
全文链接:http://tecdat.cn/?p=30597
原文出处:拓端数据部落公众号
最近我们被要求解决时间序列异常检验的问题。有客户在使用大量的时间序列。这些时间序列基本上是每10分钟进行一次的网络测量,其中一些是周期性的(即带宽),而另一些则不是(即路由流量)。
他想要一个简单的算法来进行在线“异常值检测”。基本上,想将每个时间序列的整个历史数据保存在内存(或磁盘上),并且想检测实时场景中的任何异常值(每次捕获新样本时)。实现这些结果的最佳方法是什么?
目前正在使用移动平均线来消除一些噪音,但接下来呢?简单的事情,如标准差,...针对整个数据集效果不佳(不能假设时间序列是平稳的),想要更“准确”的东西,理想情况下是黑匣子。我们提出一些方案,例如:
将查找时间序列异常值(并选择性地在图中显示它们)。它将处理季节性和非季节性时间序列。基本思想是找到趋势和季节性成分的可靠估计并减去它们。然后找出残差中的异常值。残差异常值的检验与标准箱线图的检验相同 - 大于或低于上下四分位数的点大于1.5IQR 是假定的异常值。高于/低于这些阈值的 IQR 数量作为异常值“分数”返回。因此,分数可以是任何正数,对于非异常值,分数将为零。
异常值检测取决于数据的性质以及您愿意对它们做出的假设。 通用方法依赖于可靠的统计信息。这种方法的精神是以不受任何异常值影响的方式表征大部分数据,然后指出不符合该特征的任何单个值。
由于这是一个时间序列,因此增加了需要持续(重新)检测异常值的复杂性。如果要在系列展开时执行此操作,那么我们只能使用旧数据进行检测,而不能使用未来的数据。此外,为了防止许多重复测试,我们使用一种误报率非常低的方法。
这些注意事项建议对数据运行简单、可靠的移动窗口异常值测试。有很多可能性,但一种简单、易于理解和易于实现的是基于运行ARIMA:与中位数的中位数绝对偏差。这是数据中变异的强稳健度量,类似于标准差。离群峰将比中位数大几个ARIMA或更多。
读取数据
data1=read.table("正常数据.txt")
data2=read.table("异常数据.txt")
data3=read.table("异常数据第二组.txt")
#查看数据
head(data1)
head(data2)
head(data3)
绘制时间序列图
plot.ts(data1)

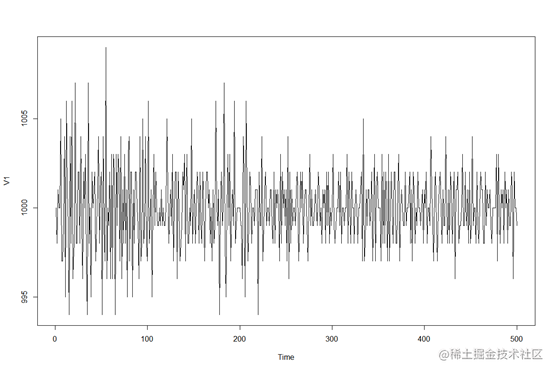
临时变化的离群值
在识别异常值和建议一个合适的ARIMA模型方面做得很好。见下面应用auto.arima。

拟合arima模型,得出最优参数
fit=auto.arima(data1,trace=T)
Fit


得出最优的arima模型p=1 q=1
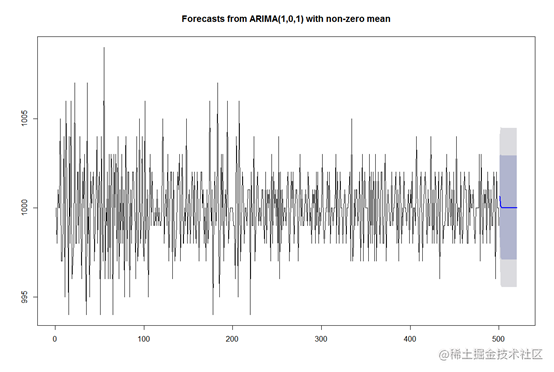
将数据转换成time series格式
使用函数检测异常点 参数比照上面autorima得出的参数p=1 q=1
to(tsmethod = "auto.arima"
,argethod=list( stepwise=FALSE ))
#设置环境参数 时间窗口和异常点范围阈值
window <- 30
threshold <- 3
#求出中位数几倍范围之外的样本点作为异常点
ut <- function(x) {
m = median(x);
median(x) + threshold * median(abs(x - m))
}
#移动时间窗口查看时间序列中的符合条件的时间点
z <- rollaly(zoo(data2))
找出data2中符合条件的时间点作为异常序列
最受欢迎的见解
1.在python中使用lstm和pytorch进行时间序列预测
2.python中利用长短期记忆模型lstm进行时间序列预测分析
3.Python用RNN循环神经网络:LSTM长期记忆、GRU门循环单元、回归和ARIMA对COVID-19新冠疫情新增人数时间序列
4.Python TensorFlow循环神经网络RNN-LSTM神经网络预测股票市场价格时间序列和MSE评估准确性
6.R 语言用RNN循环神经网络 、LSTM长短期记忆网络实现时间序列长期利率预测
7.Matlab创建向量自回归(VAR)模型分析消费者价格指数 (CPI) 和失业率时间序列











