在 2023 年 Stack Overflow 开发者调查中,Postgres 顶替了 MySQL 被评为最受欢迎的数据库。一个重要因素应该是 Postgres 支持扩展:可扩展的架构+ Postgres 仍然由社区拥有,Postgres 生态近年来蓬勃发展。
扩展可以看作是内置功能,能给数据库增加额外功能。在本文中,我们分享五个可以给你 Postgres 带来 AI 功能的扩展。
pgvector

pgvector 是一个向量相似性搜索工具,专为 Postgres (支持 Postgres 11+) 设计,还可以用于存储嵌入向量。
它在 2021 年就开源了,不过热度在 2023 年开始增加。如果你想用向量数据库,那么其实 Postgres 就可以满足需求了,pgvector 支持:
- 向量与你的其他数据一起存储
- 支持精确和近似最近邻搜索
- L2 距离、内积和余弦距离
- 任何有 Postgres 客户端的语言
如果你用的就是 Postgres,可以直接安装 pgvector,如果你用的是 Postgres 服务或应用程序,其中有些已经内置了pgvector,例如 Aiven, Neon, Supabase, Postgres.app 等。
PostgresML

PostgresML 是个支持将机器学习 (Machine Learning) 模型集成到 Postgres 中的扩展,并在今年 5 月获得了 470 万美元的种子轮。它通过使用 SQL 查询来进行文本和数据的训练和推断,极大地降低了应用程序开发的复杂性。

如果贵司没有复杂的机器学习工作负载(毕竟不是所有人都是人工智能巨头),但还是想构建自己的机器学习模型,可以从新鲜数据中进行学习,这是一个很好的入门方式。
有意思的是,他们组织下还有另一个开源项目:PgCat,是个 PostgreSQL 连接池/代理,于 2022 年 2 月开源,或许 PgCat 不够性感,PostgresML 整体转向了 AI,向量数据库?
MADlib
Apache MADlib 是一个用于 SQL 的大数据机器学习工具。它的代码库最早在 2016 年左右发布到 GitHub,但最初的版本早在 2011 年就已经发布(直至今年还在迭代更新)。

SQL 在处理较大或非结构化数据集上无法很好推理、预测或因果分析的观念已经是过去式了。MADlib 是一个数据库内机器学习库,你可以在存储你数据的数据库 (Postgres) 中进行高级机器学习,包括各种数据分析任务,包括回归和分类。
冷知识:MADlib 的 MAD 代表 Magnetic (磁性), Agile (敏捷) 和 Deep (深度)。

接下来的几个项目还挺有趣的,不过要用的话自担风险😅
pg_embedding

pg_embedding 是 Neon 今年 7 月发布的一个产品,发布的时候称比 pgvector 快 20 倍。不过它使用了 HNSW 索引进行高维相似性搜索,比 pgvector 添加 HNSW 支持要早。
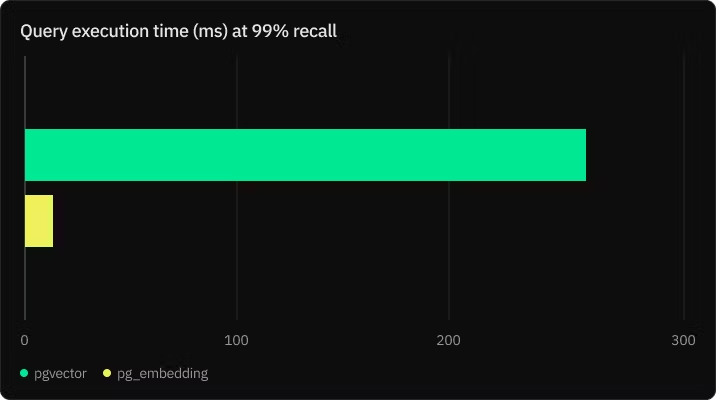
但是几个月后的九月份,他们就加了一条注释,表示不再维护 pg_embedding。看起来是真的没有「购买还是构建」的纠结:使用已有的是显而易见的选择。

pg_gpt

pg_gpt 是个实验性的 Postgres 扩展,它在 Postgres 内部使用 OpenAI 的 GPT API,你可以用自然语言向数据库提问。pg_gpt 背后的组织是 CloudQuery,主业是开源的 ELT 平台。
该插件通过传输部分数据库 schema(不包含数据)的部分发送到 OpenAI GPT API,因此不建议在生产数据库中使用,但如果比如公开的 schema,那可以试试这个工具。例如,如果想查找过去一个月在 Hacker News 上提到 Sam Altman 的热门提交,这是一种方法(当然也可以直接用 Search Hacker News 🤣)。
总结
今年我们见证了科技界拥抱人工智能,并在 AI 领域里找到自己的立足之地。幸好 Postgres 足够开放,支持扩展,我们有幸得以享用想这些扩展,可以为我们的 Postgres 添加 AI 功能,而无需迁移到新的数据库。
💡 更多资讯,请关注 Bytebase 公号:Bytebase