器资源(主要是cpu, 内存),并可能导致mysql崩溃。
解决办法 :
在mysql的配置my.cnf文件中,有一项wait_timeout参数设置.即可设置睡眠连接超时秒数,如果某个连接超时,会被mysql自然终止。
wait_timeout过大有弊端,其体现就是MySQL里大量的SLEEP进程无法及时释放,拖累系统性能,不过也不能把这个指设置的过小,否则你可能会遭遇到“MySQL has gone away”之类的问题。
通常来说,把wait_timeout设置为10小时是个不错的选择,但某些情况下可能也会出问题,比如说有一个CRON脚本,其中两次SQL查询的间隔时间大于10秒的话,那么这个设置就有问题了(当然,这也不是不能解决的问题,你可以在程序里时不时mysql_ping一下,以便服务器知道你还活着,重新计算wait_timeout时间):
MySQL服务器默认的“wait_timeout”是28800秒即8小时,意味着如果一个连接的空闲时间超过8个小时,MySQL将自动断开该连接。
然而连接池却认为该连接还是有效的(因为并未校验连接的有效性),当应用申请使用该连接时,就会导致下面的报错:
The last packet successfully received from the server was 596,688 milliseconds ago.
mysql> show variables like 'wait_timeout';
+---------------+-------+
| Variable_name | Value |
+---------------+-------+
| wait_timeout | 28800 |
+---------------+-------+
1 row in set (0.00 sec)
28800seconds,也就是8小时。
如果在wait_timeout秒期间内,数据库连接(java.sql.Connection)一直处于等待状态,mysql就将该连接关闭。这时,你的Java应用的连接池仍然合法地持有该连接的引用。当用该连接来进行数据库操作时,就碰到上述错误。
可以将mysql全局变量wait_timeout的缺省值改大。
查看mysql手册,发现对wait_timeout的最大值分别是24天/365天(windows/linux)。
比如将其改成30天
mysql> set global wait_timeout=124800;
Query OK, 0 rows affected (0.00 sec)
***************当你发现自己的才华撑不起野心时,就请安静下来学习吧***************










