
MongoDB中聚合(aggregate) 操作将来自多个document的value组合在一起,并通过对分组数据进行各种操作处理,并返回计算后的数据结果,主要用于处理数据(诸如统计平均值,求和等)。MongoDB提供三种方式去执行聚合操作:聚合管道(aggregation pipeline)、Map-Reduce函数以及单一的聚合命令(count、distinct、group)。
1. 聚合管道(aggregation pipeline)
1.1聚合管道
聚合管道是由aggregation framework将文档进入一个由多个阶段(stage)组成的管道,可以对每个阶段的管道进行分组、过滤等功能,然后经过一系列的处理,输出相应的聚合结果。如图所示:
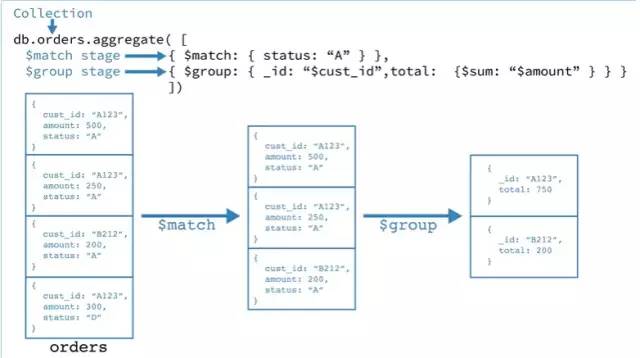
聚合管道操作:
db.orders.aggregate([ { $match: { status: "A" } }, { $group: { _id: "$cust_id", total: { $sum: "$amount" } } }])
$match阶段:通过status字段过滤出符合条件的Document(即是Status等于“A”的Document);
$group 阶段:****按cust_id字段对Document进行分组,以计算每个唯一cust_id的金额总和。
1.2 管道
管道在Unix和Linux中一般用于将当前命令的输出结果作为下一个命令的参数,MongoDB的聚合管道将MongoDB文档在一个管道处理完毕后将结果传递给下一个管道处理。管道操作是可以重复的。
最基本的管道功能提供过滤器filter,其操作类似于查询和文档转换,可以修改输出文档的形式。 其他管道操作提供了按特定字段或字段对文档进行分组和排序的工具,以及用于聚合数组内容(包括文档数组)的工具。 此外,管道阶段可以使用运算符执行任务,例如计算平均值或连接字符串。总结如下:
管道操作符
常用管道
解析
$group
将collection中的document分组,可用于统计结果
$match
过滤数据,只输出符合结果的文档
$project
修改输入文档的结构(例如重命名,增加、删除字段,创建结算结果等)
$sort
将结果进行排序后输出
$limit
限制管道输出的结果个数
$skip
跳过制定数量的结果,并且返回剩下的结果
$unwind
将数组类型的字段进行拆分
表达式操作符
常用表达式
含义
$sum
计算总和,{$sum: 1}表示返回总和×1的值(即总和的数量),使用{$sum: '$制定字段'}也能直接获取制定字段的值的总和
$avg
求平均值
$min
求min值
$max
求max值
$push
将结果文档中插入值到一个数组中
$first
根据文档的排序获取第一个文档数据
$last
同理,获取最后一个数据
为了便于理解,将常见的mongo的聚合操作和MySql的查询做类比:
MongoDB聚合操作
MySql操作/函数
$match
where
$group
group by
$match
having
$project
select
$sort
order by
$limit
limit
$sum
sum()
$lookup
join
1.3 Aggregation Pipeline 优化
聚合管道可以确定它是否仅需要文档中的字段的子集来获得结果。如果是这样,管道将只使用那些必需的字段,减少通过管道的数据量
管道序列优化化
管道序列优化化:
1).使用$projector/$addFields+$match 序列优化:当Aggregation Pipeline中有多个$projectior/$addFields阶段和$match 阶段时,会先执行有依赖的$projector/$addFields阶段,然后会新创建的$match阶段执行,如下,
{ $addFields: { maxTime: { $max: "$times" }, minTime: { $min: "$times" } } }, { $project: { _id: 1, name: 1, times: 1, maxTime: 1, minTime: 1, avgTime: { $avg: ["$maxTime", "$minTime"] } } }, { $match: { name: "Joe Schmoe", maxTime: { $lt: 20 }, minTime: { $gt: 5 }, avgTime: { $gt: 7 } } }
优化执行:
