
MongoDB——主从复制&副本集 博客分类: java mongodb
前面我说到了,MongoDB数据库支持服务器之间的数据复制。支持主从模式及服务器之间的相互复制。目的当然是实现负载均衡与故障恢复。Mongo中内置了两种技术:主从复制、副本集。下面就简单介绍这两种模式的配置。
一、 主从复制
主从复制是一个简单的数据库同步备份的集群技术。模型如下:
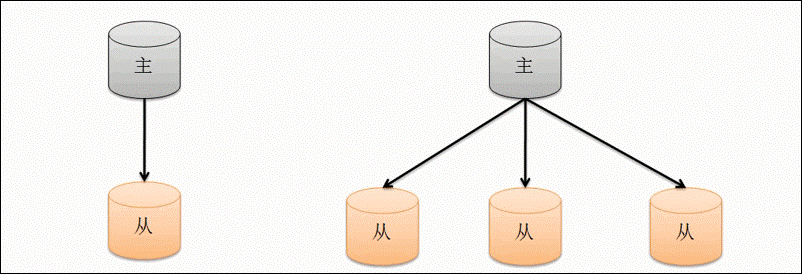
需要注意:
在数据库集群中要明确的知道谁是主服务器,主服务器只有一台。
从服务器要知道自己的数据源,也就是自己的主服务器是谁。
--master用来明确主服务器,--slave和—source来控制从服务器。
实例
配置其实非常简单,类似我们前面讲到的Redis的主从复制,思路如下:
我们现在起两个MongoDB的数据库实例,一个作为Master一个作为Slave,然后从Master存数据,然后看是否能从Slave中取出数据即可。步骤如下:
步骤一:
分别做好Master(用8888端口)和Slave(用7777端口)的服务端与客户端的启动bat文件:
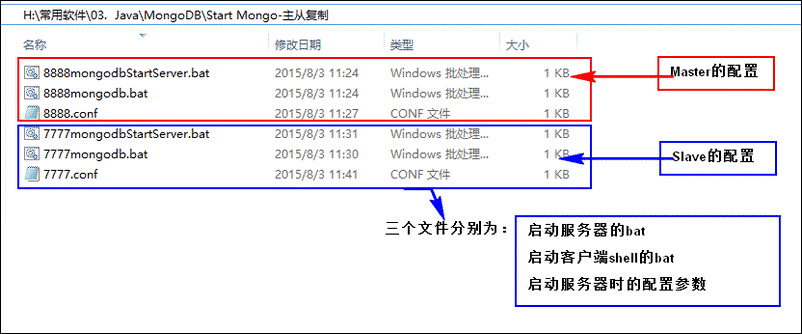
Master的文件内容依次如下:
8888.conf:
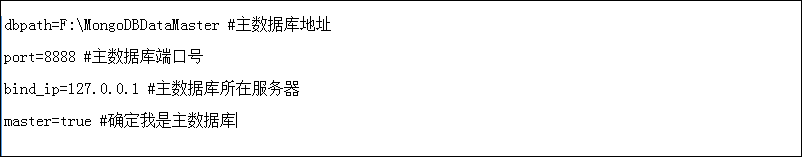
8888mongodbStartServer.bat:

8888mongodb.bat:

Slave的文件内容如下:
7777.conf:

7777mongodbStartServer.bat:

7777mongodb.bat:

