
Spark 构建分类模型
在分类模型中,我们期望根据一组特征来判断类别,这些特征代表了物体、事件或上下文相关的属性(变量)。
二分类

多分类

分类是监督学习的一种形式
我们用带有 类标记 or 类输出 的训练样本训练模型(也就是通过输出结果监督被训练的模型)。
分类模型适用于很多情形,一些常见的例子如下:
预测互联网用户对在线广告的点击概率,这本质上是一个二分类问题(点击或者不点击);
检测欺诈,这同样是一个二分类问题(欺诈或者不是欺诈);
预测拖欠贷款(二分类问题);
对图片、视频或者声音分类(大多情况下是多分类,并且有许多不同的类别);
对新闻、网页或者其他内容标记类别或者打标签(多分类);
发现垃圾邮件、垃圾页面、网络入侵和其他恶意行为(二分类或者多分类);
...
focus on :
MLlib中各种可用的分类模型;
Spark从原始输入数据中抽取合适的特征;
MLlib训练若干分类模型;
用训练好的分类模型做预测;
应用一些标准的评价方法来评估模型的预测性能;
使用第3章中的特征抽取方法来说明如何改进模型性能;
研究参数调优对模型性能的影响,并且学习如何使用交叉验证来选择最优的模型参数。
5.1 分类模型的种类
Spark 分类模型 :
线性模型 - [线性,容易扩展到大数据集]
决策树 - [训练过程计算量大并且较难扩展]
朴素贝叶斯模型 - [模型简单、易训练,并且具有高效和并行的优点]
朴素贝叶斯模型可以作为一个很好的模型测试基准,用于比较其他模型的性能。
MLlib库 提供 线性模型、决策树、朴素贝叶斯 的二分类模型,以及基于决策树和朴素贝叶斯的多类别分类模型
5.1.1 线性模型
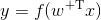
给定输入数据的特征向量和相关的目标值,存在一个权重向量能够最好对数据进行拟合,拟合的过程即最小化模型输出与实际值的误差。这个过程称为模型的拟合、训练或者优化。
具体来说,我们需要找到一个权重向量能够最小化所有训练样本的由损失函数计算出来的损失(误差)之和。损失函数的输入是给定的训练样本的权重向量、特征向量和实际输出,输出是损失。实际上,损失函数也被定义为连接函数,每个分类或者回归函数会有对应的损失函数。
5.1.2 朴素贝叶斯模型
5.1.3 决策树
5.2 从数据中抽取合适的特征
5.3 训练分类模型
5.4 使用分类模型
5.5 评估分类模型的性能
5.6 改进模型性能/参数调优
5.7 小结
MLlib 上常见的 分类模型。
我们用正确的数据格式和数据分布、更多的训练数据、模型参数调优,以及交叉验证对模型能的影响。