{ $match: { name: "Joe Schmoe" } }, { $addFields: { maxTime: { $max: "$times" }, minTime: { $min: "$times" } } }, { $match: { maxTime: { $lt: 20 }, minTime: { $gt: 5 } } }, { $project: { _id: 1, name: 1, times: 1, maxTime: 1, minTime: 1, avgTime: { $avg: ["$maxTime", "$minTime"] } } }, { $match: { avgTime: { $gt: 7 } } }
2). $sort + $match 以及$project + $skip,当$sort/$project跟在$match/$skip之后时,会先执行$match/$skip后再执行$sort/$project,$sort以达到最小化需排列的对象数,$skip约束,如下:
{ $sort: { age : -1 } }, { $match: { score: 'A' } } { $project: { status: 1, name: 1 } }, { $skip: 5 }
优化执行:
{ $match: { score: 'A' } }, { $sort: { age : -1 } } { $skip: 5 }, { $project: { status: 1, name: 1 } }复制代码
3). $redact+$match序列优化,当$redact后有$match时,可能会新创一个$match阶段进行优化,如下,
{ $redact: { $cond: { if: { $eq: [ "$level", 5 ] }, then: "$$PRUNE", else: "$$DESCEND" } } }, { $match: { year: 2014, category: { $ne: "Z" } } }复制代码
优化执行:
{ $match: { year: 2014 } }, { $redact: { $cond: { if: { $eq: [ "$level", 5 ] }, then: "$$PRUNE", else: "$$DESCEND" } } }, { $match: { year: 2014, category: { $ne: "Z" } } }
还有很多管道序列优化可以查看《官方文档-Aggregation Pipeline Optimization》。
1.4 Aggregation Pipeline以及分片(Sharded)collections
如果管道以$match精确分片 key开始的后,所有管道会在匹配的分片上进行。对于需运行在多分片中的聚合(aggregation)操作,如果不不需要在主分片进行的,这些操作后的结果会路由到随机分片中进行合并结果,避免重载该主分片的数据库。$out和$look阶段必须在主分片数据库运行。
2. Map-Reduce函数
MongoDB还提供map-reduce操作来执行聚合。 通常,map-reduce操作有两个阶段:一个map阶段,它处理每个文档并为每个输入文档发出一个或多个对象,以及reduce阶段组合map操作的输出。 可选地,map-reduce可以具有最终化阶段以对结果进行最终修改。 与其他聚合操作一样,map-reduce可以指定查询条件以选择输入文档以及排序和限制结果。
Map-reduce使用自定义JavaScript函数来执行映射和减少操作,以及可选的finalize操作。 虽然自定义JavaScript与聚合管道相比提供了极大的灵活性,但通常,map-reduce比聚合管道效率更低,更复杂。模式如下:
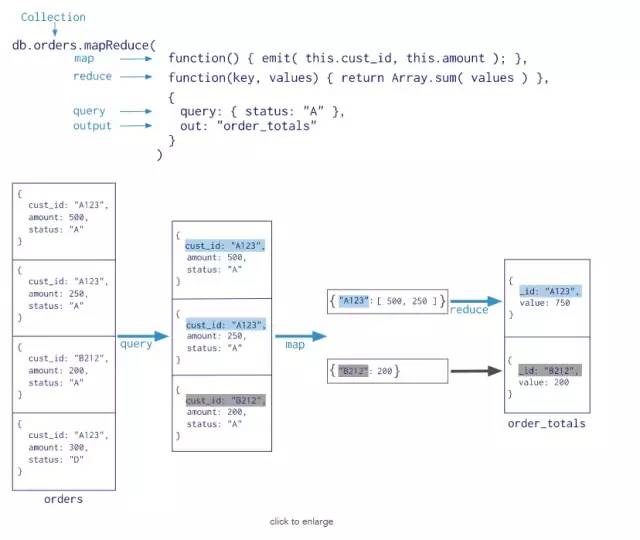
3. 单一的聚合命令
MongoDB还提供了,db.collection.estimatedDocumentCount(),db.collection.count()和db.collection.distinct() 所有这些单一的聚合命令。 虽然这些操作提供了对常见聚合过程的简单访问操作,但它们缺乏聚合管道和map-reduce的灵活性和功能。模型如下
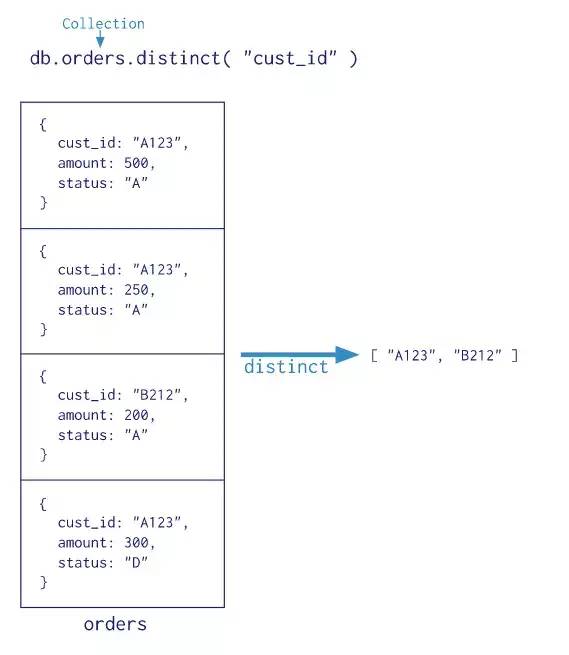
总结
可使用MongoDB中聚合操作用于数据处理,可以适应于一些数据分析等,聚合的典型应用包括销售数据的业务报表,比如将各地区的数据分组后计算销售总和、财务报表等。最后想要更加深入理解还需要自己去实践。
最后可关注公众号,一起学习,每天会分享干货,还有学习视频干货领取!

本文分享自微信公众号 - Ccww技术博客(Ccww-lx)。
如有侵权,请联系 support@oschina.cn 删除。
本文参与“OSC源创计划”,欢迎正在阅读的你也加入,一起分享。