步骤二:
双击Master的启动bat文件(8888mongodbStartServer.bat):
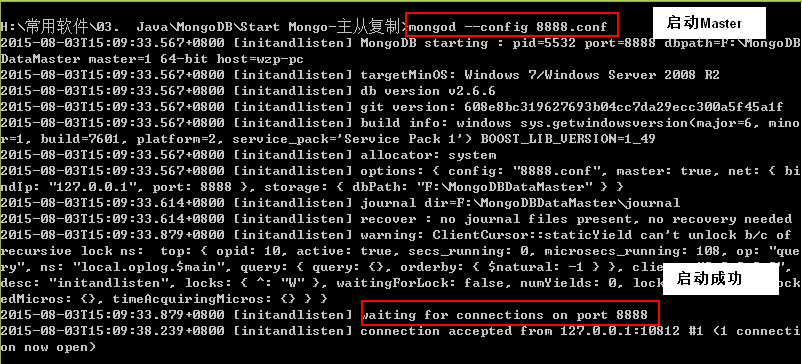
双击Slave的启动bat文件(7777mongodbStartServer.bat):
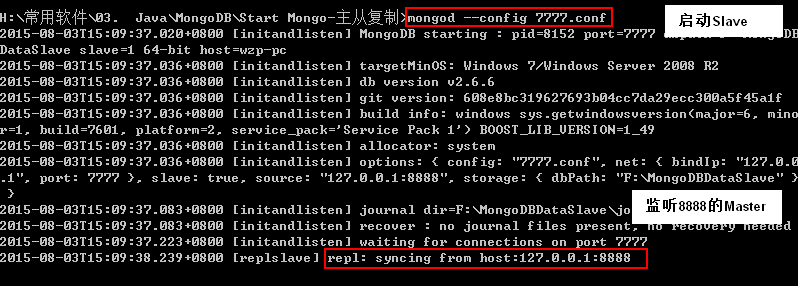
步骤三:
双击Master的客户端启动bat文件(8888mongodb.bat),并新建一个数据库,同时插入数据:
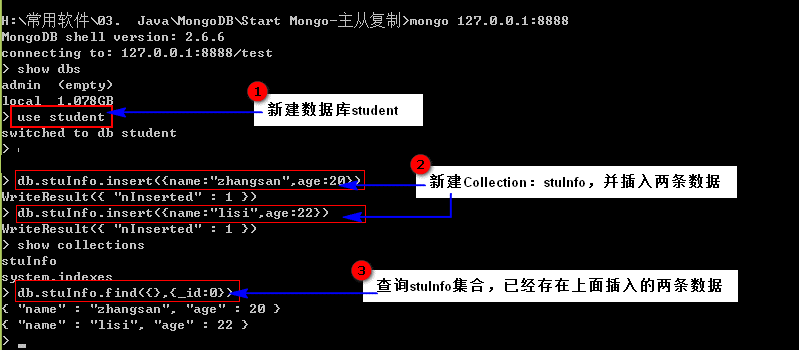
步骤四:
双击Slave的客户端启动bat文件(7777mongodb.bat),并查询是否存在刚刚在Master中新建的数据库、Collection与插入的两条数据:
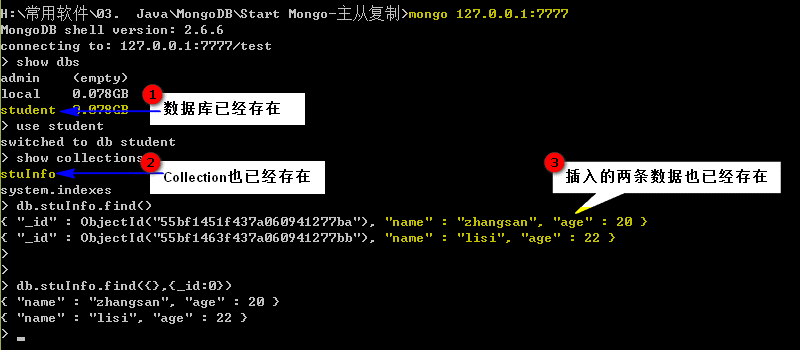
这就说明,主从复制已配置成功。这里还需要注意,Slave数据库实例是不允许我们插入、修改数据的,我们只能操作Master数据库服务器,例如我们在Slave中插入一条数据,会报错:

实例的结构图如下:
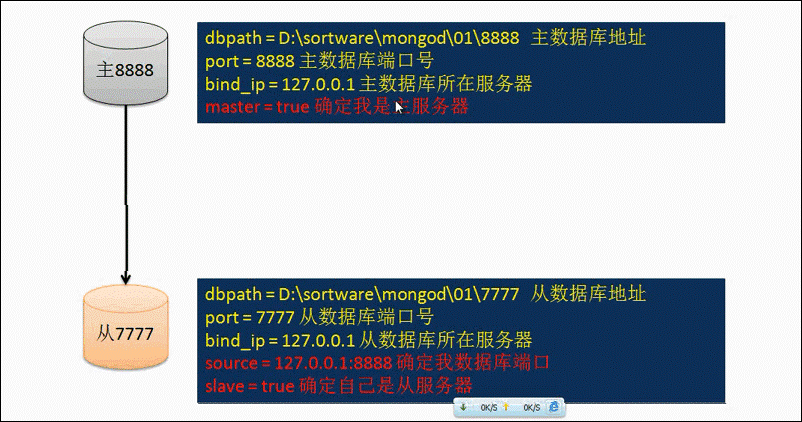
二、 副本集
与主从复制所能达到的效果类似。主从复制模型中的Master相当于副本集中的“活跃”节点;Slave相当于“备份”节点,如下图:
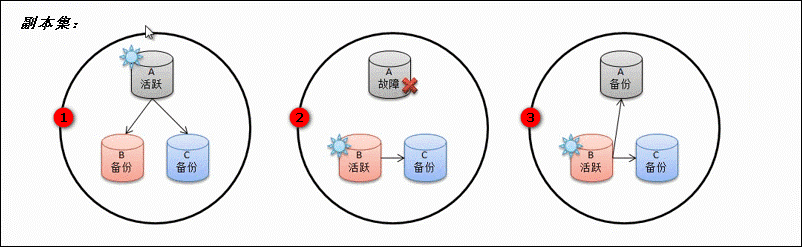
上图1,表明A是活跃的,B、C是用于备份的;图2表示,当A出现故障,这时候集群根据权重算法推选出B为活跃数据库节点;图3表示,当A恢复故障后,它自动变为了备份节点。
与主从复制不同的是,主从复制中只有一个Master,当Master节点挂掉之后,所有的Slave节点无法自动变为Master,继续提供服务。这时所有的 Slave也就会因连不上Master而无法继续备份数据,直到它再次连到Master。
而副本集中所有的节点都可以成为“活跃”节点(一开始是随机推出的),当当前的活跃节点挂掉之后,集群会立即从其它完好的备份节点中推选出一个节点作为“活跃节点”,整个副本集群不会停止备份服务。
配置
配置与主从复制的配置相似,这里不再像上面那么详细的一步步介绍,直接给出大概配置:
准备三套MongoDB的启动配置:(监听不同的端口)
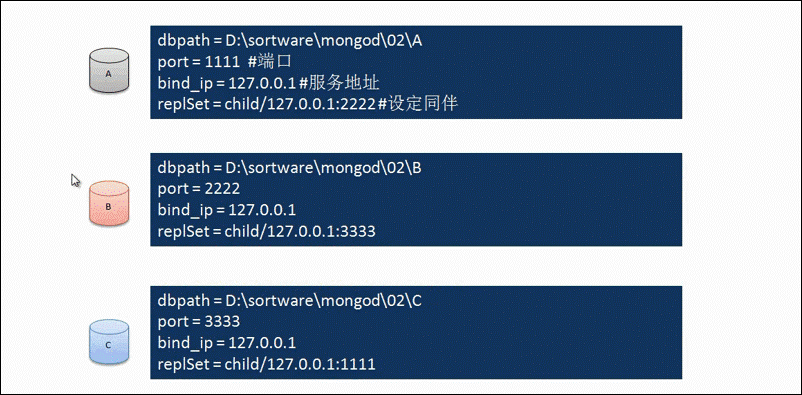
三个启动配置(A/B/C.conf)如下:
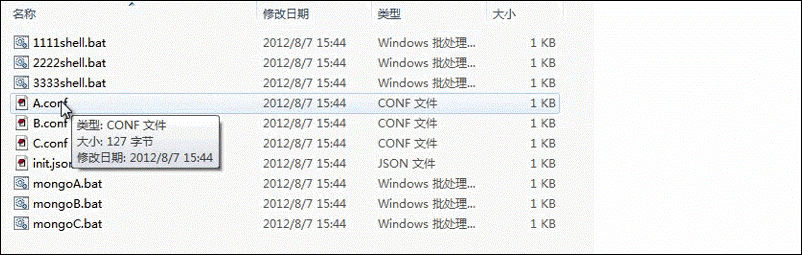
先启动Mongo的三个服务端实例,并初始化副本集:
然后,启动Mongo的客户端实例,启动后可以看出哪个活跃节点,哪些是备份节点:


然后就可以做类似“主从复制”的实例来验证我们是否配置成功。












